

服务端防身术之高并发修炼之道
一、并发问题
笔者在过去工作中发现,但凡工程师面临的技术问题,脱不开如何最大限度得发挥有限的计算、存储资源。
本文关注的并发问题[1][2]的核心,实质上在最大限度利用集群的计算、存储能力,提供低延迟的服务过程中所面临的技术挑战。
互联网时代,网络服务面临海量的客户流量,使得任何想以单CPU乃至单机进行服务都是痴人说梦。因此当今互联网服务,往往都是🈶由庞大的物理机、虚拟机集群所组成的庞然大物,而如何驾驭这个庞然大物,使其高效稳定的提供业务服务,就是本文所探讨的高并发技术的核心。
高并发技术并非银弹,它伴生着大量的问题,最最关键的点就在于任何业务,最终都是数据驱动,并应用于数据。不同节点、CPU在执行业务逻辑的时候,免不了访问同样的数据,更改同样的数据。这种更改必须是有序的、原子的,否则就面临数据不一致的问题。例如现在分时现代分时操作系统[3]的进程\线程上下文切换、Go语言的协程切换、多核CPU并发执行等。
笔者认为并发所面临的技术挑战的本质是指令执行乱序导致执行结果和预期结果不一致,这种乱序从各个维度上可以分为:
- CPU指令(机器码)的乱序执行。
- 代码更改内存数据乱序。
- 服务修改客户数据乱序。
笔者将会在之后的文章中,分析这些问题出现的原因和业界的一些解决方案。
二、指令并发之道
现代CPU的计算能力远超过了存和硬盘的存取能力。为了解决这个问题以释放CPU的计算能力,现代CPU依据局部性原理[6],引入了从属CPU的高速缓存。
当摩尔定律失效,单核算力越来越难以提高,CPU引入更多的计算核心,通过并行计算来提供算力。
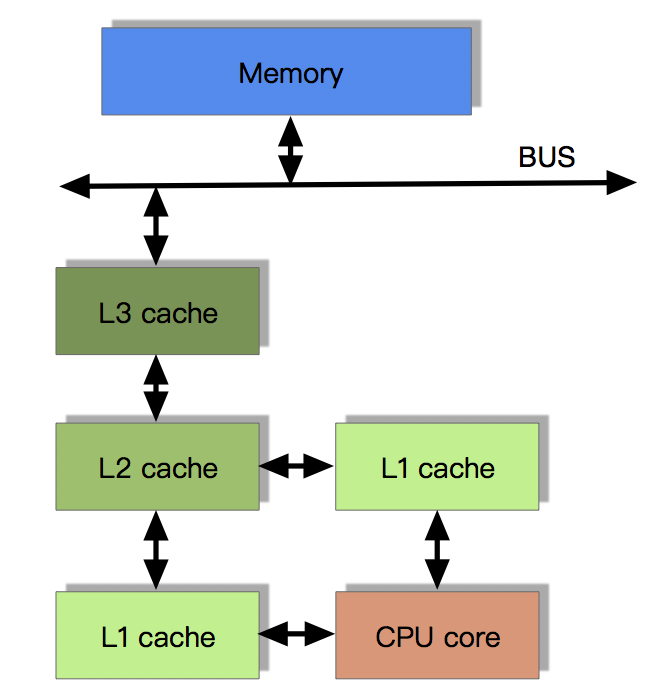
前文提到的图1的现代CPU在提供越来越强的算力的同时,也引入了许多问题:
- CPU高速缓存和内存数据不一致,其他线程/进程对此不可见。
- CPU寄存器中数据和高速缓存不一致,其他核心对此不可见。
- CPU指令重排导致执行顺序与预期不符,数据变更异常。
在较早的486以及Pentium 时代[7],CPU通会显式得向系统总线发出Lock# 信号,Bus Arbiter作为仲裁者给予某个CPU对对应Cache line[18]的独占权。
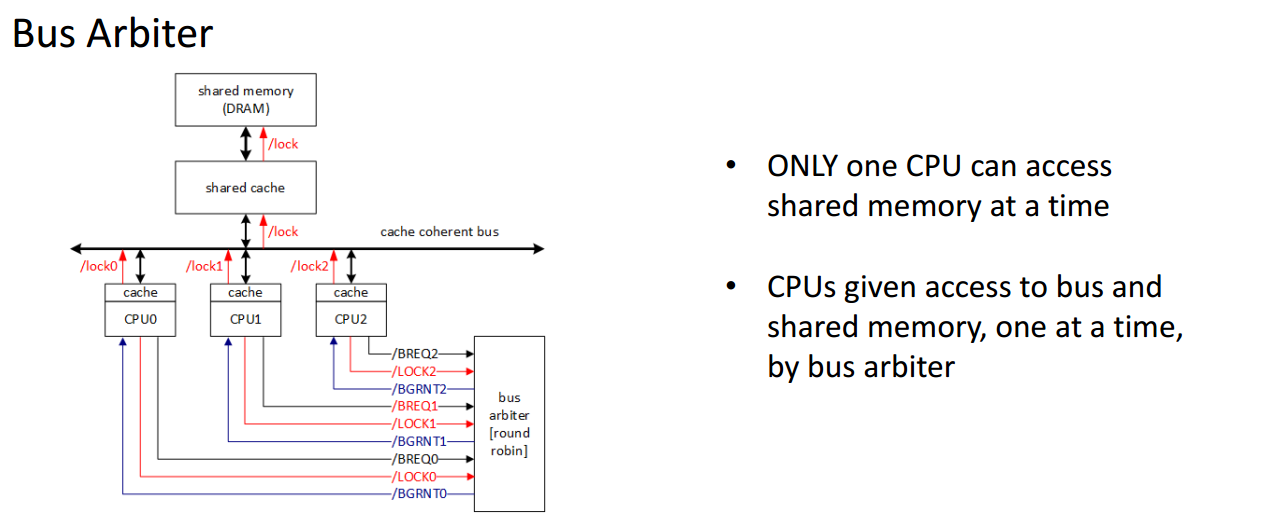
总线独占模式,某种意义上讲很像go的Mutex、
C/C++的互斥锁、和java的synchroized,本质上是独占存储访问权。这会无脑得将多个CPU的互斥执行串行化,大大降低CPU的吞吐量。
为了提升性能,CPU引入了MESI协议[8][9],它将CPU的Cache line标记为四种状态(2 bit):
| 状态 | 描述 | 特性 |
|---|---|---|
| M | Cache line是脏数据,与主存的值不同 | 其他CPU要读取Cache line对应的主存数据,Cache line的值必须回写到主存 |
| E | Cache line非脏数据,且只在当前缓存中 | Cache line数据和主存数据相同。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。 |
| S | Cache line非脏数据,且存在于其他缓存中 | Cache line可以在任意时刻被抛弃 |
| I | Cache line存储的数据无效 | Cache line数据是无效的 |

MESI保证了数据的一致性[12],且较总线独占模式性能更好,但依然存在性能瓶颈。首先消息传递是需要时间的,这就导致切换时会产生延迟。其次,当一个缓存被切换状态时,会涉及到其他缓存的状态切换。
在缓存切换过程中,CPU会等待所有缓存响应完成。这是个阻塞操作,其算力被浪费。CPU引入了Store Buffers[11]使这个过程异步化,提升CPU性能。
这里的Store Buffer有些像MQ,执行者将任务投递到队列中即完成任务。实际任务由队列消费者来进行处理。
当然,Store Buffer有MQ的特性,也兼具了MQ的问题。
- CPU读取值时,会尝试从store buffer中读取,但值本身还未提交。
- 写回动作实际并未完成落到主存中。
- 当Store Buffers塞满后,依然会造成其他核心的阻塞。
因此CPU又引入了Invalidate Queue[12]。
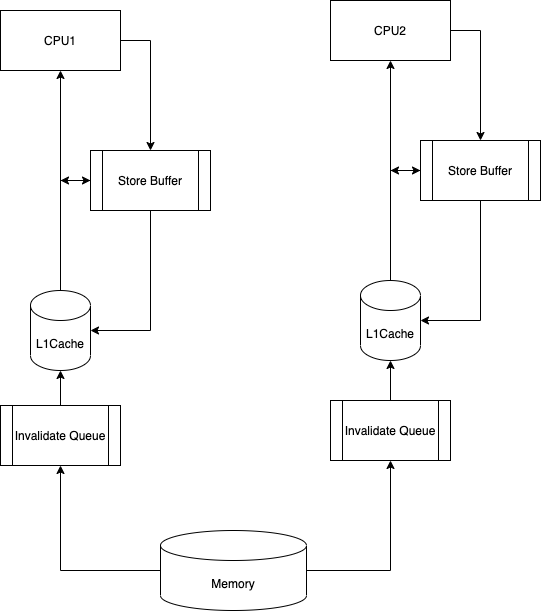
前文的优化得到了图4的架构,这种架构较一开始的独占总线大大提高了性能。
但是一致性问题还是存在,例如以下代码样例[14]:
a = 0;
b = 0;
void exeToCPUA(){
a = 1;
b = 1;
}
void exeToCPUB(){
while (b == 0) continue;
