


第四次大作业数据采集
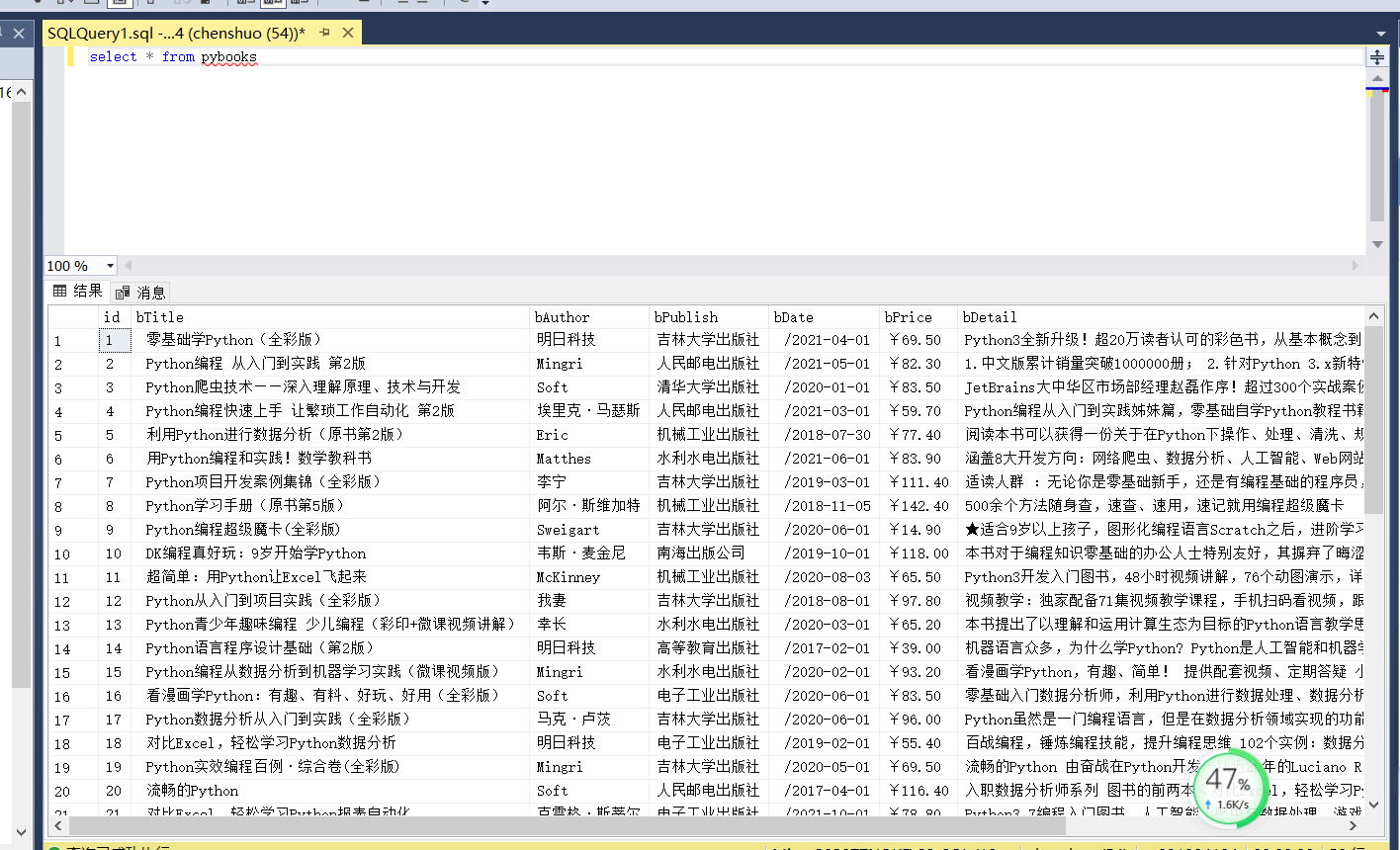
作业1 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据 候选网站:http://search.dangdang.com/?key=python&act=input 关键词:学生可自由选择 输出信息:MySQL的输出信息如下 作业1代码链接:https://gitee.com/chenshuooooo/data-acquisition/tree/master/%E4%BD%9C%E4%B8%9A4/exp4_1
作业1代码链接:https://gitee.com/chenshuooooo/data-acquisition/tree/master/%E4%BD%9C%E4%B8%9A4/exp4_1
编写item
import scrapy class Exp41Item(scrapy.Item): bTitle = scrapy.Field() bAuthor = scrapy.Field() bPublisher = scrapy.Field() bDate = scrapy.Field() bPrice = scrapy.Field() bDetail = scrapy.Field() pass
编写setting
BOT_NAME = 'exp4' SPIDER_MODULES = ['exp4_1.spiders'] NEWSPIDER_MODULE = 'exp4_1.spiders'ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'exp4_1.pipelines.Exp41Pipeline': 300,
}
编写dangdang.py爬虫主程序,爬取python书籍的价格,作者等信息
import scrapy
from exp4_1.items import Exp41Item
class DangdangSpider(scrapy.Spider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&act=input']
def parse(self, response):
item = Exp41Item()
i = 0
titles = response.xpath("//div[@class='con shoplist']/div/ul/li/a/@title").extract()
author = response.xpath("//div[@class='con shoplist']/div/ul/li/p[@class='search_book_author']/span/a[@dd_name='单品作者']/text()").extract()
publisher = response.xpath("//div[@class='con shoplist']/div/ul/li/p[@class='search_book_author']/span/a[@dd_name='单品出版社']/@title").extract()
while i < 60:
date = response.xpath("//div[@class='con shoplist']/div/ul/li/p[@class='search_book_author']/span[2]")
date = date.xpath('./text()').extract()
i += 1
price = response.xpath(
"//div[@class='con shoplist']/div/ul/li/p[@class='price']/span[@class='search_now_price']/text()").extract()
detail = response.xpath("//div[@class='con shoplist']/div/ul/li/p[@class='detail']/text()").extract()
item['bTitle'] = titles
item['bAuthor'] = author
item['bPublisher'] = publisher
item['bDate'] = date
item['bPrice'] = price
item['bDetail'] = detail
yield item
pass
4)编写pipeline管道类,实现数据库的存储
import pymssql
class Exp41Pipeline:
def process_item(self, item, spider):
count=0
connect = pymssql.connect(host='localhost', user='chenshuo', password='cs031904104',
database='cs031904104', charset='UTF-8') # 连接到sql server数据库
cur = connect.cursor() # 创建操作游标
# 创建表结构
cur.execute(
"create table pybooks"
" (id int,bTitle char(1000),bAuthor char(1000),bPublish char(1000),bDate char(1000),bPrice char(1000),bDetail char(1000) )")
# 插入数据
while count<50:
try:
cur.execute(
"insert into pybooks (id,bTitle,bAuthor,bPublish,bDate,bPrice,bDetail) values ('%d','%s','%s','%s','%s','%s','%s')" % (
count + 1, item['bTitle'][count].replace("'", "''"), item['bAuthor'][count].replace("'", "''"),
item['bPublisher'][count].replace("'", "''"), item['bDate'][count].replace("'", "''"),
item['bPrice'][count].replace("'", "''"), item['bDetail'][count].replace("'", "''")))
