今日内容 序列化与反序列化 实现增删改查
-
APIView的基本使用
drf:是一个第三方的app,只能在djagno上使用
安装了drf后,导入一个视图类APIView,所有后期要使用drf写视图类,都是继承APIView及其子类
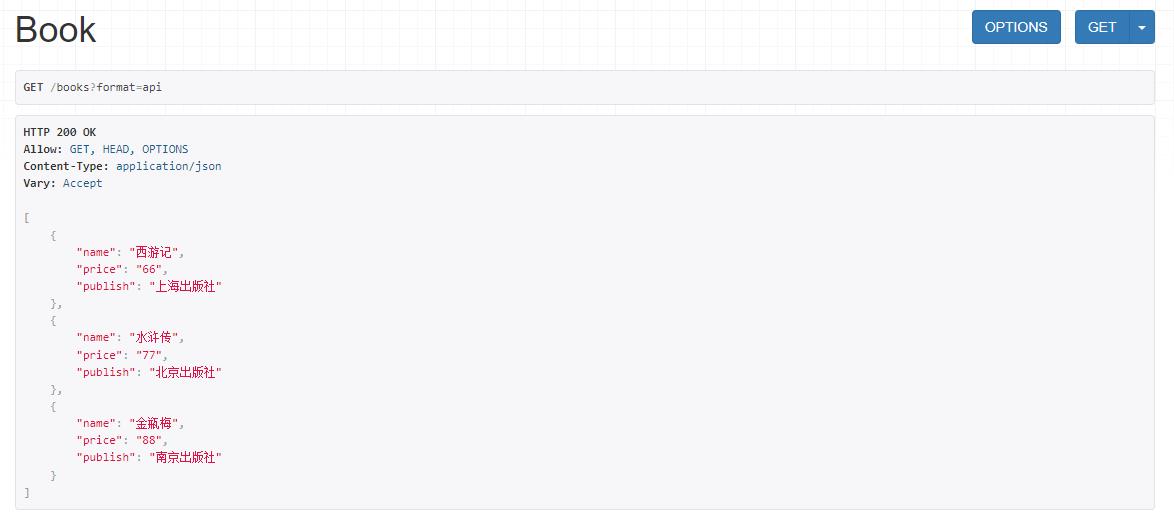
例:获取所有图书接口
1.1使用View+JsonRessponse写
from django.views import View
from .models import Book
from django.http import JsonResponse
class BookView(View):
def get(self, request):
# print(type(request))
book_list = Book.objects.all()
res_list = []
for book in book_list:
res_list.append({'name': book.name, 'price': book.price,'publish': book.publish})
return JsonResponse(res_list, safe=False,json_dumps_params={'ensure_ascii':False})
结果:

1.1使用View+JsonRessponse写
记得在settings配置文件中注册rest_framemorkapp
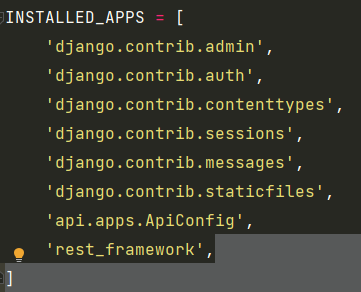
from rest_framework.views import Response
from rest_framework.views import Request
from rest_framework.views import APIView
class BookView(APIView): #APIView继承自django的View
def get(self,request):
# print(type(self.request)) # 新的request
# print(type(request))
print(request._request)
print(type(request._request))
book_list = Book.objects.all()
# book_list是queryset对象不能直接序列化,只能通过for循环一个个拼成列表套字典的形式
res_list = []
for book in book_list:
res_list.append({'name': book.name,'price': book.price,'publish': book.publish})
return Response(res_list)
结果:
-
API源码分析
# 视图类继承APIView后,执行流程就发生了变化,这个变化就是整个的drf的执行流程
# 一旦继承了APIView入口
-路由配置跟之前继承View是一样的----》找视图类的as_view---》【APIView的as_view】
@classmethod
def as_view(cls, **initkwargs):
# 又调用了父类(View)的as_view
view = super().as_view(**initkwargs)
'''
# 从此以后,所有的请求都没有csrf的校验了
# 在函数上加装饰器
@csrf_exempt
def index(request):
pass
本质等同于 index=csrf_exempt(index)
'''
return csrf_exempt(view)
-请求来了,路由匹配成功会执行 View类的的as_view类方法内的view闭包函数(但是没有了csrf认证),
-真正的执行,执行self.dispatch---->APIView的dispatch 【这是重点】
def dispatch(self, request, *args, **kwargs):
# 参数的request是原来的django原生的request
# 下面的request,变成了drf提供的Request类的对象---》return Request(。。。)
request = self.initialize_request(request, *args, **kwargs)
# self 是视图类的对象,视图类对象.request=request 新的request
self.request = request
try:
# 执行了认证,频率,权限 [不读]
self.initial(request, *args, **kwargs)
# 原来的View的dispatch的东西
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
except Exception as exc:
# 如果出了异常,捕获异常,处理异常,正常返回
# 在执行三大认证和视图类中方法过程中,如果出了异常,是能被捕获并处理的---》全局异常的处理
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
-
APIView源码分析
#1 视图类中使用的request对象,已经变成了drf提供的Request类的对象了
-原生djagno 的request是这个类的对象:django.core.handlers.wsgi.WSGIRequest
-drf的request是这个类的对象:rest_framework.request.Request
#2 request已经不是原来的request了,还能像原来的request一样使用吗?
