


数据采集第一次作业(2022)
作业1:
题目:要求用urllib和re库方法定向爬取给定网址2020中国最好学科排名的数据。输出信息如下:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2 | ... | ... | ... |
解题:
url="https://www.shanghairanking.cn/rankings/bcsr/2020/0812"
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req)# 发送请求
soup=data.read().decode('utf-8')# 解析网页
1.2根据网页结点信息构造正则表达式
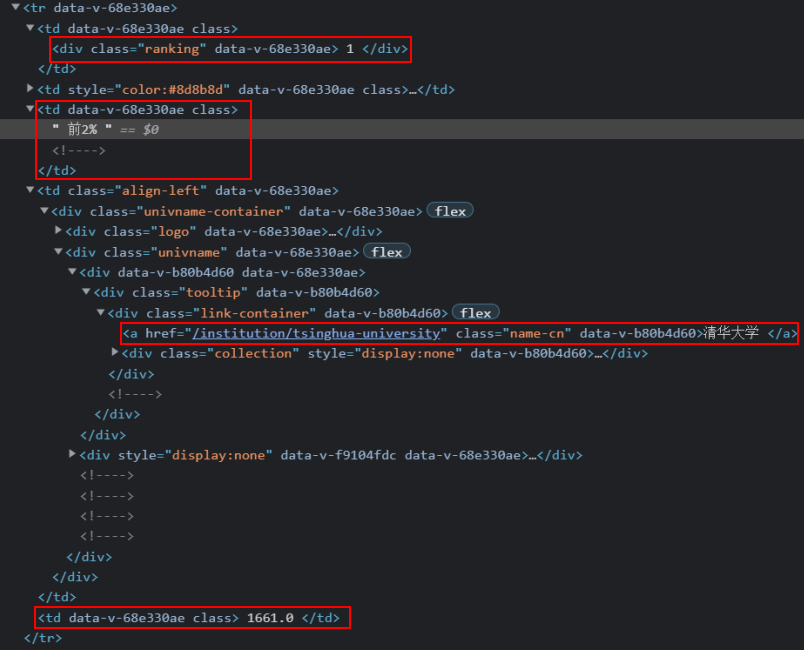
rank=[]
level=[]
school=[]
score=[]
for items in re.findall(r'<tr data-v-68e330ae>.*?</tr>', soup, re.S|re.M):
for a in re.findall(r'<div class="ranking".*?>(.*?)</div>',items,re.S|re.M):
rank.append(int(a)) #记录排名
for b in re.findall(r'<td data-v-68e330ae.*?>(.*?)</td>',items,re.S|re.M):
for k in re.findall(r'(.*?)<!---->',b,re.S):
level.append(k.strip()) #记录层次
for k in re.findall(r'\d+\.\d',b,re.S):
score.append(k.strip()) #记录总分
for c in re.findall(r'<a .*?name-cn.*?>(.*?)</a>', items, re.S|re.M):
school.append(c)# 记录学校
1.3输出代码
tplt = "{0:^10}\t{1:{4}<10}\t{2:<10}\t{3:<10}"
print(tplt.format("2020排名", "全部层次", "学校名称", "总分", chr(12288)))
for i in range(len(rank)):
print(tplt.format(rank[i],level[i],school[i],score[i],chr(12288)))
#中英文混排时采用chr(12288)
1.4输出结果
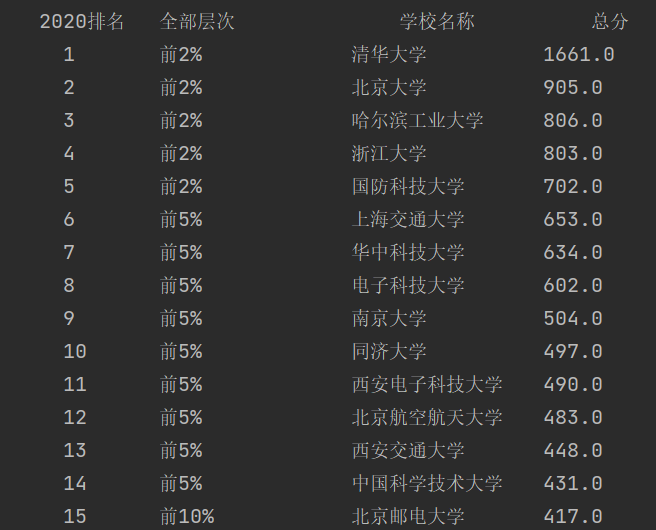
作业2:
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
输出信息:
| 序号 | 城市 | AQI | PM2.5 | .. | .. | .. | .. |
| 1 | 北京 | ... | ... | ||||
解题
获取http
使用requests进行Get请求:
url = "https://datacenter.mee.gov.cn/aqiweb2/"
response = requests.get(url)
html = response.text
# 使用缓存,防止被ban
# with open('./.cache/aqiweb2.html', 'r', encoding='utf-8') as f:
# html = f.read()
同上,添加一个缓存。
构建soup,解析表格
这里需要先解析下图中选中部分的表格: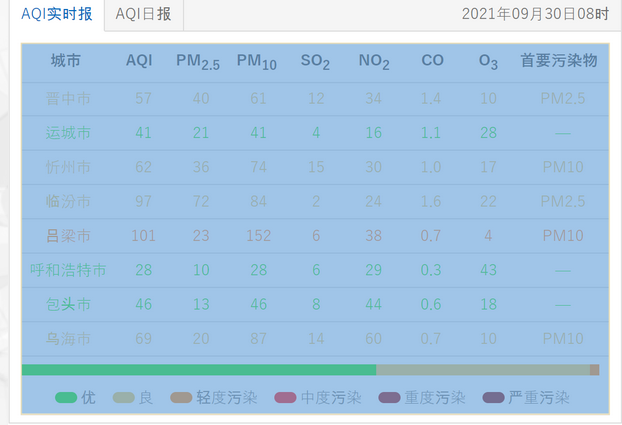
使用Beatiful Soup进行解析:
# 构建soup对象
soup = BeautifulSoup(html, "lxml")
# 解析表格
table = soup.find('div', attrs={"id": "demo"}).table.tbody
提取数据

查看该表格,发现该tbody内,tr均匀排列,且各个tr内的td内容即为需要的数据(即td.text):
因此,只需要进行两层遍历,就能提取出所有信息:
i = 0
for tr in table.find_all('tr'):
print("{:^6}".format(i), end='\t')
for td in tr.find_all('td'):
print("{:^6}".format(strQ2B(clear_data(td.text))), end='\t')
print()
i += 1
2、运行结果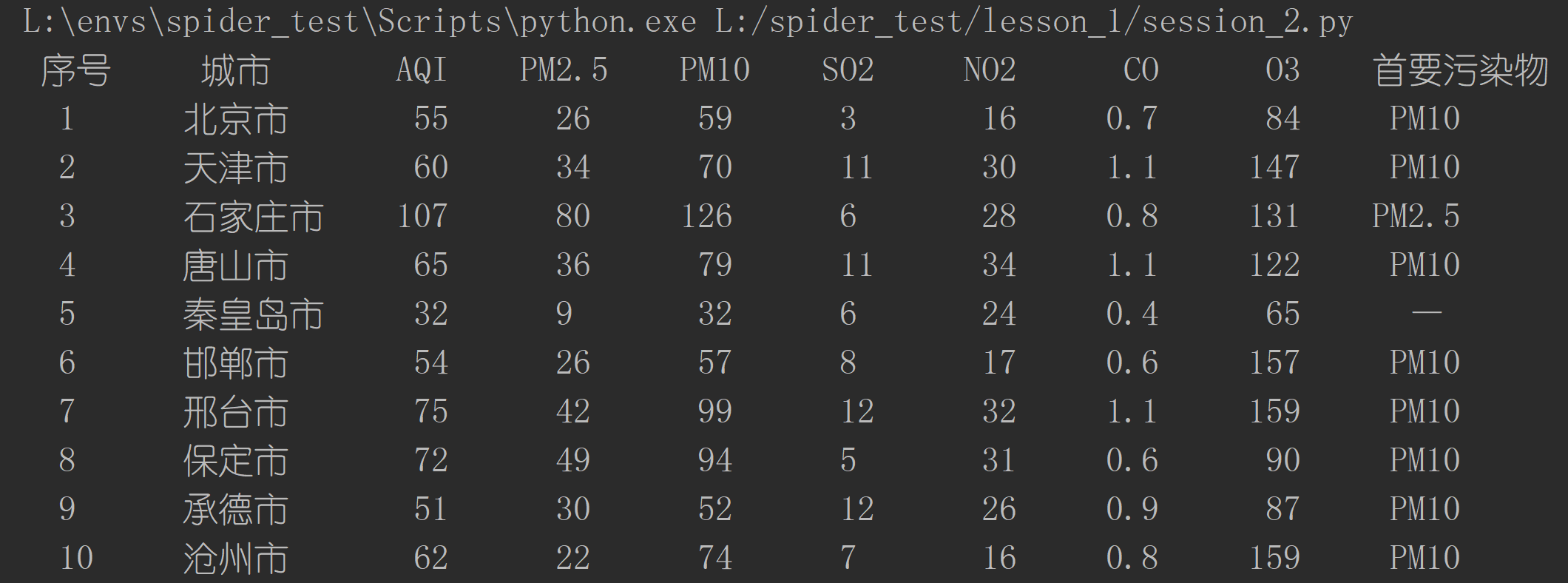
3、文件地址:https://gitee.com/mirrolied/spider_test/blob/master/lesson_2/session_2.py
作业3
要求:使用urllib和requests爬取(https://news.fzu.edu.cn/),并爬取该网站下的所有图片输出信息:将网页内的所有图片文件保存在一个文件夹中
解题
获取html
由于该题要求使用urllib.request和requests进行爬取,索性将两种方法结合缓存(即读取本地文件)整合成一个函数,由用户选择请求方法。
构建一个get_html函数,输入url以及请求方法,返回html文本:
def get_html(url: str, request_type: str) -> str:
"""
获取html
:param url: 访问地址
:param request_type: 请求方式: urllib.request 或 urllib.request 或相应缓存
:return: html
"""
