数据采集第四次作业
作业1
1)要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
2)实验代码:
setting.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()#存储商品名
link=scrapy.Field()#存储商品链接
comment=scrapy.Field()#存储评论数
pipelines.py
# -*- coding: utf-8 -*-
import pymysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class DangdangPipeline(object):
def process_item(self, item, spider):
conn=pymysql.connect(host="127.0.0.1",user="root",password="123456",db="spider")
cursor=conn.cursor()
for i in range(0,len(item["title"])):
title=item["title"][i]
link=item["link"][i]
comment=item["comment"][i]
sql="insert into goods(title,link,comment) values ('"+title+"','"+link+"','"+comment+"')"
try:
cursor.execute(sql)
conn.commit()
except Exception as err:
print(err)
cursor.close()
conn.close()
return item
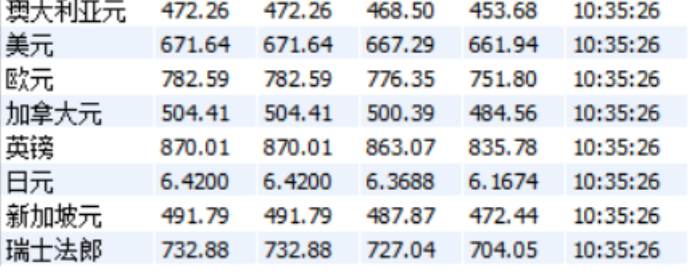
3)实验结果:
作业2:
1)实验要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
2)实验代码:
settins.py:
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}
ITEM_PIPELINES = {
'getStock.pipelines.GetstockPipeline': 300,
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.5.185:8050/"
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
RETRY_HTTP_CODES = [500, 502, 503, 504, 400, 403, 404, 408]
item.py
import scrapy
class GetstockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
code = scrapy.Field()
nprice = scrapy.Field()
op = scrapy.Field()
ed = scrapy.Field()
high = scrapy.Field()
low = scrapy.Field()
volume = scrapy.Field()
date = scrapy.Field()
hangye = scrapy.Field()
suggest = scrapy.Field()
pipelines.py:
import pyodbc
class GetstockPipeline(object):
def __init__(self):
self.conn = pyodbc.connect("DRIVER={SQL SERVER};SERVER=服务器名;UID=用户名;PWD=密码;DATABASE=数据库名")
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
try:
sql = "INSERT INTO dbo.stock_data(股票代码,股票名称,现时价格,昨收价格,开盘价格,最高价格,最低价格,总交易额,所属行业,日期) VALUES('%s','%s','%.2f','%.2f','%.2f','%.2f','%.2f','%.2f','%s','%s')"
data = (item['code'],item['name'],item['nprice'],item['ed'],item['op'],item['high'],item['low'],item['volume'],item['hangye'],item['date'])
self.cursor.execute(sql % data)
try:
sql = "update dbo.stock_data set 初步建议='%s' where dbo.stock_data.股票代码=%s"