assert(a == 1);
}
下图5是上面代码并行执行的一种情况,可以发现,由于现代CPU的性能优化,CPU对于同一个内存值的的操作顺序是可能被打乱的,导致执行结果不符合预期。
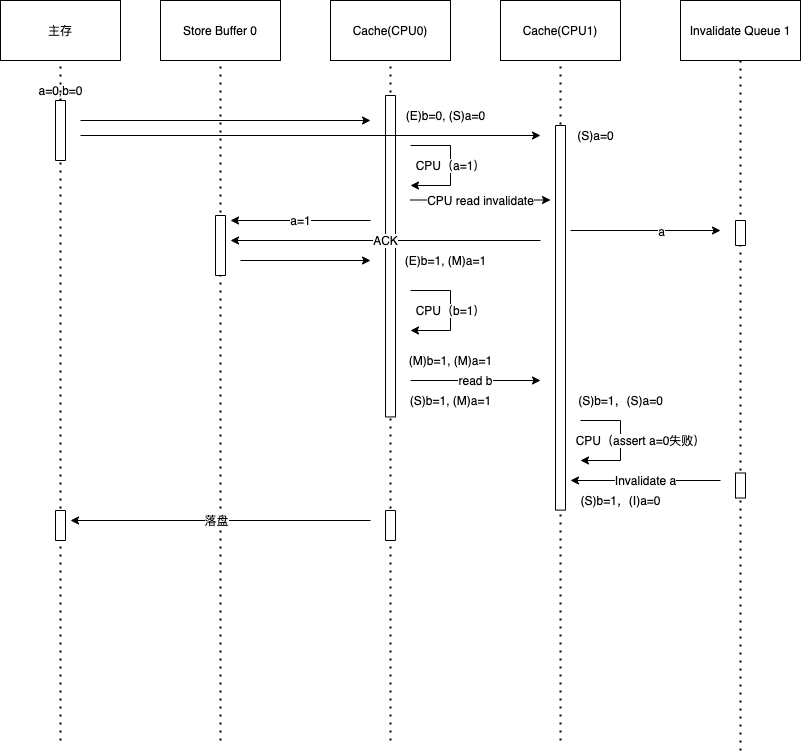
这个时候,CPU已然不知道什么时候优化是允许的,而什么时候并不允许。
干脆处理器将这个任务丢给了写代码的人。这就是内存屏障(Memory Barriers)[15]。
- 写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer)中的保存的指令。
- 读屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列中的失效操作的指令
通过引入读写屏障,就可以保证CPU指令级别的缓存一致性。
a = 0;
b = 0;
void exeToCPUA(){
a = 1;
smp_wmb();
b = 1;
}
void exeToCPUB(){
while (b == 0) continue;
smp_rmb()
assert(a == 1);
}
三、代码并发之道
上节探讨了CPU对机器码指令并发问题的种种技术,本节会着重介绍操作系统、编程语言时如何提供代码片段级别的并发安全技术。
常见的代码片段级别的并发安全技术有有信号量、临界区、锁(自旋锁、读写锁)等,这些机制的底层核心思路与CPU保持一致,即保证代码段执行的原子性,进而保证数据访问的有序性,最终保证数据的并发安全。
这里绕不开的一个高性能并发技术就是原子操作[17],以及其中的特殊的一类操作CAS[16],这两种技术本质上是利用上一节提到的CPU的原子能力,提供硬件层的原子指令支持。
笔者接下来将会主要介绍CAS,这是Lock-Free[21]和同步原语的基础技术。
下面笔者引用了一段JVM的CAS代码,核心点在于汇编指令lock和cmpxchgl,前者锁住了Cache,后者汇编级别的CAS,进而保证CAS数据的原子性:
// atomic_linux_x86.hpp
template<>
template<typename T>
inline T Atomic::PlatformCmpxchg<4>::operator()(T volatile* dest, T compare_value, T exchange_value, atomic_memory_order) const {
STATIC_ASSERT(4 == sizeof(T));
__asm__ volatile ("lock cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest)
: "cc", "memory");
return exchange_value;
}
Golang采用了和JVM几乎相同的手段,依赖于CPU能力进行原子操作的封装,设计哲学可以看《Updating The Go Memory Model》:
// atomic/asm_amd64.s
TEXT runtime∕internal∕atomic·Cas64(SB), NOSPLIT, $0-25
MOVQ ptr+0(FP), BX
MOVQ old+8(FP), AX
MOVQ new+16(FP), CX
LOCK
CMPXCHGQ CX, 0(BX)
SETEQ ret+24(FP)
RET
CAS保证了对某一个最小粒度的共享变量的变更是原子的、上下文相关的,能够确保对某个共享变量的变更是某一个执行单元所独占,这就架构起了锁原语的基础,下面是一段自旋锁[22]的伪代码:
var_cas = 0
while not cas(var_cas, 0, 1):
pass
do_something()
笔者认为自旋锁是一种最基本的锁技术,同时也是Lock-Free的基础技术,采用抢占式对特定资源标识进行标定,进而独占资源。它原始而高效,但也存在如下问题:
- 自旋锁是一种不释放CPU的主动check操作,未抢到资源标定的执行单元将会不停得尝试标定资源,直到标定成功,假设某个标定方之行了一个非常耗时的任务,其余执行单元将会在很长的时间内,将CPU资源用于尝试获取锁,这是一种巨大的浪费
- 自旋锁是一种抢占式的方式,会导致某个倒霉蛋在竞争中无法获取锁资源,从而被“饿死”。
为了解决上述两种问题,各类同步源语基于自旋锁,做出了各类封装。本文将主要分析Java语言的AQS[20](AbstractQueuedSynchronizer)的原理:
- AQS框架采用了基于CLH[19]的能力,解决“饥饿”问题。
- AQS提供了一套同步原语的框架,AQS通过CLH完美构建公平的锁能力,并暴露部分接口,使得实现者可以通过定制这些接口,基于CLH的结果,选择是否让渡CPU执行权限,从而防止CPU的巨大浪费。
