
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称
爬取当当网新书排行榜数据分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取新书书名和价格、折扣

3.主题式网络爬虫设计方案概述
设计框架合理使用工具爬取信息
二、主题页面的结构特征分析
1.主题页面的结构与特征分析

2.Htmls页面解析
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
#导入numpy库
import numpy as np
#导入matplotlib库
import matplotlib.pyplot as plt
import matplotlib as mpl
#导入最小二乘法
from scipy.optimize import leastsq
#导入requests库
import requests
#导入BeautifulSoup库
from bs4 import BeautifulSoup
#导入pandas库
import pandas as pd
#导入CSV库
import csv
#导入jieba库
import jieba
#导入wordcloud库
import wordcloud
#网页结构
def constitute(soup):
#显示完整网页结构
print(soup.prettify())
#查看网站的标题
print("所有的标题:",soup.select("title"))
#查看网站的id=link1后的所有兄弟节点标签
print("id=link1后的所有兄弟节点标签:",soup.select("body a"))
#查看a标签,其类属性为sister的标签
print("a标签,其类属性为sister的标签:",soup.select("#link1 ~.sister"))
#查看a标签中具有href属性的标签
print("a标签中具有href属性的标签:",soup.select('a[href]'))
#查看a标签中的父节点
print("a标签中的父节点:",soup.a.parent)
#查看p标签中的子节点
print("p标签中的子节点:",soup.p.children)
#数据采集
def data_collcation(soup,bookname,recommendindex,price,discount):
#发现在网页结构中书名保存在“class=”name“中,索引标签爬取信息
for i in soup.find_all(class_="name"):
bookname.append(i.get_text().strip())
#发现在网页结构中推荐指数保存在“class=”tuijian“中,索引标签爬取信息
for j in soup.find_all(class_="tuijian"):
recommendindex.append(j.get_text().strip())
#发现在网页结构中购买价格保存在“class=”price_r“中,索引标签爬取信息
for k in soup.find_all(class_="price_r"):
price.append(k.get_text().strip())