data = (item['suggest'],item['code'])
self.cursor.execute(sql % data)
print('success')
except:
sql = "update dbo.stock_data set 初步建议='该股票暂无初步建议' where dbo.stock_data.股票代码=%s"
data = item['code']
self.cursor.execute(sql % data)
print("该股票暂无初步建议")
self.conn.commit()
print('信息写入成功')
except Exception as ex:
print(ex)
return item
spider.py
from scrapy import Spider, Request
from scrapy_splash import SplashRequest
import scrapy
import re
from getStock.items import GetstockItem
headers = {
'User-Agent': 'User-Agent:Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'
}
class StockSpider(scrapy.Spider):
name = 'stock'
start_urls = ['http://quote.eastmoney.com']
def start_requests(self):
url = 'http://quote.eastmoney.com/stock_list.html'
yield SplashRequest(url, self.parse, headers=headers)
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"\d{6}", href)[0]
url = 'http://q.stock.sohu.com/cn/' + stock
yield SplashRequest(url, self.parse1,args={'wait':5}, headers=headers )
except:
continue
def parse1(self, response):
item = GetstockItem()
try:
stockinfo = response.xpath('// *[ @ id = "contentA"] / div[2] / div / div[1]')
item['name'] = stockinfo.xpath('//*[@class="name"]/a/text()').extract()[0]
item['code'] = stockinfo.xpath('//*[@class="code"]/text()').extract()[0].replace('(','').replace(')','')
item['date'] = stockinfo.xpath('//*[@class="date"]/text()').extract()[0]
item['nprice'] = float(stockinfo.xpath('//li[starts-with(@class,"e1 ")]/text()').extract()[0])
item['high'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[1]/td[5]/span/text()').extract()[0])
item['low'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[2]/td[5]/span/text()').extract()[0])
item['ed'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[1]/td[7]/span/text()').extract()[0])
item['op'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[2]/td[7]/span/text()').extract()[0])
item['volume'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[2]/td[3]/span/text()').extract()[0].replace('亿',''))
item['hangye'] = response.xpath('//*[@id="FT_sector"] / div / ul / li[1]/a/text()').extract()[0]
