
Python基础-day08
只读模式:r
f = open('test.log', 'r')
ret = f.read()
print(ret)
f.close()
文件内容为:
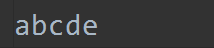
打印结果为:

从头往尾读。
如果文件不存在,就报错。
只写模式:w
如果test.log存在,写入的内容会覆盖test.log中的内容。
文件内容:
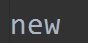
f = open('test.log', 'w')
f.write('test')
f.close()
再次查看文件内容:
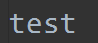
如果test.log不存在,会新建文件,然后写入内容。
f = open('test.txt', 'w')
f.write('test')
f.close()
文件内容:
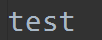
读写模式:r+
对于test.log,我们知道文件内容是test。
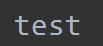
f = open('test.log', 'r+')
ret = f.read()
f.write('write')
f.close()
我们先读取文件内容,然后再写入write字符串。
检查文件内容:
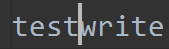
当我们read()时,光标移动到了最后面,此时执行write(),就从最后面开始写,于是write被添加到了test的后面。
写读模式:w+
已知文件内容为如下:
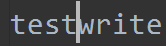
f = open('test.log', 'w+')
f.write('long')
ret = f.read()
print(ret)
f.close()
检查文件内容:
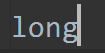
说明文件内容被完全覆盖了,所以第二步的读取工作,读取到的是一个空字符串。
只追加模式:a
源文件内容:
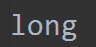
f = open('test.log', 'a')
f.write('long')
f.close()
查看文件内容:
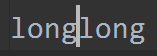
追加的原理是:先将光标移到最后,然后写入内容。
追加,写:a+
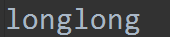
f = open('test.log', 'a+')
f.write('long')
f.close()
这是追加写。(先将光标移动到最后,然后写入内容)
此时文件内容为:
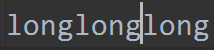
追加,读:a+
已知文件内容:
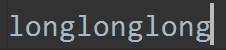
f = open('test.log', 'a+')
ret = f.read()
print(ret)
f.close()
打印:

打印空字符串。我们的光标移动到了最后,所以什么都读取不到。
截止这里,上面有6种组合。
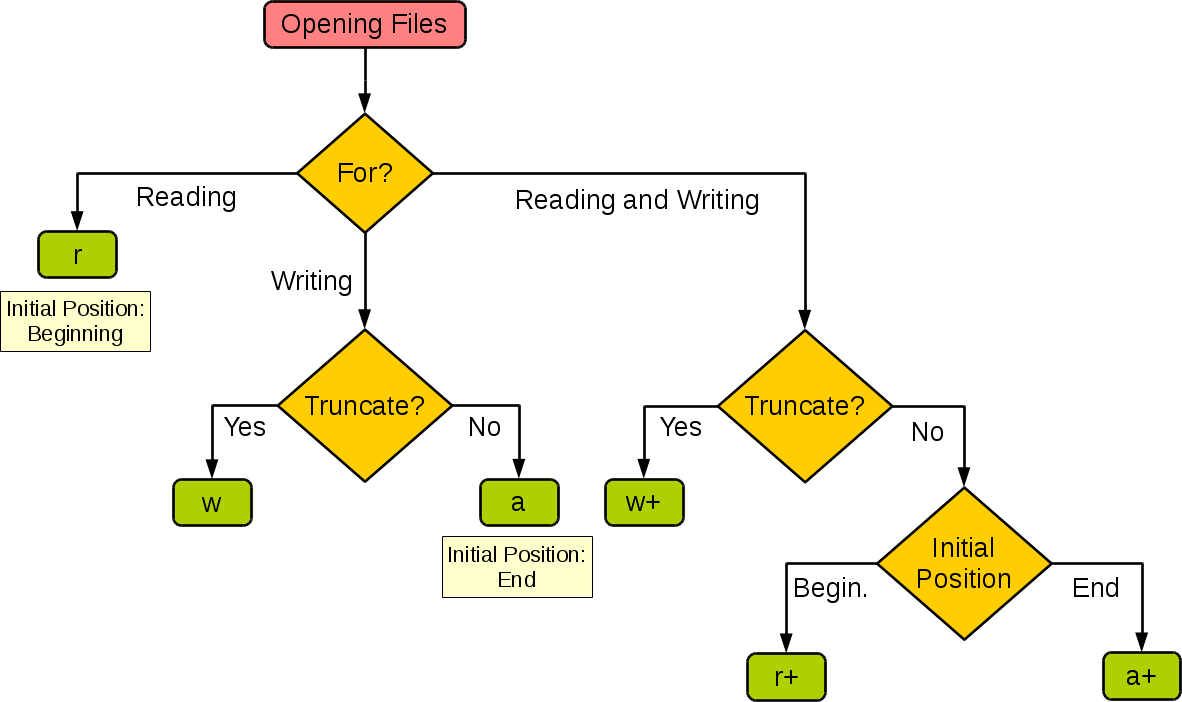
解释:
打开文件,如果是要读,那么直接用r。初始位置在开头。
打开文件,如果是要写:
如果要清空源文件内容,就直接用w。
如果不想要清空源文件内容,就用a。
打开文件,如果是要读写:
如果想清空源文件内容,那么就用w+模式。(先写入的话,文件会被清空,再读的话,什么都读不到)。
如果不想清空源文件内容,且同时决定开始的位置在头部,此时用r+模式。
如果不想清空源文件内容,且同时决定开始的位置在尾部,此时用a+模式。
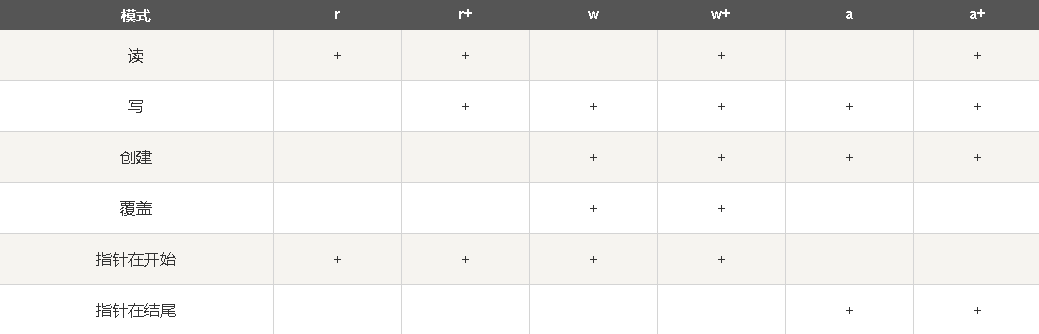
图片参考自:https://www.runoob.com/python/python-files-io.html
读取指定数量的字符:
f = open('test.log', 'r', encoding='utf-8')
ret = f.read(3)
print(ret)
f.close()
如果文件中是汉字,则读取3个汉字。
如果文件中是字母,则读取3个字母。
已知文件内容为:
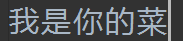
f = open('test.log', 'r', encoding='utf-8')
f.seek(3)
ret = f.read()
print(ret)
f.close()
先移动光标到3个字节后,然后开始读:
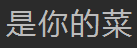
因为汉字是一个字占3个字节,所以读出来的内容是这些。
文件传输中的断点续传就利用到了三个方法:
f.seek() # 定位到指定的字节处
f.tell() # 返回当前的位置
f.read() # 读取指定的字节数
f.read() # 一次性全部读出来
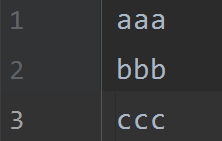
这是源文件中的内容,注意最后一行没有换行符。
f = open('test.log', 'r', encoding='utf-8')
ret = f.read()
print(ret)
打印结果:
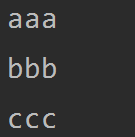
f.readline() # 一行一行读
f = open('test.log', 'r', encoding='utf-8')
ret = f.readline()
print(ret)

注意,后面有一个换行符,也就是,f.readline()读取的一行中是包含有换行符的。
这个换行符不是凭空多出来的,是因为源文件中确实有,所以被读出来的。
如果要读多行,就要运行多次readline()。
每一行在打印时,都会将换行符\n体现出来。
f = open('test.log', 'r', encoding='utf-8')
ret1 = f.readline()
ret2 = f.readline()
ret3 = f.readline()
print(ret1)
print(ret2)
print(ret3)
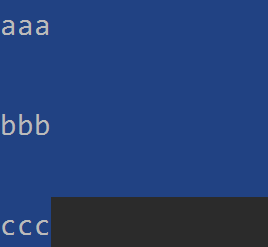
唯独ccc没有换行符,因为源文件中没有。
f.readlines() # 读取多行
其实就是多个readline()的混合体。
上面的三个readline()用一个readlines()就解决了,只不过将它们组成了一个列表。
而内容就是这三个readline()读取的内容。
f = open('test.log', 'r', encoding='utf-8')
ret1 = f.readlines()
print(ret1)

看到了吗?就是这种效果。
f.truncate() - 未实验通
保留文件中指定数量的字符。
f.truncate(5) # 保留5个字符,删除之后的所有的字符
f.truncate(0) # 保留0个字符,也就是清空文件

等效于遍历f.readlines()的结果【一个列表】。
工作中,不要用read(),如果文件太大,可能会死机,所以最好用readline(),或者循环去读。





 浙公网安备 33010602011771号
浙公网安备 33010602011771号