
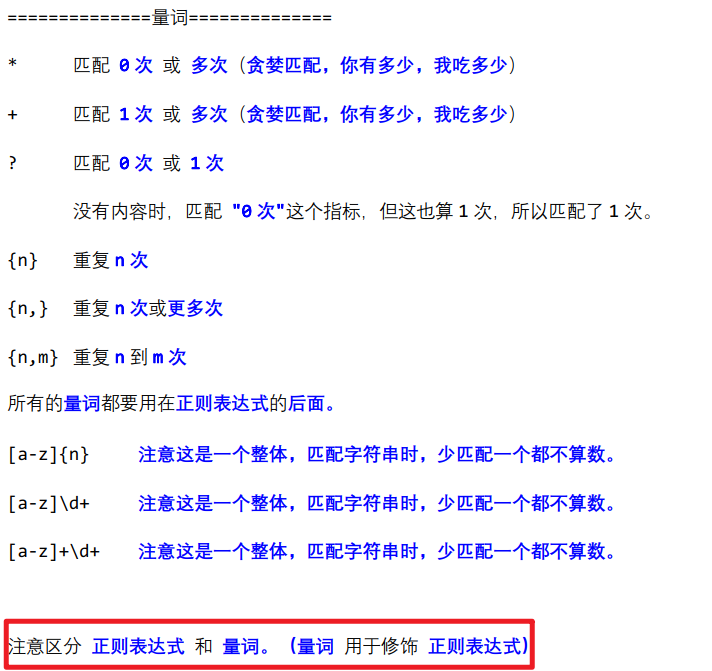
Python基础-day16-正则表达式


下图截取自站长之家:
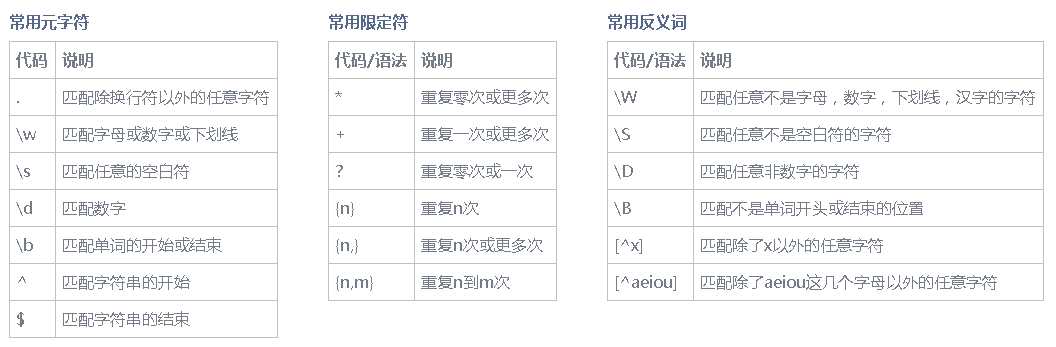
\b,\B是单词边界,不匹配任何实际字符,所以是看不到的。
\b:表示字母数字与非字母数字的边界, 非字母数字与字母数字的边界。
\B:表示字母数字与字母数字的边界,非字母数字与非字母数字的边界。
ret = re.findall('123\\b', '==123!! abc123. 123. 123abc. 123') print(ret)
打印:
['123', '123', '123', '123']
第一个123后是两个感叹号,是非数字,非字母。满足字母数字与非字母数字,于是\\b刚好表示了它们两者之间的边界。故第一个匹配的就是123。
第二个123后一个点号,也满足字母数字与非字母数字,所以也刚好匹配。
第三个123后也是一个点号,也满足字母数字与非字母数字,所以也刚好匹配。
第四个123后是a,属于字母,不满足字母数字与非字母数字,所以不匹配。
第五个123后是'',不是字母数字,所以满足条件,所以匹配。
因此最后的结果中包含4个匹配项。
ret = re.finditer('pyc\B', '1pycthon py5 2pyc342 pyc1py2py4 pyp3 3pyc# pyc') for i in ret: print(i)
打印结果:
<re.Match object; span=(1, 4), match='pyc'>
<re.Match object; span=(14, 17), match='pyc'>
<re.Match object; span=(21, 24), match='pyc'>
总共只有三项匹配,且坐标被打出来了。我用红色标出来了。
根据规则,字母数字与字母数字、非字母数字与非字母数字在一起才会匹配。
这个图就是正则的精髓。
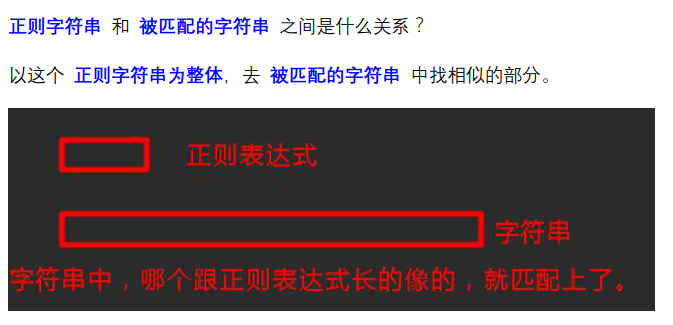
这个图就是正则的精髓。






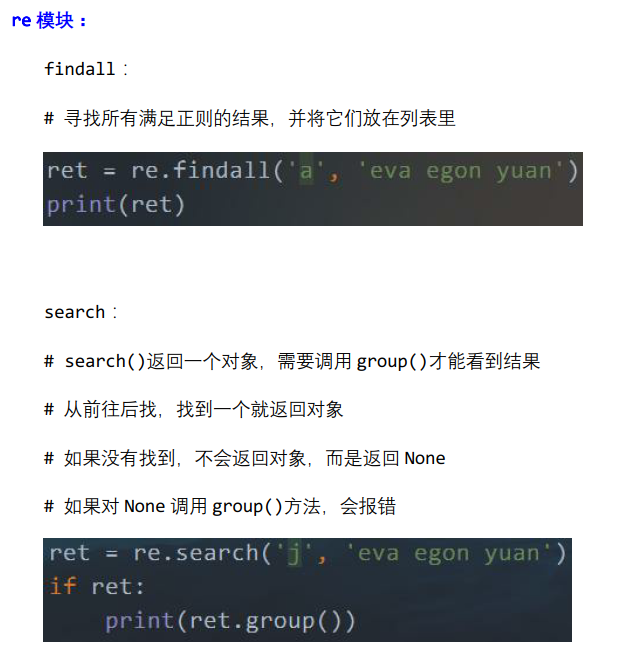
findall()返回列表,列表中保存了所有匹配到的结果。
search()返回<re.Match object; span=(1, 2), match='a'>,需要使用group()才能查看它的结果。
如果search()匹配到一个,就停止。并返回一个re.Match对象。
如果search()匹配不到,就返回None。
ret2 = re.search('a', 'yang wang zhang') print(ret2) if ret2: print(ret2.group())
