实时数仓
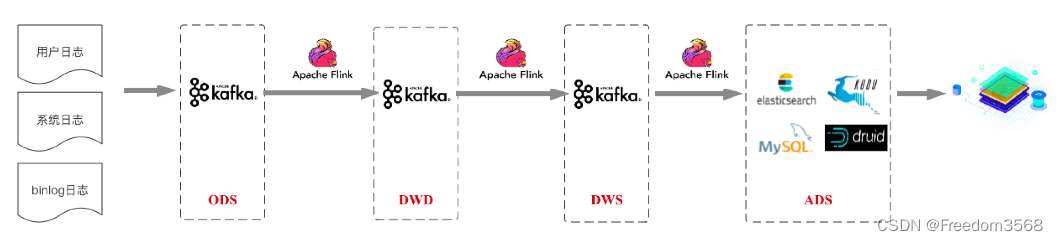
这张图片展示的是一个典型的实时数仓分层架构,它基于流式处理技术,将各种数据源经过逐层处理,最终形成可供查询分析的数据产品。
架构分层解释
-
ODS (Operational Data Store) - 原始数据层:这是数据流的入口。它直接从各种数据源(如用户日志、系统日志、binlog日志)采集原始数据,然后将它们无处理地写入 Kafka。这层的作用是做数据缓冲,将原始数据集中存储,方便后续处理,也避免了对源系统造成压力。
-
DWD (Data Warehouse Detail) - 数据明细层:在这层,数据流经 Apache Flink 进行初步清洗和标准化。例如,去除脏数据、统一字段格式、补充维度信息等。处理后的数据再写回 Kafka。这层的作用是把原始的、杂乱的数据转化为干净、规范的明细数据。
-
DWS (Data Warehouse Summary) - 数据汇总层:这是最关键的一层。Apache Flink 会对DWD层的数据进行复杂的实时聚合计算。例如,计算每小时的网站 PV/UV、每个用户的总消费金额等。聚合后的数据同样写入 Kafka,以供下一层使用。这层的作用是把明细数据转化为有业务价值的汇总数据。
-
ADS (Application Data Store) - 应用数据层:这是面向最终应用的存储层。DWS层计算出的汇总结果会写入不同的存储系统,如 Elasticsearch、MySQL、Apache Druid。这些存储系统根据不同的查询场景进行选择,比如用 Druid 进行高维分析,用 Elasticsearch 进行全文检索,用 MySQL 支撑事务性查询。最终,这些存储系统会为前端应用(如数据看板、用户列表)提供高速查询服务。
实际案例:电商用户行为列表页面
假设你正在做一个电商平台的后台管理系统,其中有一个“用户行为分析列表”,需要实时展示每个用户的最新行为、总消费额、浏览商品数等指标。
-
ODS 层:
- 数据源: 用户的浏览、点击、购买等行为日志,以及数据库的 binlog 日志(记录用户的消费金额、订单状态变更等)。
- 流程: 所有这些原始日志数据被实时采集并写入一个或多个 Kafka Topic。
-
DWD 层:
- 数据清洗: Apache Flink 从 Kafka 读取原始日志。它可能会清洗掉机器人产生的无效访问日志,标准化时间戳格式,或者将不同的日志类型(浏览、点击)统一为一个格式。
- 结果: 清洗后的用户行为明细数据被写入另一个 Kafka Topic。
-
DWS 层:
- 实时聚合: Apache Flink 从DWD层的 Kafka Topic 读取明细数据。它会实时计算以下指标:
- 总消费额: 监听 binlog 数据,对每个用户的消费金额进行累加。
- 浏览商品数: 对每个用户的浏览日志进行计数。
- 最近访问时间: 记录每个用户的最新访问时间。
- 结果: 实时聚合后的结果(例如:
{user_id: 123, total_purchase: 1200, viewed_items: 50, last_visit_time: "..."})被写入 Kafka。
- 实时聚合: Apache Flink 从DWD层的 Kafka Topic 读取明细数据。它会实时计算以下指标:
-
ADS 层:
- 存储: Flink 将DWS层计算好的结果写入一个分析型数据库,比如 Apache Druid。Druid 专门为这种高维聚合数据设计,能提供毫秒级的查询响应。
- 列表页面: 当管理员打开“用户行为分析列表”页面时,前端直接向后端发起查询。后端服务只需对Druid发起一个简单的查询请求:“查询所有用户的总消费额和浏览商品数”,而无需进行任何复杂的联合查询或计算。
通过这个架构,即使数据量非常庞大,列表页面的加载速度也极快,因为所有耗时的计算已经在数据流入时就完成了,查询时直接读取结果即可。这完美解决了“不能有缓存但又要高效”的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号