

scrapy爬虫框架使用
一、scrapy框架
1.什么是scrapy:
爬虫中封装好的一个明星框架。功能:高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
2.使用方法:
安装:
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
安装scrapy:pip install scrapy
安装完成后在终端输入scrapy如果没有报错即安装成功。
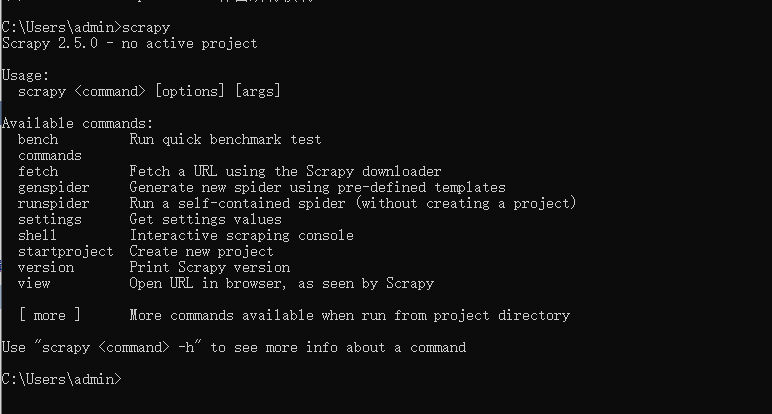
创建项目:
输入 scrapy startprojet projectName 创建项目

创建爬虫文件:cd至spiders文件夹下,在终端输入 scrapy genspider spidername www.xxx.com 用以创建爬虫文件。

二、数据解析
此处使用汽x之家做个样例
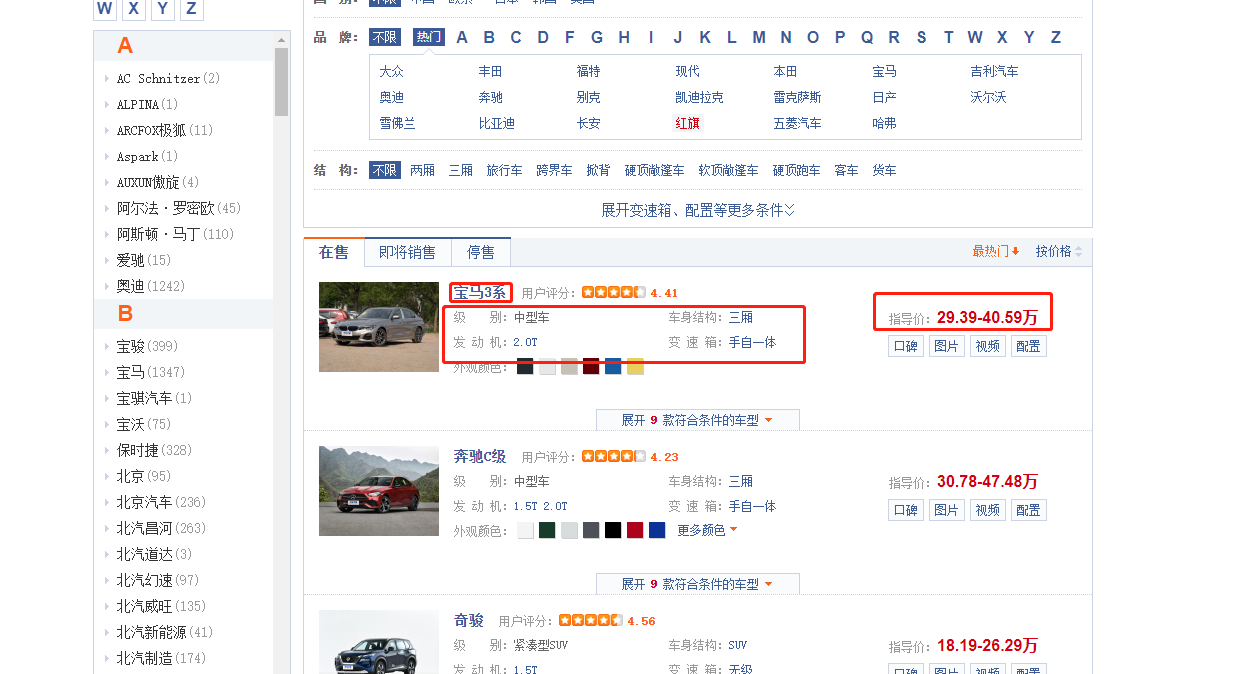
通过数据解析来获取网站中的汽车名称,级别,发动机,车身结构,变速箱以及售价数据
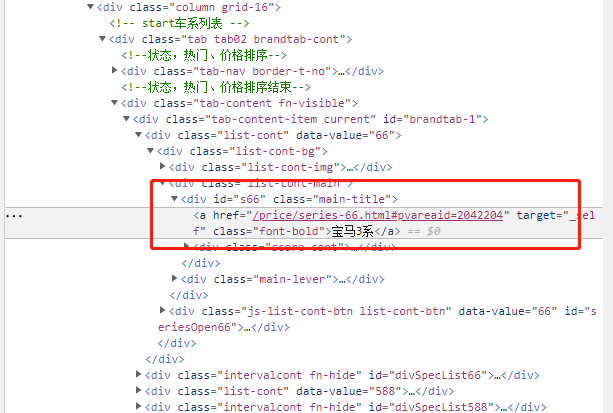
通过浏览器的抓包工具可已看出将要爬取数据的所在位置信息
在spider文件中使用小xpath表达式来解析想要获取的数据
import scrapy
class HomeStartSpider(scrapy.Spider):
name = 'home_start'
# 此处为允许使用的url通常情况下选择注释
# allowed_domains = ['www.xxxx.com']
# 起始url
start_urls = ['https://car.autohome.com.cn/price/list-0-0-0-0-0-0-0-0-0-0-0-0-0-0-0-1.html']
def parse(self, response):
#编写xpath表达式
div = response.xpath('//div[@id="brandtab-1"]/div[@class="list-cont"]')
for div_list in div:
# 汽车的详细信息地址
detail_url = 'https://car.autohome.com.cn/' + div_list.xpath('./div/div[2]/div[1]/a/@href').extract_first()
#汽车名称
car_name = div_list.xpath('./div/div[2]/div[1]/a/text()').extract_first()
#汽车级别
car_level = div_list.xpath('./div/div[2]/div[2]/div/ul/li[1]/span/text()').extract_first()
#车身结构
car_body = div_list.xpath('./div/div[2]/div[2]/div/ul/li[2]/a/text()').extract_first()
#发动机
car_engine = div_list.xpath('./div/div[2]/div[2]/div/ul/li[3]/span/a/text()').extract_first()
#变速箱
trancase = div_list.xpath('./div/div[2]/div[2]/div/ul/li[4]/a/text()').extract_first()
#价格
carprice = div_list.xpath('./div/div[2]/div[2]/div[2]/div/span/span/text()').extract_first()
print(detail_url,car_name,car_level,car_body,car_engine,trancase,carprice)
在终端运行spider文件查看是否成功