<re.Match object; span=(1, 2), match='a'>
这里的span=(1, 2)指的是字符串中的索引值。[1, 2]刚好指的是a。后面的match值就是匹配的值。
ret2 = re.search('w', 'yang wang zhang') print(ret2) if ret2: print(ret2.group())
<re.Match object; span=(5, 6), match='w'>
这里的span=(5, 6)指的是字符串中的索引值。[5, 6]刚好指的是w。后面的match值就是匹配的值。
返回的re.Match对象可以调用span(),会打印索引坐标。比如上例中会打印(5, 6)。
ret2 = re.search('wa', 'yang wang zhang')
print(ret2.span())
打印:
(5, 7)
注意:search()不要求从索引0的位置开始匹配。
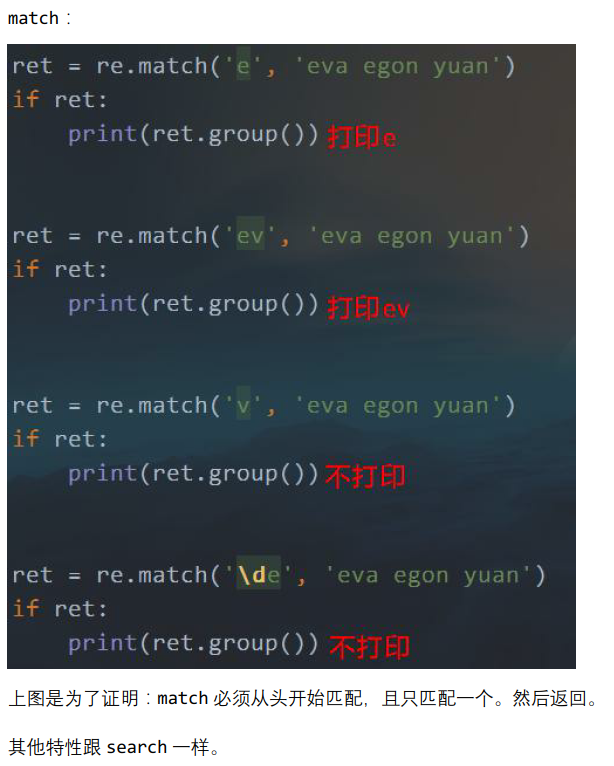
注意:search()不要求从索引0的位置开始匹配,没有匹配的,返回None。
注意:match()强制要求必须从索引为0的位置开始匹配,匹配不上,就返回None。
除了这个区别,search同match的其他方面都是一样的。
ret2 = re.match('ya', 'yang wang zhang') print(ret2) print(ret2.span()) if ret2: print(ret2.group())
打印:
<re.Match object; span=(0, 2), match='ya'>
(0, 2)
ya
ret2 = re.match('a', 'yang wang zhang') print(ret2) print(ret2.span()) if ret2: print(ret2.group())
ret2为None。
执行ret2.span()报错。
因为a在index为1的地方,所以报错。

切割,类似字符串的split()方法。
ret = re.split('a', 'abcd') print(ret) print('abcd'.split('a'))
返回:
['', 'bcd']
['', 'bcd']

这句话贼经典。正则的方法再多,也多不过字符串的内置方法。
string = 'eyehostyeyeye' ret1 = re.sub('e', 'H', string) ret2 = re.sub('e', 'H', string, 2) print(ret1) print(ret2)
打印:打印的直接是字符串。
HyHhostyHyHyH
HyHhostyeyeye