笔者用Go实现了一版CLH,其核心在于维护起一个基于访问时序的链表,链表节点监听前驱节点的状态,当前节点会一直spin直到前驱节点释放资源,从而完成对资源的公平上锁。
// Lock CLH上锁,可重入,以锁为单位
func (lock *CLHLock) Lock() error {
// 1. 加锁状态
if atomic.CompareAndSwapUint32(&lock.node.state, LOCK_NOT_LOCK, LOCK_LOCKING) {
……
for {
preNode := atomic.LoadPointer(tail)
if atomic.CompareAndSwapPointer(tail, preNode, unsafe.Pointer(&lock.node)) {
lock.pre = (*clhNode)(preNode)
break
}
}
defer func() {
atomic.StoreUint32(&lock.node.state, LOCK_LOCKED)
lock.pre = nil
}()
……
for atomic.LoadUint32(&lock.pre.state) != LOCK_NOT_LOCK {
}
return nil
}
……
}
CLH在SMP架构下表现很好,但在在NUMA架构下,不同线程监听其他线程的状态,会造成大量cache失效问题,导致性能下降。MCS[25]是一种CLH的变体,针对NUMA架构做了优化,可以实现在NUMA架构下高效的公平自选锁,笔者的实现——传送门。
JAVA基于CLH的变体打造了AQS框架,框架的目标是规范数据原子性访问的基本流程(资源获取、CPU让渡、任务排队),同时开放当资源释放的时候,是按照抢占式还是,按照CLH队列排序进行资源占用。下面会以AQS和可重入入锁ReetrantLock的源码来进行说明:
- AQS按照CLH组织资源等待队列,但实际上是前驱释放,通知后继节点的状态位&唤醒线程的方式。(更接近MCS)
- AQS的实际上锁操作由
tryAcquire提供,AQS框架只提供了整体的管理队列,节点通知。 - AQA对于数据的读取采用了
volatile关键字,提供语言级别支持的数据可见性。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
……
// CLH节点
abstract static class Node {
volatile Node prev; // 前驱
volatile Node next; // 后继
Thread waiter; // 当前的等待线程
volatile int status; // 当前节点状态
……
}
……
// CLH头节点
private transient volatile Node head;
// CLH尾节点
private transient volatile Node tail;
// ABS状态
private volatile int state;
……
// 申请资源
public final void acquire(int arg) {
if (!tryAcquire(arg))
acquire(null, arg, false, false, false, 0L);
}
// 尝试获取资源
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
// 实际上锁的函数,CLH只有当前驱节点成为head节点
final int acquire(Node node, int arg, boolean shared,
boolean interruptible, boolean timed, long time) {
Thread current = Thread.currentThread();
byte spins = 0, postSpins = 0;
// first标记当前节点是否为下一个可以占有资源的节点
boolean interrupted = false, first = false;
Node pred = null; // predecessor of node when enqueued
for (;;) {
// 非下一个可以抢占资源节点 && 前驱节点不为空
if (!first && (pred = (node == null) ? null : node.prev) != null &&
!(first = (head == pred))) {
if (pred.status < 0) { // 前驱节点状态码错误