#发现在网页结构中购买折扣保存在“class=”price_s“中,索引标签爬取信息
for l in soup.find_all(class_="price_s"):
discount.append(l.get_text().strip())
#写入数据
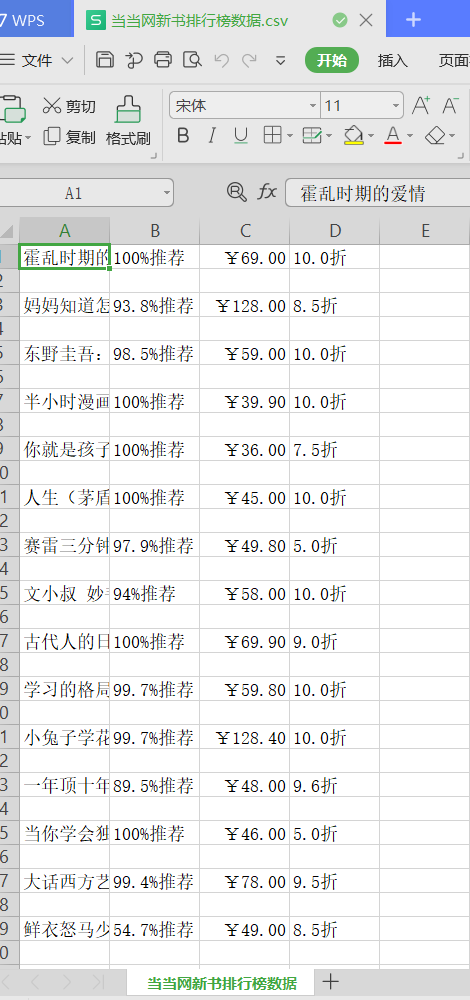
def csv_fi(v):
#把文件转换成二维表
data=np.array(v.T)
csv_1=open("C:\python\\当当网新书排行榜数据.csv",\
"w",\
encoding="utf-8")
#把二维表写入CSV文件中
writer=csv.writer(csv_1)
for i in data:
writer.writerow(i)
#关闭文件
csv_1.close()
#数据清洗
def dataclear():
data_2=pd.read_csv("C:\python\\当当网新书排行榜数据.csv",\
names=["书名","推荐指数","购买价格","购买折扣"])
#查看文件
print(data_2)
try:
#查找是否有空值
print(data_2.isnull().value_counts())
#把空值都变为零
data_2.fillna(0)
except:
print("没有空值")
try:
#查看重复值
print(data_2.duplicated())
#删除重复值
data_2.drop_duolicated()
except:
print("没有重复值")
try:
#查看异常值
print(data_2.describe())
except:
print("无法查看异常值")
#再次查看数据
print(data_2)
#穿件空列表
recommendindex2=[]
price2=[]
discount2=[]
#删除“推荐指数”中不需要的文字
for i in data_2["推荐指数"]:
recommendindex=i.strip('%推荐')
recommendindex2.append(recommendindex)
#删除“购买价格”中不需要的符号
for j in data_2["购买价格"]:
price=j.strip('¥')
price2.append(price)
#删除“购买折扣”中不需要的文字
for k in data_2["购买折扣"]:
discount=k.strip('折')
discount2.append(discount)
bookname2=np.array(data_2["书名"])
#整合新数据
newdata=[bookname2,recommendindex2,price2,discount2]
#设置数据标题
index2=["书名","推荐指数","购买价格","购买折扣"]
#把数据用DataFrame转变成一个二维列表
v2=pd.DataFrame(newdata,index2)
v3=v2.T
#打开创建好的文件
csv_2=open("C:\python\\当当网新书排行榜清洗数据.csv",\
"w",\
encoding="utf-8")
headers=["书名","推荐指数","购买价格","购买折扣"]
#把清洗好的数据写入CSV文档中
v3.to_csv(csv_2,\
header=headers,\
index=False,\
mode="a+")
#关闭文件
csv_2.close()
#把书名写入一个txt文档为了方便进行文档分析
def txt_new(bookname):
fi=open("C:\python\\当当网新书书名.txt",\
"w",\
encoding="utf-8")
#把书名一行行的写进文档中
for p in bookname:
fi.write("".join(p)+"\n")
#关闭文件
fi.close()
#文本分析
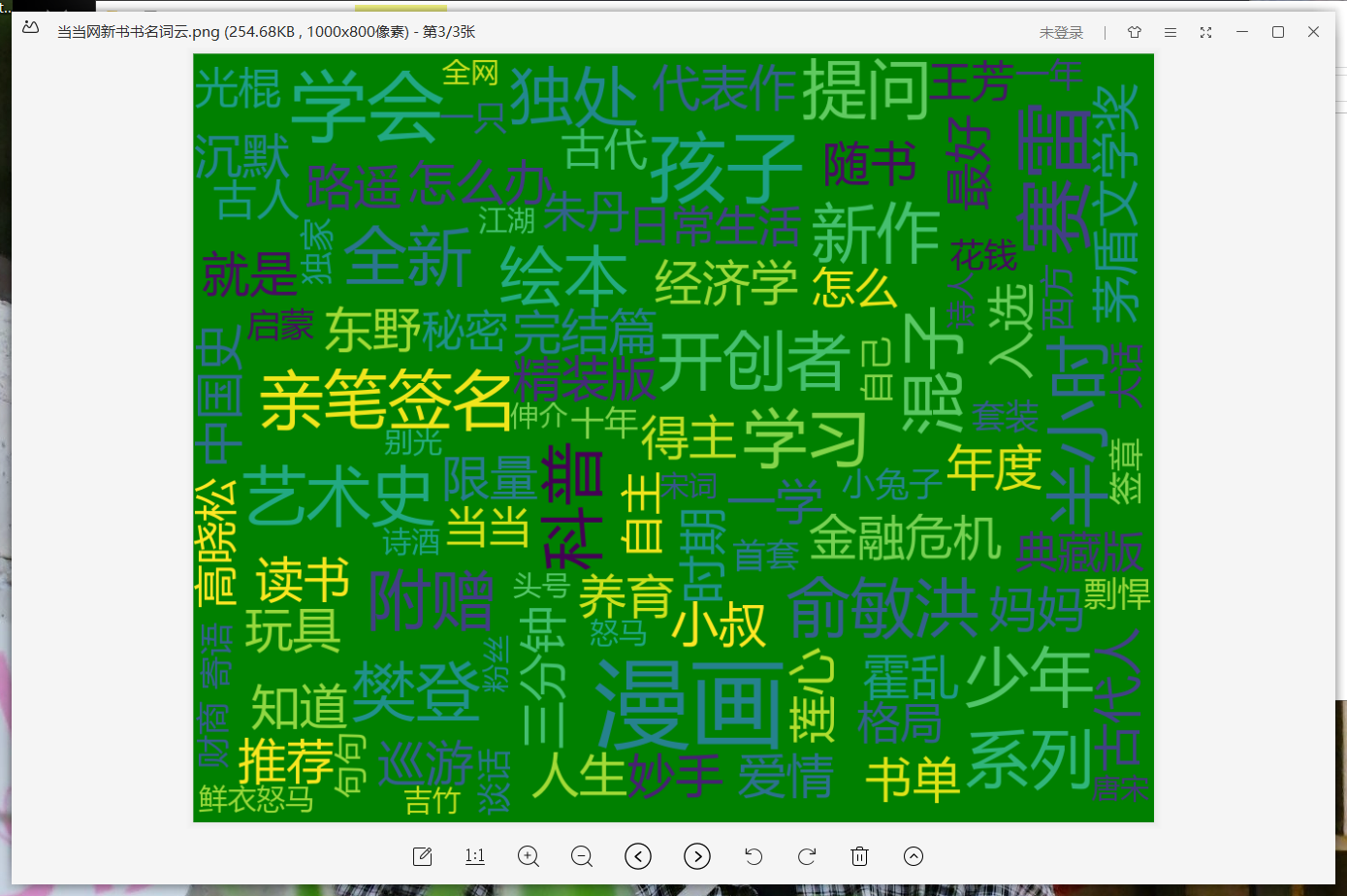
def cloud():
#打开之前保存的文本txt
txt=open("C:\python\\当当网新书书名.txt","rb").read()
#解码
txt_1=txt.decode()
#把txt文本中的特殊符号换成空格
for ch in ':...()“”、?!・,':
txt_1=txt_1.replace(ch," ")
#对文本进行分词
txt_2=jieba.lcut(txt_1)
print(txt_2)
#设置词云的参数
w=wordcloud.WordCloud(width=1000,\
height=800,\
font_path="msyh.ttc",\
min_font_size=30,\
max_font_size=100,\
font_step=5,\
background_color="green")
#把文本的内容进行分词,并生成词云
w.generate(" ".join(txt_2))
#保存到本地
w.to_file("C:\python\\当当网新书书名词云.png")
#数据可视化
def drawing():
#打开清洗好的数据
data=pd.read_csv("C:\python\\当当网新书排行榜清洗数据.csv")
#读取数据
X=np.array(data.loc[:,"书名"])
Y1=np.array(data.loc[:,"推荐指数"])
Y2=np.array(data.loc[:,"购买价格"])
Y3=np.array(data.loc[:,"购买折扣"])
#设计画布的大小
plt.figure(figsize=(20,10))
#设置画布的位置
plt.subplot(2,2,1)
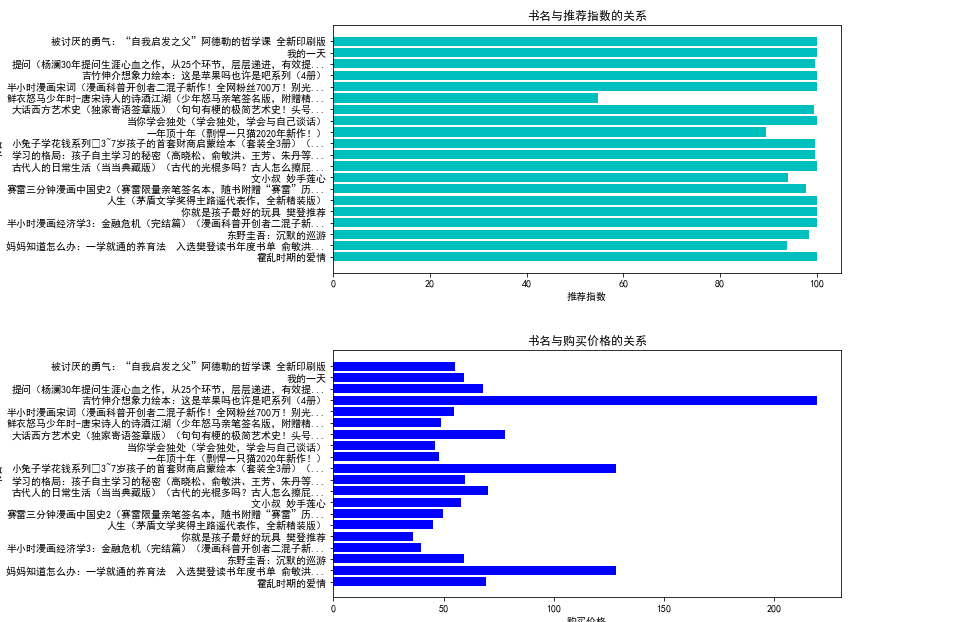
#绘制“书名”和“推荐指数”的条形图
plt.barh(X,\
Y1,\
align="center",\
color="c")
#设置标题
plt.title("书名与推荐指数的关系")
#设置x轴的标题
plt.xlabel("推荐指数")
#设置y轴的标题
plt.ylabel("书名")
#展示条形图
plt.show()
#设置画布大小
plt.figure(figsize=(20,10))
#设置画布位置
plt.subplot(2,2,2)
#绘制“书名”和“购买价格”的条形图
plt.barh(X,\
Y2,\
align="center",\
color="blue")
#设置总标题
plt.title("书名与购买价格的关系")