connect.commit() # 提交命令
count += 1
except Exception as ex:
print(ex)
connect.close()#关闭与数据库的连接
return item
(5)编写run.py程序,模拟命令行运行爬虫项目
# -*- coding:utf-8 -*-
from scrapy import cmdline
import sys
sys.path.append(r'D:\python project\exp4_1\spiders\dangdang')#添加爬虫路径,防止报错找不到路径
cmdline.execute('scrapy crawl dangdang'.split())#运行爬虫
作业2
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/

实现过程
作业②代码链接:https://gitee.com/chenshuooooo/data-acquisition/tree/master/%E4%BD%9C%E4%B8%9A4/exp4_2
(1)分析页面,发现要爬取的数据都在tr下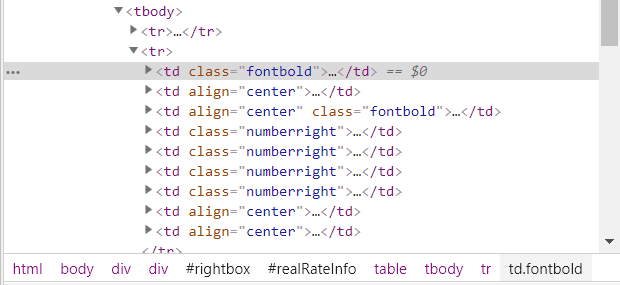
编写item
import scrapy
class Exp42Item(scrapy.Item):
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Times = scrapy.Field()
Id = scrapy.Field()
pass
编写setting
SPIDER_MODULES = ['exp4_2.spiders'] NEWSPIDER_MODULE = 'exp4_2.spiders'ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'exp4_2.pipelines.Exp42Pipeline': 300,
}
编写work2爬虫主程序
# -*- coding:utf-8 -*- import scrapy from parsel import selectorfrom exp4_2.items import Exp42Item
class Work2Spiders(scrapy.Spider):
name = 'work2spider'
start_urls = ['http://fx.cmbchina.com/hq/']
def parse(self, response):
item = Exp42Item()
cont=1
trs = response.xpath("//table[@class='data']//tr") # 获取表格的所有行
for tr in trs[1:]:
Currency = tr.xpath("./td[1]/text()").extract_first().strip()
TSP = tr.xpath("./td[4]/text()").extract_first().strip()
CSP = tr.xpath("./td[5]/text()").extract_first().strip()
TBP = tr.xpath("./td[6]/text()").extract_first().strip()