cleanQueue(); // 清空等待队列,所有等待线程均无法成功执行
continue;
} else if (pred.prev == null) { // 前驱节点的前节点暂时未链接上(即前驱节点未完全准备好)
Thread.onSpinWait(); // 执行一次空循环,类似Thread.sleep(0),但底层更高效(JVM内联汇编)
continue;
}
}
// 轮到节点占有资源,尝试占有资源
if (first || pred == null) { // 当前节点成为首节点,或无前驱节点
boolean acquired;
try {
if (shared)
acquired = (tryAcquireShared(arg) >= 0);
else
acquired = tryAcquire(arg);
} catch (Throwable ex) {
cancelAcquire(node, interrupted, false);
throw ex;
}
if (acquired) { // 成功获取资源,当前节点可以是CLH队列首节点,也可能非首节点(例如ReetrantLock的非公平锁)
if (first) { // 如果当前节点为队列中的首节点,更新队列状态,当前节点成为head节点
node.prev = null;
head = node;
pred.next = null;
node.waiter = null;
if (shared)
signalNextIfShared(node);
if (interrupted)
current.interrupt();
}
return 1;
}
}
// 节点为空,则新建节点
if (node == null) {
if (shared)
node = new SharedNode();
else
node = new ExclusiveNode();
} else if (pred == null) {
// 前驱为空,将当前节点置入CLH队列中
node.waiter = current;
Node t = tail;
node.setPrevRelaxed(t); // avoid unnecessary fence
if (t == null)
tryInitializeHead();
else if (!casTail(t, node)) // 当前节点进入链表,成为尾节点
node.setPrevRelaxed(null);
else
t.next = node; // 旧尾节点成为当前节点前驱
} else if (first && spins != 0) {
--spins; // reduce unfairness on rewaits
Thread.onSpinWait();
} else if (node.status == 0) {
node.status = WAITING; // 设置节点状态为等待中
} else {
// 节点在等待中,让开
long nanos;
spins = postSpins = (byte)((postSpins << 1) | 1);
// 放开线程对于CPU的占用,并将当前的对象设置为引起阻塞的原因
if (!timed)
LockSupport.park(this);
else if ((nanos = time - System.nanoTime()) > 0L)
LockSupport.parkNanos(this, nanos);
else
break;
// 取消节点设置的状态
node.clearStatus();
if ((interrupted |= Thread.interrupted()) && interruptible)
break;
}
}
// 取消获取资源占用
return cancelAcquire(node, interrupted, interruptible);
}
……
// 释放资源
public final boolean release(int arg) {
if (tryRelease(arg)) {
signalNext(head);
return true;
}
return false;
}
// 供给框架子类型实现的方法
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
// 修改本节点状态,并通知唤醒下一个节点
private static void signalNext(Node h) {
Node s;
if (h != null && (s = h.next) != null && s.status != 0) {
s.getAndUnsetStatus(WAITING);