三、持久化存储
scrapy 的持久化存储分类基于管道存储,和基于终端指令存储
基于终端指令存储方式简单便捷但是局限性强;持久化存储对应的文本文件的类型只可以为:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle
基于终端的存储方式
C:\Users\admin\Desktop\pythonProject2\homecar\homecar\spiders>scrapy crawl home_start -o xxx.csv
运行后即可在文件夹下查看到保存好的数据

基于管道的持久化存储
.items:存储解析到的页面数据
.pipelines:处理持久化存储的相关操作
.代码实现流程:
1.将解析到的页面数据存储到items对象
2.使用yield关键字将items提交给管道文件进行处理
3.在管道文件中编写代码完成数据存储的操作
4.在配置文件中开启管道操作
在homestart.py中使用将汽车的信息穿入item
import datetime
from TJJ.items import TjjItem
import scrapy
class TjjcjSpider(scrapy.Spider):
name = 'tjjcj'
# 此处为允许使用的url通常情况下选择注释
# allowed_domains = ['www.xxxx.com']
# 起始url
start_urls = ['https://car.autohome.com.cn/price/list-0-0-0-0-0-0-0-0-0-0-0-0-0-0-0-1.html']
def parse(self, response):
# 编写xpath表达式
div = response.xpath('//div[@id="brandtab-1"]/div[@class="list-cont"]')
for div_list in div:
# 汽车的详细信息地址
detail_url = 'https://car.autohome.com.cn/' + div_list.xpath('./div/div[2]/div[1]/a/@href').extract_first()
# 汽车名称
car_name = div_list.xpath('./div/div[2]/div[1]/a/text()').extract_first()
# 汽车级别
car_level = div_list.xpath('./div/div[2]/div[2]/div/ul/li[1]/span/text()').extract_first()
# 车身结构
car_body = div_list.xpath('./div/div[2]/div[2]/div/ul/li[2]/a/text()').extract_first()
# 发动机
car_engine = div_list.xpath('./div/div[2]/div[2]/div/ul/li[3]/span/a/text()').extract_first()
# 变速箱
trancase = div_list.xpath('./div/div[2]/div[2]/div/ul/li[4]/a/text()').extract_first()
# 价格
carprice = div_list.xpath('./div/div[2]/div[2]/div[2]/div/span/span/text()').extract_first()
print(detail_url, car_name, car_level, car_body, car_engine, trancase, carprice)
item = TjjItem()
item['detail_url'] = detail_url
item['car_name'] = car_name
item['car_level'] = car_level
item['car_body'] = car_body
item['car_engine'] = car_engine
item['trancase'] = trancase
item['carprice'] = carprice
yield item
Items.py 中的将接收的文本传入管道
import scrapy
class TjjItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
detail_url = scrapy.Field()
car_name = scrapy.Field()
car_level = scrapy.Field()
car_body = scrapy.Field()
car_engine = scrapy.Field()
trancase = scrapy.Field()
carprice = scrapy.Field()
pipelines.py中对管道进行配置
class TjjPipeline(object):
fp = None
# 整个爬虫文件中,只会在开始爬虫的时候调用一次
def open_spider(self, spider):
print('开始爬虫')
self.fp = open('./homecar_pipe.txt', 'w', encoding='utf-8')
# 该方法就可以接受爬虫文件中提交过来的item对象,并且对item对象中存储的页面数据进行持久化存储
# 参数:item表示的就是接收到的item对象
# 每当爬虫文件向管道提交一次item,则该方法就会被执行一次
def prcess_item(self, item, spider):
detail_url = item['detail_url']
car_name = item['car_name']
car_level = item['car_level']
car_body = item['car_body']
car_engine = item['car_engine']
trancase = item['trancase']
carprice = item['carprice']
print(detail_url)
self.fp.write(detail_url + ":" + car_name + ":" + car_level + ":" + car_body + ":" +car_engine + ":" + trancase + ":" + carprice)
return item
# 整个爬虫过程中,该方法只会在开始爬虫的时候被调用一次
def close_spider(self, spider):
print('爬虫结束')
self.fp.close()
settings.py中开启管道服务
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'TJJ.pipelines.TjjPipeline': 300,
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号