if request_type == "urllib.request":
# urllib.request
return urllib.request.urlopen(url).read().decode("utf-8")
elif request_type == "requests":
# requests
response = requests.get(url)
return response.text
else:
# 读取缓存文件
with open(f'./.cache/{request_type}.html', 'r', encoding='utf-8') as f:
return f.read()
解析图片
使用正则匹配的方式,将所有的<img>标签内的src提取出来:
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
图片保存
文件内容即请求图片url返回内容,使用with open创建文件管理对象,并将模式设置为wb(二进制写入模式):
resp = requests.get(img_url)
with open(f'./download/{img.split("/")[-1]}', 'wb') as f:
f.write(resp.content)
使用字符串分割从url中提取出文件的名称(保证后缀名无误):
img.split("/")[-1]
或以"."进行分割,仅提取后缀名,自己对文件进行标号命名。
最后使用f.write(resp.content)即可实现保存。
def get_imgs(html:str, download=True) -> None:
"""
获取所有图片地址,可选择下载
:param html: 输入html
:param download: 是否下载
:return: None
"""
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
print(imgList)
print(f'共有{len(imgList)}张图片')
if download:
for i, img in enumerate(imgList):
img_url = "http://news.fzu.edu.cn" + img
print(f"正在保存第{i + 1}张图片 路径:{img_url}")
resp = requests.get(img_url)
with open(f'./download/{img.split("/")[-1]}', 'wb') as f:
f.write(resp.content)
复制代码
运行结果

本次作业gitee地址:https://gitee.com/mirrolied/spider_test/tree/master/lesson_1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号