LockSupport.unpark(s.waiter);
}
}
}
基于上面的AQS框架,Java扩展出了各种同步工具,比如下面的可重入锁ReentrantLock,通过AQS的同步能力,很容易扩展出了需要的锁能力:
public class ReentrantLock implements Lock, java.io.Serializable {
private final Sync sync;
// 同步锁的虚基类
abstract static class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = -5179523762034025860L;
// 尝试加上锁
@ReservedStackAccess
final boolean tryLock() {
Thread current = Thread.currentThread(); // 获取当前线程
int c = getState(); // 获取AQS数值
if (c == 0) {
if (compareAndSetState(0, 1)) { // 尝试上锁
setExclusiveOwnerThread(current); // 设置上锁线程
return true;
}
} else if (getExclusiveOwnerThread() == current) { // 同一线程
if (++c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c); // 同一线程上锁,直接累加值,并设置
return true;
}
return false;
}
// 用于初始化尝试加锁
abstract boolean initialTryLock();
@ReservedStackAccess
final void lock() {
if (!initialTryLock())
acquire(1);
}
……
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
// 尝试release
int c = getState() - releases;
// 释放锁的必须是当前线程
if (getExclusiveOwnerThread() != Thread.currentThread())
throw new IllegalMonitorStateException();
boolean free = (c == 0);
if (free) // 已经完全释放,则设置独占线程未null
setExclusiveOwnerThread(null);
setState(c);
return free;
}
protected final boolean isHeldExclusively() {
return getExclusiveOwnerThread() == Thread.currentThread();
}
final boolean isLocked() {
return getState() != 0;
}
……
}
/**
* 非公平锁
*/
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
final boolean initialTryLock() {
Thread current = Thread.currentThread();
if (compareAndSetState(0, 1)) { // 上锁,成功则独占
setExclusiveOwnerThread(current);
return true;
} else if (getExclusiveOwnerThread() == current) { // 上锁失败,如果是重入,则设置占锁次数+1
int c = getState() + 1;
if (c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
} else
return false;
}
// 尝试占有资源,如果能够获取资源,则独占
protected final boolean tryAcquire(int acquires) {
// 资源未被占用,则直接抢占。(不管当前的AQS等待队列)所以是非公平锁
if (getState() == 0 && compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
}
/**
* 公平锁,与非公平锁不同的在于,当发现AQS存在等待锁资源的数据,不会直接完成资源占有,而是会加入到等待队列中。
