
Python基础-day06
python2
python3
python2
print(a) and print a
range()
xrange() 生成器
raw_input()
python3
print(a)
range()
input()
= 赋值
== 比较值是否相等
is 比较内存地址(比较两个对象是否为同一个)
id()
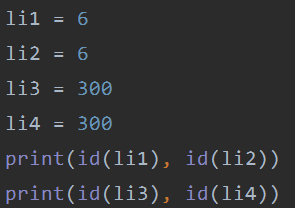
数字
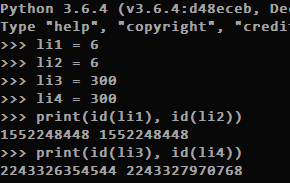
字符串
其他类型
pycharm是辅助工具,有时候不准,还是得借助原生的python语法。

这个就不准。
这个才是准的。
这就是数字的小数据池概念。
范围 -5 -- 256
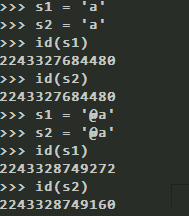
字符串也有小数据池概念。
1、不能有特殊字符。(比如@ #等)
2、s * 20 是同一个,s * 21就不是同一个了。
在一定范围内减少内存消耗。
编码复习
ascii
A: 00000010 8位 一个字节
unicode
A : 00000000 00000001 00000010 00000100 32位 四个字节
中: 00000000 00000001 00000010 00000110 32位 四个字节
utf-8
A: 0010 0000 8位 一个字节
中: 00000001 00000010 00000110 24位 三个字节
gbk
A: 00000110 8位 一个字节
中: 00000010 00000110 16位 两个字节
这些编码之间如何进行转码呢?转换的原理是什么?
相当于四个密码本,无法互通。
1、各个编码之间的二进制,是不能互相识别的,会产生乱码。
2、文字的传输(网络传输)和储存(硬盘存储)是0101格式。
传输和储存的格式不能是unicode(太大,占空间),只能是utf-8、gbk、
gb2312、ascii等。记住一句:不能用unicode。
python3:
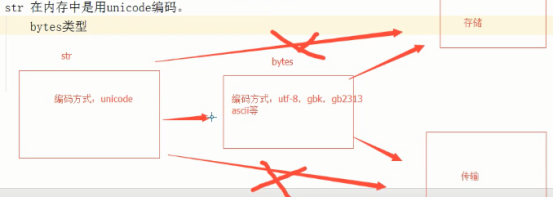
1、str在内存中是以unicode的形式存在。
我们看到的文本文件,它的内容是一个大字符串。
所以在我内存中的字符串数据(unicode编码)是不能直接传输给你的,我需要
转换一下编码,比如转成utf-8、gbk等,然后再传给你。
2、bytes类型
新的数据类型。
和str很像,区别就是编码方式。
对于英文
str : 表现形式 s = 'hello'
编码方式 01010101 unicode
bytes 表现形式 s= b'hello'
编码方式 00010101 utf-8 gbk
对于中文
str : 表现形式 s = '中国'
编码方式 0101010101 unicode
bytes: 表现形式 s = b'x\e91\e91'
编码方式 00010001 utf-8 gbk
s1 = 'yang'
# encode 编码,将str --> bytes,可以设置编码方式
s11 = s1.encode('utf-8')
s2 = '中国'
# encode 编码,将str --> bytes,可以设置编码方式
s22 = s2.encode('utf-8')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号