CBP = tr.xpath("./td[7]/text()").extract_first().strip()
Time = tr.xpath("./td[8]/text()").extract_first().strip()
item['Currency']=Currency
item['TSP'] = TSP
item['CSP'] = CSP
item['TBP'] = TBP
item['CBP'] = CBP
item['Times'] = Time
item['Id'] = cont
cont+=1
yield item
pass
编写pipeline管道输出类
import pymssql
class Exp42Pipeline:
def process_item(self, item, spider):
print("{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}\t".format
(item["Id"],item["Currency"],item["TSP"],
item["CSP"],item["TBP"],item["CBP"],item["Times"]))
connect = pymssql.connect(host='localhost', user='chenshuo', password='cs031904104',
database='cs031904104', charset='UTF-8') # 连接到sql server数据库
cur = connect.cursor() # 创建操作游标
#表的创建在数据库中完成
# 插入数据
try:
cur.execute(
"insert into rate_cs (id,Currency,TSP,CSP,TBP,CBP,Times) values ('%d','%s','%s','%s','%s','%s','%s')" % (
item['Id'], item['Currency'].replace("'", "''"), item['TSP'].replace("'", "''"),
item['CSP'].replace("'", "''"), item['TBP'].replace("'", "''"),
item['CBP'].replace("'", "''"), item['Times'].replace("'", "''")))
connect.commit() # 提交命令
except Exception as er:
print(er)
connect.close()#关闭与数据库的连接
return item
编写run.py文件模拟命令行运行爬虫
# -*- coding:utf-8 -*-
from scrapy import cmdline
import sys
sys.path.append(r'D:\python project\exp4_2\spiders\work2spider')#添加爬虫路径,防止报错找不到路径
cmdline.execute('scrapy crawl work2spider'.split())#运行爬虫