-用起来,像之前一样
print(request.method) # get
print(request.path) # /books/
print(request.GET) # 原来的get请求提交的参数
print(request.POST) # 原来post请求提交的参数
#3 Request的源码分析:rest_framework.request.Request
-类中有个魔法方法:__getattr__ 对象.属性,属性不存在会触发它的执行
def __getattr__(self, attr): # 如果取的属性不存在会去原生django的request对象中取出来
try:
#反射:根据字符串获取属性或方法,self._request 是原来的request
return getattr(self._request, attr)
except AttributeError:
return self.__getattribute__(attr)
-以后用的所有属性或方法,直接用就可以了---》(通过反射去原来的request中取的)
总结:
"""
drf的APIView类:
1.重写了as_view(),但主题逻辑还是调用父类view的as_view(),禁用了csrf认证(!所有继承drf的基本视图类APIView的视图类,都不做csrf认证校验)
2.重写了dispatch(),在内部对request进行了二次封装:
self.initialize_request(request, *args, **kwargs)
内部核心:
走drf的Request初始方法__init__:self._request = request
drf的Request的魔法方法__getattr__: 先从self.request反射取属性,没取到再向drf的request中取
"""
-
drf序列化组件
一.序列化组件介绍
1.序列化: 序列化器会把模型对象装换成字典,经过response以后变成json字符串
2.反序列化: 把客户端发送过来的数据进行数据校验,通过后经过request以后变成字典,序列化器可以把字典转成模型
二.简单使用步骤
1.写一个序列化类,继承Serializer
2.在类中写要序列化的字段,想序列化哪个字段,就在类中 写那个字段
3.在视图类中使用: 导入—> 实例化得到序列化类的对象,把要序列化的对象传入
4.序列化类的对象.data (字典)
5.把字典返回,如果不使用rest-framework提供的Response,就得使用JsonResponse
models.py
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.CharField(max_length=32)
views.py
class BookView(APIView):
# def get(self,request,): # 序列化多条数据
# book_list = Book.objects.all()
def get(self,request,pk): # 序列化单条数据
book_list = Book.objects.filter(pk=pk).first
# instance表示要序列化的数据,many=True表示序列化多条数据
ser = BookSerializer(instance=book_list)
return Response(ser.data)
ser.py
class BookSerializer(serializers.Serializer):
# 要序列化的字段 有很多字段类型,字段类型有很多字段属性
# max_length 最大长度
# min_lenght 最小长度
# allow_blank 是否允许为空
# trim_whitespace 是否截断空白字符
# max_value 最小值
# min_value 最大值
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
url.py
from django.contrib import admin
from django.urls import path
from api.views import BookView
urlpatterns = [
path('admin/', admin.site.urls),
path('books', BookView.as_view()),
path('books/<int:pk>/',BookView.as_view())
]
-
反序列化(增删改查)
新增
view.py
class BookView(APIView):
def post(self,request):
# 前端传递数据,从request.data取出来
ser = BookSerializer(data=request.data)
if ser.is_valid():# 表示校验前端传入的数据 没有写校验规则,现在等于没校验
ser.save() # 再写东西,这里会报错 调用save会触发BookSerializer的save方法,
# 判断了,如果instance有值执行update,没有值执行create
return Response(ser.data)
else:
return Response(ser.errors)
models.py
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
# 重写create方法,
def create(self, validated_data):
res = Book.objects.create(**validated_data)
return res
修改
view.py
class BookDetailView(APIView):
def put(self, request, pk):
book = Book.objects.filter(pk=pk).first()
# 前端传递数据,从request.data取出来
ser = BookSerializer(instance=book, data=request.data)
if ser.is_valid(): # 表示校验前端传入的数据 没有写校验规则,现在等于没校验
ser.save() # 再写东西,这里会报错 调用save会触发BookSerializer的save方法,判断了,如果instance有值执行update,没有值执行create
return Response(ser.data)
else:
return Response(ser.errors)
models.py
class BookSerializer(serializers.Serializer):
# 要序列化的字段 有很多字段类,字段类有很多字段属性
name = serializers.CharField() # 字段类
price = serializers.CharField()
publish = serializers.CharField()
# 重写update
def update(self, instance, validated_data):
# instance要修改的对象
# validated_data 校验过后的数据
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
instance.save()
return instance
查询所有
view.py
class BookView(APIView):
def get(self,request):
book_list = Book.objects.all()
res_list = []
for book in book_list:
res_list.append({'name': book.name, 'price':book.price, 'publish':book.publish})
return Response(res_list,many=True)
models.py
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.CharField(max_length=32)
查一本
view.py
class BookView(APIView):
def get(self, request,pk):
book_list = Book.objects.filter(pk=pk).first()
res_list = []
for book in book_list:
res_list.append({'name': book.name, 'price':book.price, 'publish':book.publish})
return Response(res_list)
删除
view.py
class BooksView(APIView):
def delete(self,request,pk):
res = Book.objects.filter(pk=pk).delete()
return Response({'status': 1000, 'msg': '删除成功'})
http请求头有哪些?