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final boolean initialTryLock() {
Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedThreads() && compareAndSetState(0, 1)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (getExclusiveOwnerThread() == current) {
if (++c < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(c);
return true;
}
return false;
}
protected final boolean tryAcquire(int acquires) {
if (getState() == 0 && !hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
}
}
本节,笔者主要通过分析原子操作、CAS、CLH、AQS和ReetrantLock来说明,代码块级别的同步技术的实现原理。
四、服务并发之道
互联网服务离不开高并发和高可用的特性,这就导致互联网服务大多都是分布式服务,且同一服务一般由大量无状态进程共同向外提供服务。
这就导致代码级别的并发工具并不能很好得帮助程序员们控制数据的并发安全,因为这不再是代码、指令的乱序执行问题,而是业务服务的乱序执行问题。分布式服务本身是无法感知数据在分布式系统中的正确操作顺序的,因此需要引入额外的技术手段:
- 数据操作依赖数据存储中间件,通过例如MySQL事务的方式控制数据操作的顺序性。
- 通过分布式锁的方式,在分布式系统中,完成申明式的数据控制。
- 通过乐观锁和对数据进行版本控制的方式。
- 消费者唯一化。
第一种技术手段,依赖于分布式存储中间件提供的数据操作原子能力,例如MySQL的事务,Redis操作本身的顺序性,保证对于数据的变更按照FIFO的形式进行处理。
落到中间件本身,就回到了代码级别的并发问题,因为分布式中间件的存储本身不可避免得存在单点或者主备等形式,只要控制好数据变更在主体中并发的先后顺序,即可完成对于业务数据并发安全性。
MySQL在事务中表现非常优异,然而底层也逃不过加锁,只是锁的粒度优化得更细。下面是一段MySQL事务的伪代码(MySQL对于事务),事务相关的行被加上了行锁:
rows = mysql.get_data_relate_rows(data)
for row in rows:
row.lock()
do_transcation()
for row in rows:
row.unlock()
Redis的做法则比MySQL更加简单粗暴,Redis所有的业务处理(数据CRUD)都是单线程执行的操作,不存在并发问题。
这种技术手段提供了可靠的分布式并发安全的操作问题,缺点在于工程师必须对对应的存储中间件非常熟悉(会有自己的坑点),否则极易写出性能极差的代码。
第二种手段是分布式锁,是一种工程师更加具有掌控力的技术手段。伪代码如下:
db = remote_db()
return db.set_when_not_exist(lock_key, lock_version)
分布式锁依赖于第三方存储组件,它可以是redis/mysql/etcd/zookeeper等等,不同的存储中间件有不同的特性,需要额外注意。此外,这种技术方案存在如下的问题:
- 加锁操作的原子性问题。
- 加锁方挂机后,锁的回收问题。
- ABA问题,即非加锁方不小心释放了锁。
第一个问题,在redis层面可以使用setnx来实现加操作的原子性,MySQL则可以使用unique key + insert。
第二个问题,则是对已经加上的锁设置一个锁的有效时间,即锁的过期时间,以免造成死锁。但与此同时也引入了下一个问题,如果业务处理时间超过加锁时长,业务未处理完,锁已经被释放,这就导致了并发问题。这时而也催生了第三个问题,即A上锁后执行过长导致锁自动释放,此时B上锁,A此时执行完成,删除锁,此时C能够上锁……A删除了B的锁,导致C可以执行。
第二个问题是一个需要在设计层面规避,而无法解决的问题:
- 根据压测,对业务执行时间预估时间T,超时时间给予2T以上。
- 将锁的粒度尽量调小,耗时业务逻辑尽量挪出锁范围,在最终处理数据变更的时候进行加锁(乐观锁)。
第三个问题则是,采用CAS的方式进行解锁,即解锁者的身份校验。这个方式可以在加锁的时候对锁内容(lock_version)进行约束,保证短期内唯一的属性。
第三种技术手段,则是采用乐观锁&数据版本号的方式,分布式系统并发读取数据,处理数据,然而在更新数据的时候,必须保证操作原子性&数据更新必须保证存储组件中的数据版本号未变更,失败则重新执行逻辑,伪代码如下:
ok = False
while not ok:
data = data_base.get_data()
new_data = do_something()
new_data.version = data.version + 1
ok = data_base.update(new_data, where=version=data.version)
第四种手段,即将任务投递到特定处理者的队列中,保证队列消费者的单体性,化分布式为单机处理,进而避免分布式并发冲突:
service 1:
mq.append(m1)
service 2:
mq.append(m2)
mq service:
consumers = {1 : xx1, 2: xx2}
for m in mq:
consumers[hash(m.a)].post(m)
以上手段并无优劣高下之分,而需要对于不同业务进行选择。
五、参考文献
[1] 高并发:https://en.wikipedia.org/wiki/Concurrency_(computer_science)
[2] 并发问题:https://zhuanlan.zhihu.com/p/64988344
[3] 分时操作系统:https://zh.wikipedia.org/wiki/分時系統
[4] 机器语言:https://zh.wikipedia.org/wiki/机器语言
[5] 汇编语言:https://zh.wikipedia.org/wiki/汇编语言
[6] 局部性原理:https://baike.baidu.com/item/程序的局部性原理/8412331
[7] 浅论Lock 与X86 Cache 一致性:https://zhuanlan.zhihu.com/p/24146167
[8] MESI:https://zh.wikipedia.org/zh-hans/MESI协议
[9] CPU缓存一致性协议MESI:https://www.cnblogs.com/yanlong300/p/8986041.html
[10] 笔记:cpu中的cache(二):https://zhuanlan.zhihu.com/p/144836286
[11] store buffers:https://stackoverflow.com/questions/11105827/what-is-a-store-buffer
[12] Coherence Ordering for Ring-based Chip Multiprocessors:https://research.cs.wisc.edu/multifacet/papers/micro06_ring.pdf
[13] Invalid Queue:https://xie.infoq.cn/article/d5c4ab5026106db3db5888e19
[14] 并发冲突样例:https://xie.infoq.cn/article/d5c4ab5026106db3db5888e19
[15] memory barrier:https://en.wikipedia.org/wiki/Memory_barrier
[16] CAS wiki:https://en.wikipedia.org/wiki/Compare-and-swap
[17] 原子操作:https://baike.baidu.com/item/原子操作/1880992
[18] 计算机缓存Cache以及Cache Line详解:https://zhuanlan.zhihu.com/p/37749443
[19] CLH:https://zhuanlan.zhihu.com/p/161629590
[20] AQS:https://javadoop.com/post/AbstractQueuedSynchronizer
[21] Lock-Free:https://www.cs.cmu.edu/~410-s05/lectures/L31_LockFree.pdf
[22] 自旋锁:https://zh.wikipedia.org/wiki/自旋锁
[23] 从ReetrantLock看AQS:https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
[24] MCS&CLH:https://www.jianshu.com/p/b463dc269a3e
[25] MCS:https://www.cnblogs.com/shoshana-kong/p/10831502.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号