爬取结果展示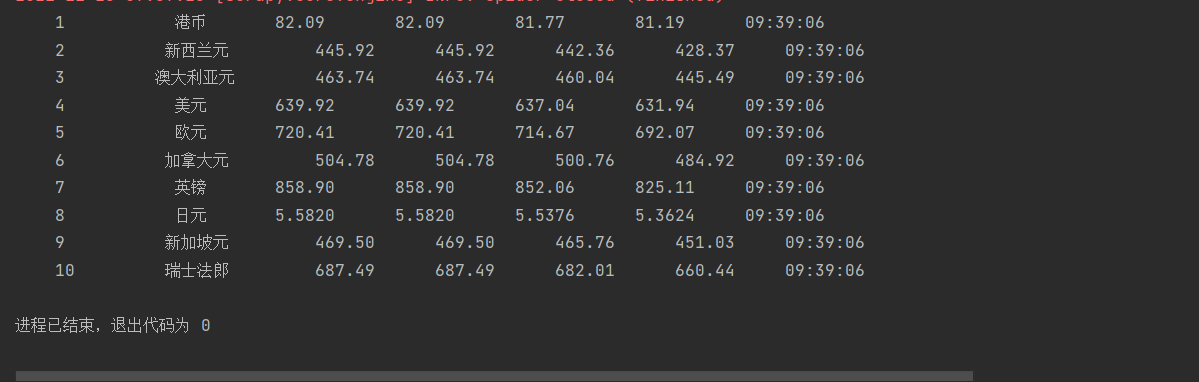
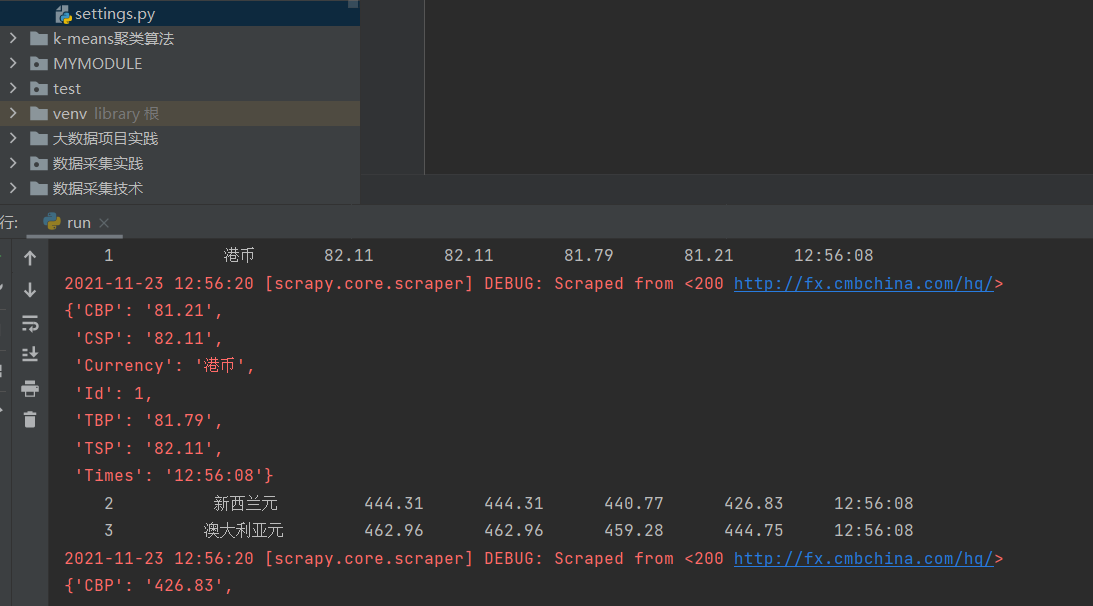
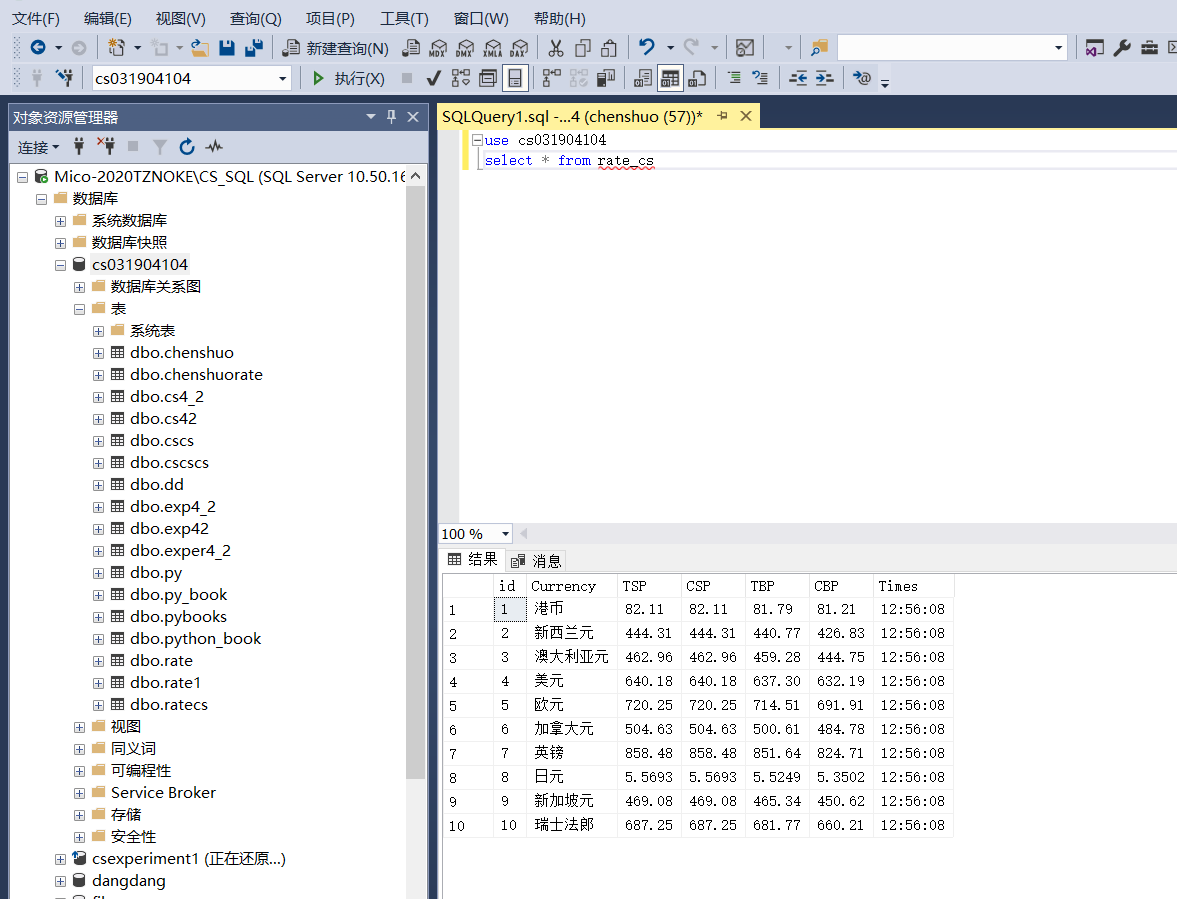
作业3要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
实现过程
作业③代码连接:https://gitee.com/chenshuooooo/data-acquisition/tree/master/%E4%BD%9C%E4%B8%9A4/dongfang_spider
(1)分析页面,发现要爬取的信息都在tbody下的td结点
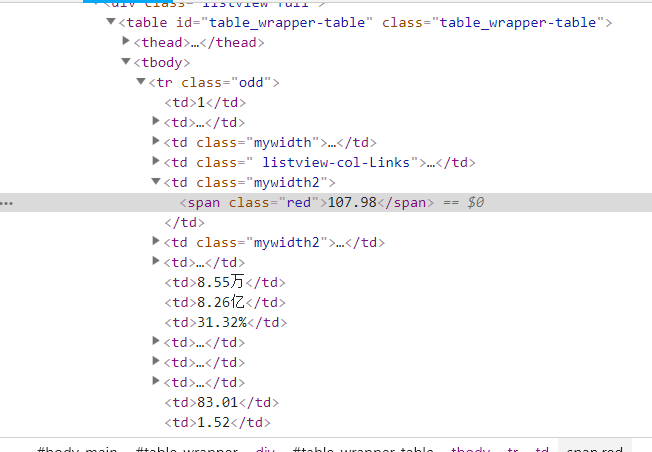
爬取td的相应股票信息
selector = scrapy.Selector(text=data) ##selector选择器
##先获取一个页面下所有tr标签
trs = selector.xpath(
"/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-
main']/div[@id='table_wrapper']/div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
##获取tr标签下的对应信息提交给item
for tr in trs :
id = tr.xpath('./td[1]/text()').extract()#股票序列
bStockNo = tr.xpath('./td[2]/a/text()').extract()#股票id
bName = tr.xpath('./td[3]/a/text()').extract()#股票名称
bLatestquo = tr.xpath('./td[5]/span/text()').extract()#股票最新价
bFluctuation = tr.xpath('./td[6]/span/text()').extract()#涨跌幅
bTurnovernum = tr.xpath('./td[8]/text()').extract()#涨跌额
bTurnoveprice = tr.xpath('./td[9]/text()').extract()
bAmplitude = tr.xpath('./td[10]/text()').extract()#
bHighest = tr.xpath('./td[11]/span/text()').extract()#最高
bLowest = tr.xpath('./td[12]/span/text()').extract()#最低
bToday = tr.xpath('./td[13]/span/text()').extract()#今开
bYesterday = tr.xpath('./td[14]/text()').extract()#昨收
编写setting类
BOT_NAME = 'dongfangcaifu_spider'
SPIDER_MODULES = ['dongfangcaifu_spider.spiders']
NEWSPIDER_MODULE = 'dongfangcaifu_spider.spiders'