点击查看
HTTP Request Header 请求头
Accept:指定客户端能够接收的内容类型。
Accept-Charset:浏览器可以接受的字符编码集。
Accept-Encoding:指定浏览器可以支持的web服务器返回内容压缩编码类型。
Accept-Language:浏览器可接受的语言。
Accept-Ranges:可以请求网页实体的一个或者多个子范围字段。
AuthorizationHTTP:授权的授权证书。
Cache-Control:指定请求和响应遵循的缓存机制。
Connection:表示是否需要持久连接。(HTTP 1.1默认进行持久连接)
CookieHTTP:请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。
Content-Length:请求的内容长度。
Content-Type:请求的与实体对应的MIME信息。
Date:请求发送的日期和时间。
Expect:请求的特定的服务器行为。
From:发出请求的用户的Email。
Host:指定请求的服务器的域名和端口号。
If-Match:只有请求内容与实体相匹配才有效。
If-Modified-Since:如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码。
If-None-Match:如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变。
If-Range:如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。
If-Unmodified-Since:只在实体在指定时间之后未被修改才请求成功。
Max-Forwards:限制信息通过代理和网关传送的时间。
Pragma:用来包含实现特定的指令。
Proxy-Authorization:连接到代理的授权证书。
Range:只请求实体的一部分,指定范围。
Referer:先前网页的地址,当前请求网页紧随其后,即来路。
TE:客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息。
Upgrade:向服务器指定某种传输协议以便服务器进行转换(如果支持。
User-AgentUser-Agent:的内容包含发出请求的用户信息。
Via:通知中间网关或代理服务器地址,通信协议。
Warning:关于消息实体的警告信息
http协议各个版本区别
点击查看
HTTP 0.9:
1.只支持GET请求
2.没有协议头
3.无状态性
4.只能传输超文本
HTTP 1.0:
1.除了GET命令,新增了POST和HEAD命令
2.不再只接收HTML格式数据,可以设置contentType传输多种数据格式
3.新增状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、
内容编码(content encoding)等
HTTP 1.1:
1.引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用。
2.请求和响应都支持Host头域,认为每一个服务器都绑定唯一的一个IP地址。
3.字节范围请求:若客户端此时已经有一部分数据,为节省带宽,可以只向服务器端请求一部分数据,这个功能在请求头的range头域实现。
4.新增了一批Request method:HTTP1.1增加了OPTIONS,PUT, DELETE, TRACE, CONNECT方法
HTTP 2.0:
为了解决1.1版本利用率不高的问题,提出了HTTP/2.0版本。但目前似乎还没流行起来。
主要新增特性:
1.增加双工模式,也就是不经客户端可以同时发送多个请求,服务器端也能处理多个请求,以此来提高利用率,也是这个版本最大亮点。
2.服务器推送:不经请求向客户端发送数据
3.二进制分帧层
4.数据流:将每个请求或相应的所有数据包称为一个数据流,每个数据流有一个ID,规定客户端发出的ID为奇数,服务器端发出的ID
为偶数;客户端还可以设置优先级,优先级越高,服务器越优先处理
5.头信息压缩机制:由于HTTP很多请求头信息中的字段都一样,可以先压缩后发送,而且客户端和服务器端可以同时维护一张头信息
表,只用穿输索引号,大大提高效率
HTTP3.0:
在2018年发布,基于谷歌的QUIC,底层使用udp代码tcp协议。
主要提升:
1.使用stream进一步扩展HTTP2.0 的多路复用,传输多少文件就可以产生多少stream,若发生丢包,只需要传输丢失的stream
2.基于UDP,提高了传输效率,降低延迟
3.通过引入 Connection ID,使得 HTTP/3 支持连接迁移以及 NAT 的重绑定
4.HTTP/3 含有一个包括验证、加密、数据及负载的 built-in 的 TLS 安全机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号