#设置x轴的标题
plt.xlabel("购买价格")
#设置y轴的标题
plt.ylabel("书名")
#展示条形图
plt.show()
#设置画布大小
plt.figure(figsize=(20,10))
#设置画布位置
plt.subplot(2,1,2)
#绘制“书名”和“购买折扣”的条形图
plt.barh(X,\
Y3,\
align="center",\
color="orange")
#设置总标题
plt.title("书名与购买折扣的关系")
#设置x轴标题
plt.xlabel("购买折扣")
#设置y轴标题
plt.ylabel("书名")
#展示条形图
plt.show()
def Regressionanalysis():
#打开清洗好的数据
data=pd.read_csv("C:\python\\当当网新书排行榜清洗数据.csv")
#读取数据
X=np.array(data.loc[:,"书名"])
Y1=np.array(data.loc[:,"推荐指数"])
Y1.sort()
Y2=np.array(data.loc[:,"购买价格"])
Y2.sort()
Y3=np.array(data.loc[:,"购买折扣"])
Y3.sort()
#设置计酸最小二乘法的函数
def fit_func(p,x):
a,b,c=p
return a*x*x+b*x+c
def error_func(p,x,y):
return fit_func(p,x)-y
#设置初始值
p0=[1,2,3]
#使用leastsq计算最小二乘法
para=leastsq(error_func,p0,args=(Y1,Y2))
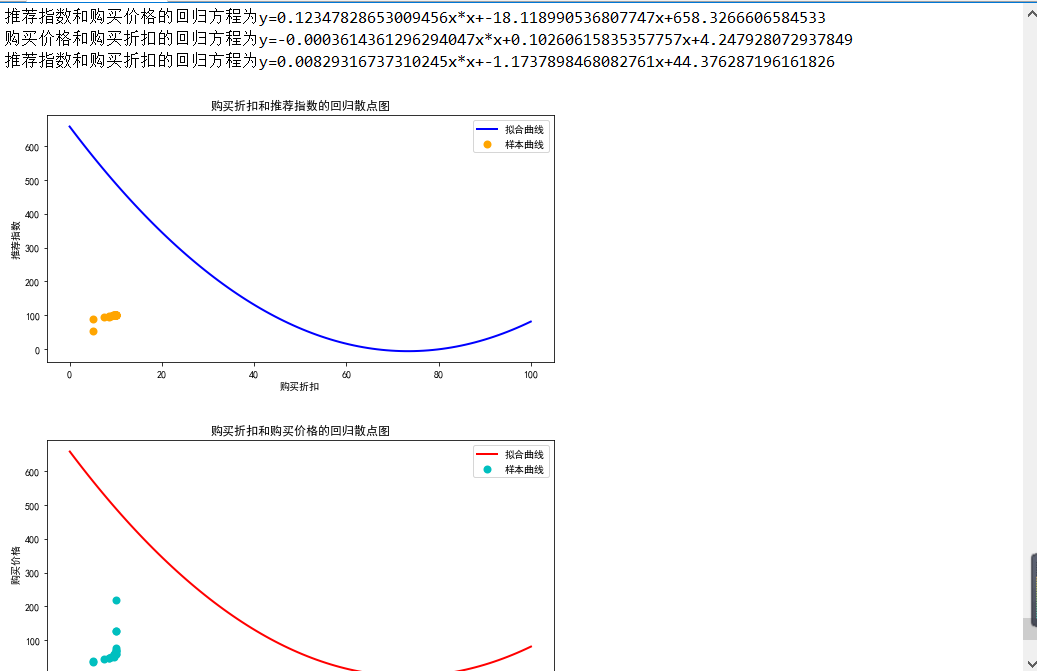
#描写回归方程
a,b,c=para[0]
print('推荐指数和购买价格的回归方程为y={0}x*x+{1}x+{2}'.format(a,b,c))
#设置初始值
p0_2=[1,2,3]
#使用leastsq计算最小二乘法
para_2=leastsq(error_func,p0_2,args=(Y2,Y3))
#描写回归方程
a2,b2,c2=para_2[0]
print('购买价格和购买折扣的回归方程为y={0}x*x+{1}x+{2}'.format(a2,b2,c2))
#设置初始值
p0_3=[1,2,3]
#使用leastsq计算最小二乘法
para_3=leastsq(error_func,p0_3,args=(Y1,Y3))
#描写回归方程
a3,b3,c3=para_3[0]
print('推荐指数和购买折扣的回归方程为y={0}x*x+{1}x+{2}'.format(a3,b3,c3))
#绘制购买折扣和推荐指数的回归散点图
plt.figure(figsize=(20,10))
#设置画布位置
plt.subplot(2,2,1)
#设置样本曲线参数
plt.scatter(Y3,\
Y1,\
color="orange",\
label="样本曲线",\
lw=2)
#设置拟合曲线参数
X1=np.linspace(0,100,100)
Y1=a*X1*X1+b*X1+c
plt.plot(X1,Y1,\
color="blue",\
lw=2,\
label="拟合曲线")