FEED_EXPORT_ENCODING = 'gb18030'#设置编码方式
ITEM_PIPELINES = { #设置管道优先级
'dongfangcaifu_spider.pipelines.DongfangcaifuSpiderPipeline': 300,
}
DOWNLOADER_MIDDLEWARES = {
#设置中间件优先级
'dongfangcaifu_spider.middlewares.DongfangcaifuSpiderDownloaderMiddleware': 543,
}
ROBOTSTXT_OBEY = False
编写middlewares类
class DongfangSpiderDownloaderMiddleware:
def __init__(self):
self.driver = webdriver.Chrome()##启动浏览器
def process_request(self, request, spider):
global sum
sum += 1
self.driver.get(request.url)##爬虫文件request的url
time.sleep(2)##睡眠2秒,没有这个时间可能会导致找不到页面
url = self.driver.current_url
input=self.driver.find_element_by_xpath(
"/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-
main']/div[@id='table_wrapper']/div[@class='listview full']/div[@class='dataTables_wrapper']/div[@id='main-
table_paginate']/input[@class='paginate_input']")
##找到确定跳转按钮
submit=self.driver.find_element_by_xpath(
"/html/body/div[@class='page-wrapper']/div[@id='page-body']/div[@id='body-
main']/div[@id='table_wrapper']/div[@class='listview full']/div[@class='dataTables_wrapper']/div[@id='main-
table_paginate']/a[@class='paginte_go']")
input.clear()
input.send_keys(sum)
submit.click()
time.sleep(2)
if sum==4:
sum-=4
##获取网页信息
source = self.driver.page_source
response = HtmlResponse(url=url, body=source, encoding='utf-8')
return response
结果
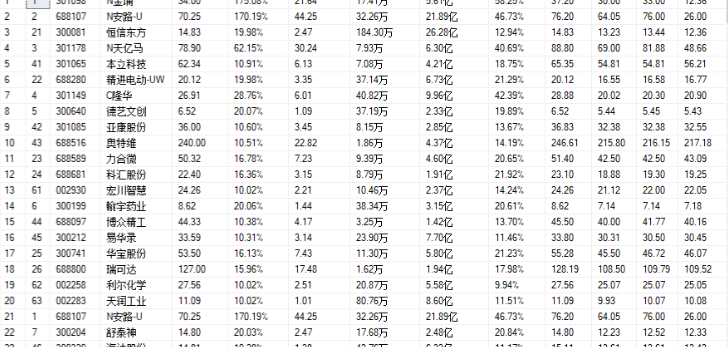

 浙公网安备 33010602011771号
浙公网安备 33010602011771号