sub(pattern, repl, string, count=0, flags=0)
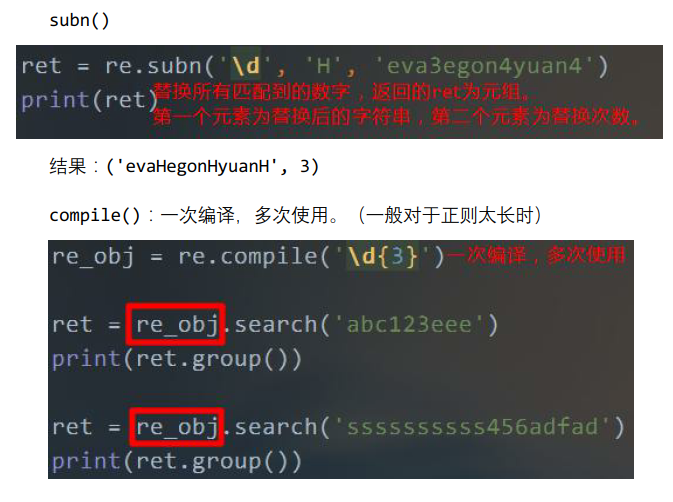
subn()功能跟sub一模一样。只不过,subn返回的是含有两个元素的元祖。第一个元素是替换后的字符串,第二个元素是替换了多少个。
string = 'eyehostyeyeye' ret1 = re.subn('e', 'H', string) ret2 = re.subn('e', 'H', string, 2) print(ret1) print(ret2)
打印:
('HyHhostyHyHyH', 5)
('HyHhostyeyeye', 2)
compile()将正则表达式进行编译,编译之后,就能到处使用。上图就是使用的例子。
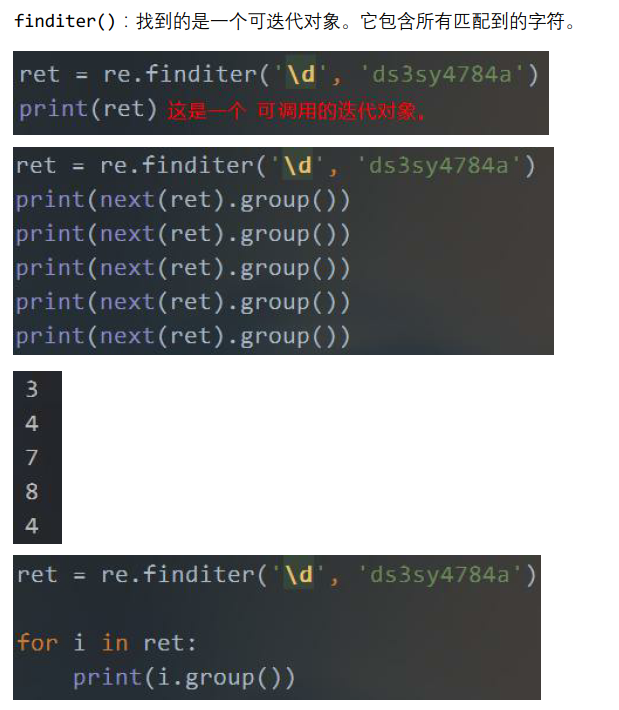
ret = re.finditer('\d', 'ds3sy4784a') print(ret) print(next(ret)) print(next(ret)) print(next(ret)) print(next(ret)) print(next(ret))
<callable_iterator object at 0x029C0B50>
<re.Match object; span=(2, 3), match='3'>
<re.Match object; span=(5, 6), match='4'>
<re.Match object; span=(6, 7), match='7'>
<re.Match object; span=(7, 8), match='8'>
<re.Match object; span=(8, 9), match='4'>
从上面的例子中,可以看出,返回的ret是一个迭代器。我们通过next()来访问它,或者通过for来遍历它。
访问的结果和遍历的结果是一个re.Match对象。
我们需要单独对这个对象执行group(),才能访问最终的值。
ret = re.finditer('\d', 'ds3sy4784a') print(ret) for re_match in ret: print(re_match.group(), re_match.span())
3 (2, 3)
4 (5, 6)
7 (6, 7)
8 (7, 8)
4 (8, 9)
匹配身份证号
re_expression = '^[1-9]\d{14}(\d{2}[0-9X])?' id_code = '111081191111173611' ret = re.search(re_expression, id_code) print(ret.group()) print(ret.group(1)) print(ret.groups())