#展示图像
plt.xlabel("购买折扣")
plt.ylabel("推荐指数")
plt.title("购买折扣和推荐指数的回归散点图")
plt.legend()
plt.show()
#绘制购买折扣和购买价格的回归散点图
plt.figure(figsize=(20,10))
#设置画布位置
plt.subplot(2,2,2)
#设置样本曲线参数
plt.scatter(Y3,\
Y2,\
color="c",\
label="样本曲线",\
lw=2)
#设置拟合曲线参数
X1=np.linspace(0,100,100)
Y1=a*X1*X1+b*X1+c
plt.plot(X1,\
Y1,\
color="r",\
lw=2,\
label="拟合曲线")
#展示图像
plt.xlabel("购买折扣")
plt.ylabel("购买价格")
plt.title("购买折扣和购买价格的回归散点图")
plt.legend()
plt.show()
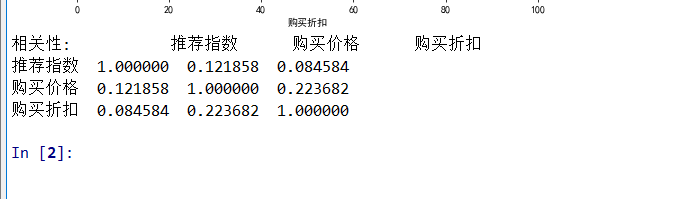
#相关性计算
Corre=data.corr()
print("相关性:",Corre)
#主程序
def main():
#爬取的目的网站
url="http://bang.dangdang.com/books/newhotsales/01.00.00.00.00.00-recent7-0-0-1-1"
#获取网站
html=requests.get(url)
#读取网站文本信息
r=html.text
#把网站编程HTMLL结构
soup=BeautifulSoup(r,"lxml")
#查看网页结构
constitute(soup=soup)
#建立空列表,保存信息
bookname=[]
recommendindex=[]
price=[]
discount=[]
#采集数据
data_collcation(soup,bookname,recommendindex,price,discount)
#设置标题
index=["书名","推荐指数","购买价格","购买折扣"]
#整合数据
data=[bookname,recommendindex,price,discount]
#把数据变成一个二维列表
v=pd.DataFrame(data,index)
print(v.T)
#把采集的数据写入csv文件中
csv_fi(v)
#清洗数据并保存到一个新的csv文件
dataclear()
#把书名写入文档
txt_new(bookname)
#生成词云
cloud()
#设置matplotilb参数
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
mpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
#数据可视化
drawing()
#回归分析
Regressionanalysis()
#启动主程序
main()




四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
理解网络爬虫的技巧,知道数据分析的重要性
2.对本次程序设计任务完成的情况做一个简单的小结。
熟练的运用编程函数是很重要的事情

