


以前的神经网络几乎都是部署在云端(服务器上),设备端采集到数据通过网络发送给服务器做inference(推理),结果再通过网络返回给设备端。如今越来越多的神经网络部署在嵌入式设备端上,即inference在设备端上做。嵌入式设备的特点是算力不强、memory小。可以通过对神经网络做量化来降load和省memory,但有时可能memory还吃紧,就需要对神经网络在memory使用上做进一步优化。本文就以一维卷积神经网络为例谈谈怎么来进一步优化卷积神经网络使用的memory。
文章(卷积神经网络中一维卷积的计算过程 )讲了卷积神经网络一维卷积的处理过程,可以看出卷积层的输入是一个大矩阵,输出也是一个大矩阵,保存这些矩阵是挺耗memory的。其实做卷积计算时,每次都是从输入中取出kernel size大小的数据与kernel做卷积运算,得到的是一个值,保存在卷积层的输出buffer里,输出也是下一层的输入。如果输入是卷积层kernel的大小(即是能做运算的最小size),输出是下一层的能做运算的最小size,相对于整个输入和输出的size而言,能节省不少memory。下面就讲讲怎么用这种思路来做CNN的memory优化。
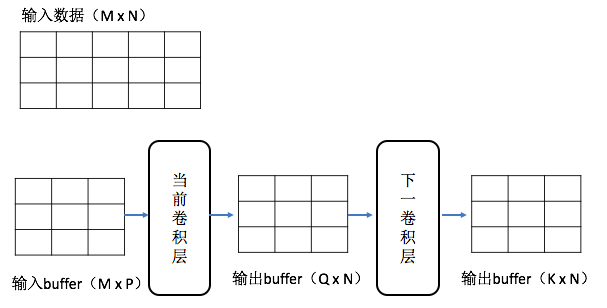
假设当前层和下一层均为卷积层,stride为1,padding模式为same。当前层的输入是一个MxN的矩阵,kernel size是P,kernel count是Q,所以kernel是一个MxP的矩阵,当前层的输出是一个QxN矩阵。当前卷积层的输出就是下一卷积层的输入。下一卷积层的kernel size是J,kernel count是K,所以下一卷积层的kernel是一个QxJ的矩阵,输出是一个KxN的矩阵。示意如下图:
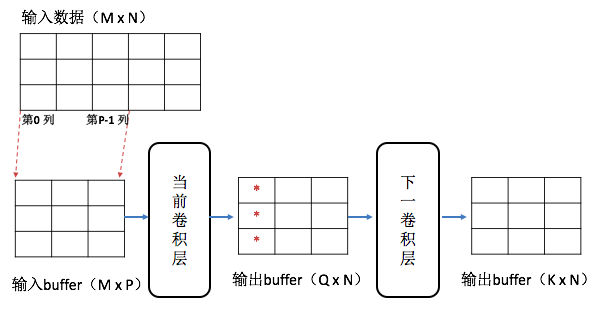
首先从输入矩阵中取出0~(P-1)列(共P列)放进输入buffer中,正好放满。与第一个kernel做卷积运算就得到一个值放进输出buffer中(0,0)位置。同样与第二个kernel做卷积得到的值放在输出buffer中(1,0)位置,与所有kernel做完卷积后得到是一个Q行1列的矩阵,放在输出buffer第一列上,如下图:
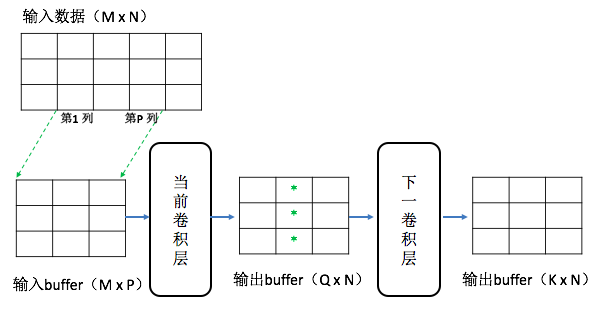
再将输入矩阵的第1~P列取出放进输入buffer中(即把输入buffer中每列向前移一格,0列移出buffer,第P列放在最后1列),同上面一样计算,得到的依旧是1列数值放进输出buffer的第2列中。如下图:
依次这么做下去,当输出buffer里的最后一列被填满时,就要触发下一卷积层做卷积运算,与K个kernel卷积运算后得到的是一个K行1列的值放进下一卷积层输出buffer的第一列中。如下图:
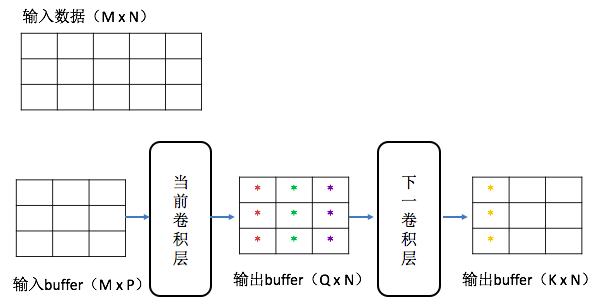
由于下一卷积层的输出buffer未满,不能触发后面的运算。又回到从输入矩阵中取数据放进当前卷积层的输入buffer中,再进行当前卷积层和下一卷积层的运算,结果放在各自的输出buffer里(如输出buffer满了就要把每列左移一格,0列移出buffer,新生成的1列数据放在最后1列)。类似的处理,直到把输入矩阵中取到最后一列,再把各个层的输入buffer全处理完,最后得到结果。
从上面的思路看出,输入和输出buffer从大矩阵变成kernel大小的小矩阵可以省不少memory。具体软件实现时,有输入层,中间各层(包括卷积层等),每一层为一个整体,要用event机制去触发下一个要处理的层。当一层处理完后要判断下一步是哪一层做处理(有可能是下一层,也有可能是当前层或上一层,还有可能是输入层等),就给那一层发event,那一层收到event后就会继续处理。示意如下图:
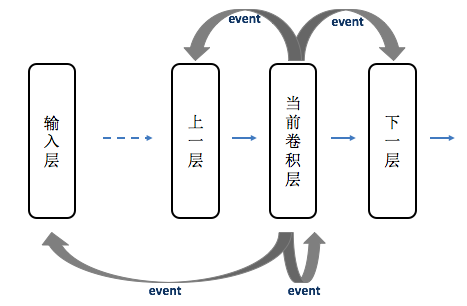
软件实现时还有很多细节要处理,尤其是当输入层数据取完后后面各层的处理,这里就不一一细述了。软件调试时先用不省memory的原始code生成每层的输出,保存在各自的文件里,用于做比特校验。然后对省memory的code进行调试,先从第一层开始,一层一层的调试。优化后的代码每层的输出跟优化前的输出是完全一样的才算调试完成。
为了更好的跟大家沟通,互帮互助,我建了一个讨论群。如您有兴趣,请搜weixin号 david_tym ,共同交流。谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号