这里考虑了15位和18位身份证号。
111081191111173611
611
('611',)
re_expression = '^[1-9]\d{14}(\d{2}[0-9X])?' id_code = '111081191111173' ret = re.search(re_expression, id_code) print(ret.group()) print(ret.group(1)) print(ret.groups())
打印:(这次身份证只有15位)
111081191111173
None
(None,)
由于正则中的()代表一个分组,如果没有匹配,则内容是None。如果正则中有多个(),()分组,则它们最终会组成ret.groups()的值。
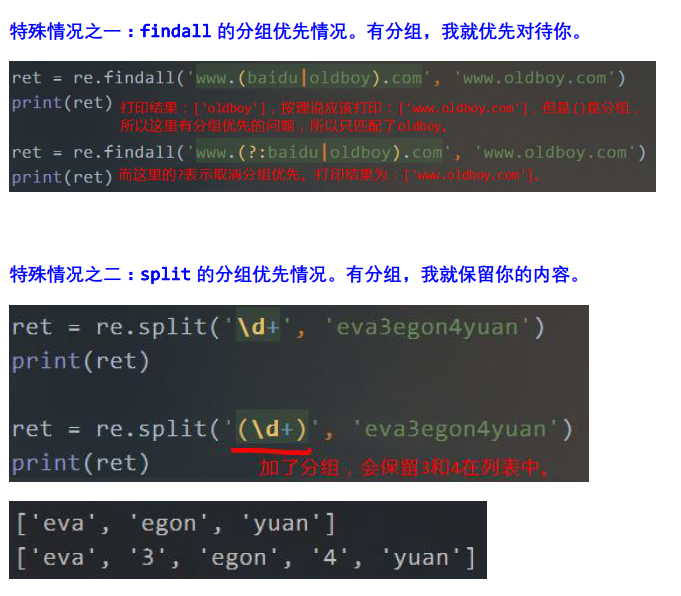
ret = re.findall('www.(baidu|sohu).com', 'www.sohu.com') print(ret)
打印:
['sohu']
分组优先:(baidu|sohu),匹配www.sohu.com,在两个选择中,sohu匹配上了,于是结果就是['sohu']。
ret1 = re.split('e', 'evaevaevaeva') ret2 = re.split('(e)', 'evaevaevaeva') print(ret1) print(ret2)
以e作为分隔符,将字符串分割成列表。
['', 'va', 'va', 'va', 'va']
['', 'e', 'va', 'e', 'va', 'e', 'va', 'e', 'va']


?P<>是固定的格式。
id是变量名。
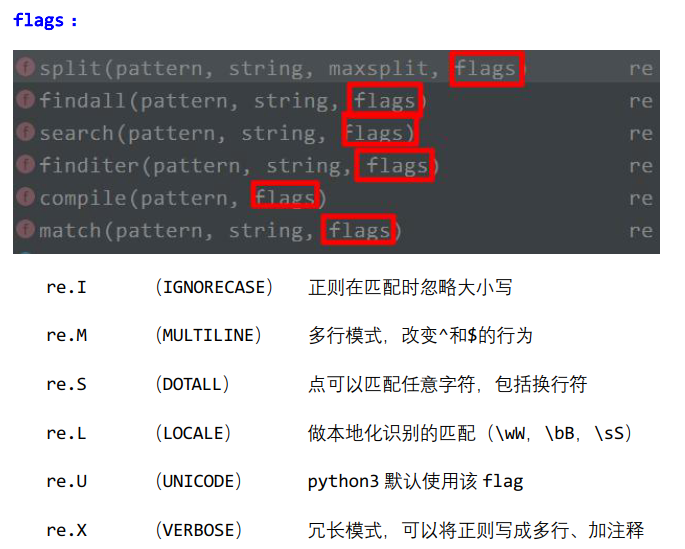
首先是re.I,忽略大小写:
ret = re.split('E', 'EvaevaEvaeva') print(ret) ret = re.split('E', 'EvaevaEvaeva', flags=re.I) print(ret)
打印:
['', 'vaeva', 'vaeva']
['', 'va', 'va', 'va', 'va']
记住,添加标记位时,一定要加flags=,否则不生效。对于关键字赋值,一定要写全。
ret = re.split('e', 'EvaevaEvaeva') print(ret) ret = re.split('e', 'EvaevaEvaeva', flags=re.I) print(ret)
['Eva', 'vaEva', 'va']
['', 'va', 'va', 'va', 'va']
然后是re.S:
text = """First line Second line Third line """ pattern = '^(.*)$' print(re.findall(pattern, text)) print(re.findall(pattern, text, flags=re.S))
打印:
[]
['First line\nSecond line\nThird line\n']
^匹配的是字符串的头部,$匹配的是字符串的尾部,.*按理应该能匹配所有字符,但唯独一个例外,. 点号无法匹配换行符\n。恰巧text中有三个换行符,所以第一个print打印[]。
第二个print则使用了re.S,表示给.点号增加功能,使其可以匹配换行符,因此第二行打印的是全部字符串。
然后是re.M:
re.M做的事情是: 让^匹配每行的开头,$匹配每行的结尾。
text = """First line Second line Third line """ pattern = '^(.*)$' print(re.findall(pattern, text)) print(re.findall(pattern, text, flags=re.M))
打印:
[]
['First line', 'Second line', 'Third line', '']
换句话说,使用了 re.M以后,运行效果看起来就像是程序首先根据换行符把字符串拆分成了多个子字符串,然后再在子字符串中执行正则表达式。
然后是re.L:
如果不加任何flags,默认使用的是Unicode,也就是re.U。re.U表示\w,\W,\b,\B,\s,\S这些字符的含义在全世界通用。
如果改为re.L,则表示说这些字符不是通用的,需要具体情况具体分析。比如对于韩国的字符,怎么匹配;对于美国的字符,这么匹配。
然后是re.X:
这个选项忽略规则表达式中的空白和注释,并允许使用 ’#’ 来引导一个注释。这样可以让你把规则写得更美观些。
import re rc = re.compile(r""" # start a rule /d+ # number | [a-zA-Z]+ # word """, re.X)
# 在编译的时候,加入了re.X模式,我们在里面填写注释,方便理解
res = rc.match('aaaa') print(res.group()) # 打印结果 aaaa Process finished with exit code 0 # 匹配空格 import re rc = re.compile(r""" # 开始匹配规则 # 匹配一个或多个空格,也可以用"\s+"代替 \ + """, re.X)
# 反斜杠转义空格 res = rc.match(' 11') # 字符串包含三个空格
其他小点



 浙公网安备 33010602011771号
浙公网安备 33010602011771号