suggests = response.xpath('//*[@id="contentA"]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/table/tbody/tr[1]')
item['suggest'] = suggests.xpath('//td[starts-with(@class,"td1 ")]/span/text()').extract()[0]
except:
pass
yield item
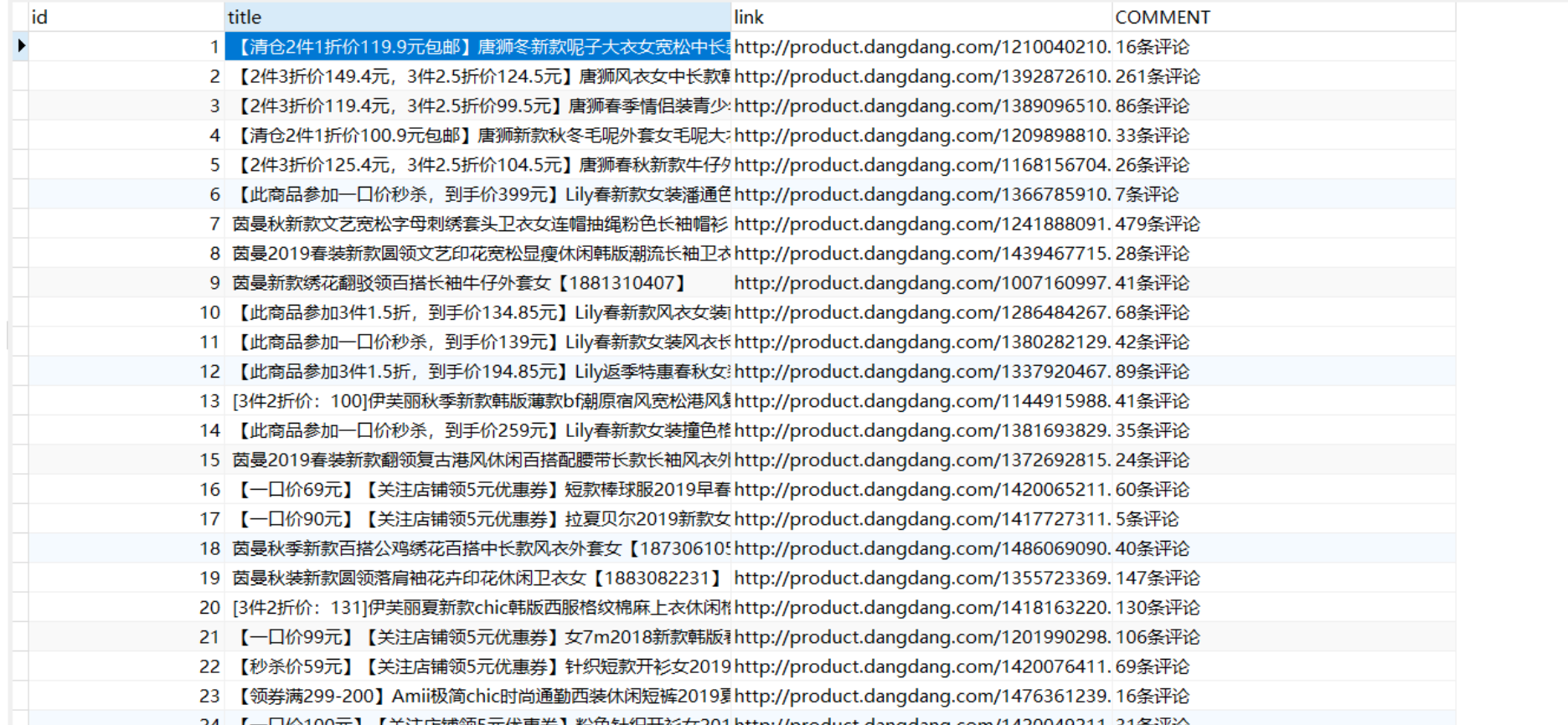
3)结果:
作业3:
1)、要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据
2)代码:
setting.py:
item.py:
import scrapy
class WaihuimysqlItem(scrapy.Item):
type = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
pipelines.py:
import pymysql
class WHmysqlPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",
passwd="031804114.hao",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from waihui")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"条")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("insert into waihui(btype,btsp,bcsp,btbp,bcbp,btime) values (%s,%s,%s,%s,%s,%s)",(item["type"],item["tsp"],item["csp"],item["tbp"],item["cbp"],item["time"]))
self.count+=1
except Exception as err:
print(err)
return item
spider.py:
import scrapy
from bs4 import UnicodeDammit
from ..items import WaihuimysqlItem
class spider_waihui(scrapy.Spider):
name = "spiderwaihui"
start_urls=["http://fx.cmbchina.com/hq/"]
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", 'gbk'])
data = dammit.unicode_markup
# print(data)
selector = scrapy.Selector(text=data)
trs = selector.xpath("//div[@id='realRateInfo']/table/tr")
# print(trs)
for tr in trs[1:]:
item=WaihuimysqlItem()
a =tr.xpath("./td[position()=1][@class='fontbold']/text()").extract_first()
item["type"] = str(a).strip()
item["tsp"] = str(tr.xpath("./td[position()=4][@class='numberright']/text()").extract_first()).strip()
item["csp"] = str(tr.xpath("./td[position()=5][@class='numberright']/text()").extract_first()).strip()
item["tbp"] = str(tr.xpath("./td[position()=6][@class='numberright']/text()").extract_first()).strip()
item["cbp"] = str(tr.xpath("./td[position()=7][@class='numberright']/text()").extract_first()).strip()
item["time"] = str(tr.xpath("./td[position()=8][@align='center']/text()").extract_first()).strip()
yield item
except Exception as err:
print(err)
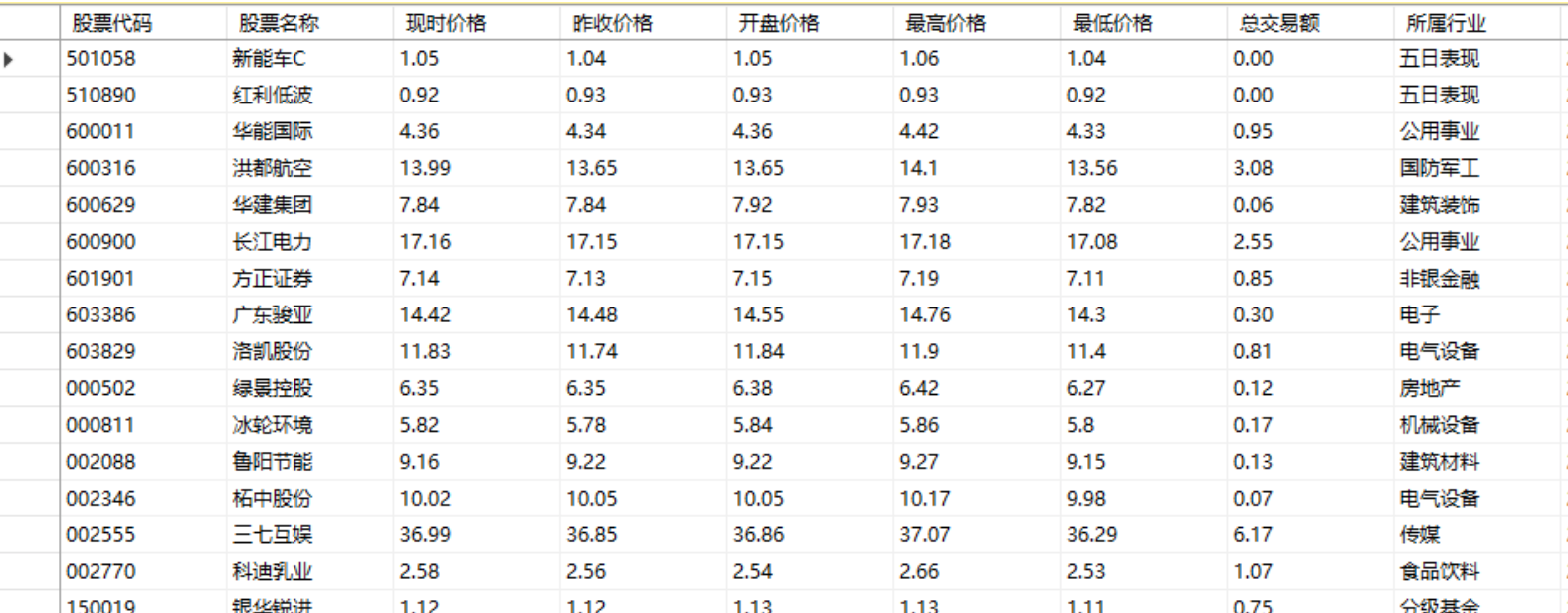
3)实验结果: