
linux中安装kafka全教程
方式一:普通安装
1、下载kafka安装包:https://kafka.apache.org/downloads.html

然后移动到linux指定的目录中:
2、解压
tar -zxvf kafka_2.13-2.5.0.tgz
3、zookeeper配置
进去到config目录:cd config
// 复制非注释配置到新的文件中
cat zookeeper.properties | grep -v '#' >> zk.properties
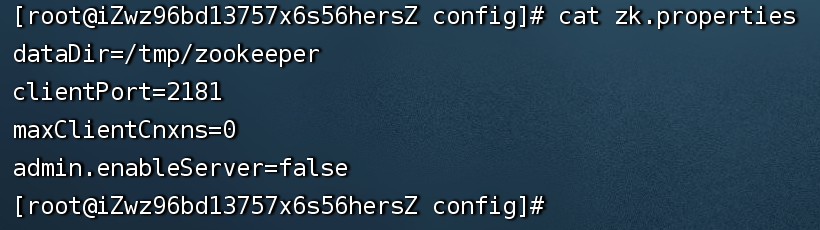
zk.properties的具体内容如下:
4、启动zookeeper
nohup ./bin/zookeeper-server-start.sh config/zk.properties 1>/dev/null 2>&1 &
5、查询 zookeeper 是否启动
6、kafka配置
进去到config目录:cd config
// 复制非注释配置到新的文件中
cat server.properties | grep -v '#' >> ka.properties
ka.properties的具体内容如下:
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
7、启动kafka
nohup ./bin/kafka-server-start.sh config/ka.properties 1>/dev/null 2>&1 &
8、补充
扩展1:这里可以编写一个启动脚本来启动:
# 创建一个脚本文件
vi kafkastart.sh
# 脚本内容如下
# 启动zookeeper
/usr/local/kafka/kafka_2.12-2.5.0/bin/zookeeper-server-start.sh /usr/local/kafka/kafka_2.12-2.5.0/config/zk.properties &
# 等3秒后执行
sleep 3
#启动kafka
/usr/local/kafka/kafka_2.12-2.5.0/bin/kafka-server-start.sh /usr/local/kafka/kafka_2.12-2.5.0/config/ka.properties &
# 关闭保存后,给脚本文件赋予权限
chmod 777 kafkastart.sh
扩展2:这里还可以编写一个关闭脚本来关闭服务:
# 创建一个脚本文件
vi kafkastop.sh
# 脚本内容如下
#关闭zookeeper
/usr/local/kafka/kafka_2.12-2.5.0/bin/zookeeper-server-stop.sh /usr/local/kafka/kafka_2.12-2.5.0/config/zookeeper.properties &
#等3秒后执行
sleep 3
#关闭kafka
/usr/local/kafka/kafka_2.12-2.5.0/bin/kafka-server-stop.sh /usr/local/kafka/kafka_2.12-2.5.0/config/server.properties &
# 关闭保存后,给脚本文件赋予权限
chmod 777 kafkastop.sh
9、验证是否启动成功
启动日志:

检查进程:

测试api:
创建一个test的topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test

查询创建的topic:
./kafka-topics.sh --list --zookeeper localhost:2181

方式一总结:
1、启动的时候报错,因为没安装jdk环境

参考:linux下安装jdk
## 方式二:使用docker安装 ### 安装JDK
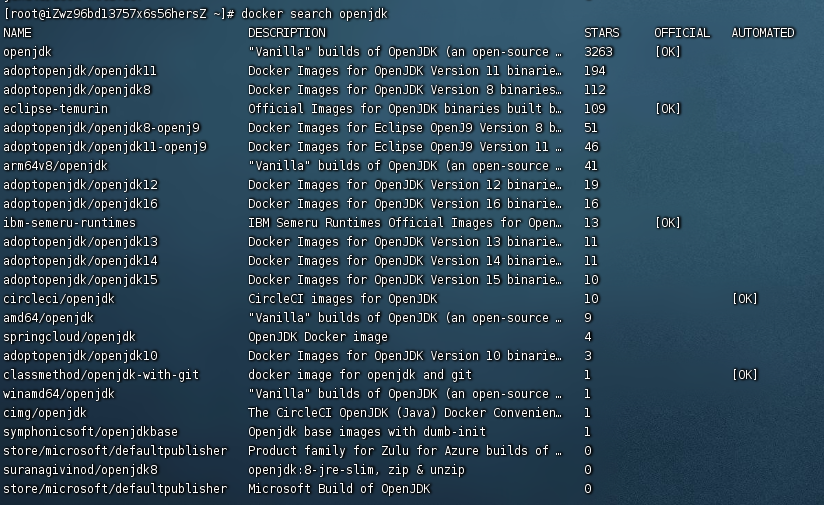
[先搜一下]
docker search openjdk
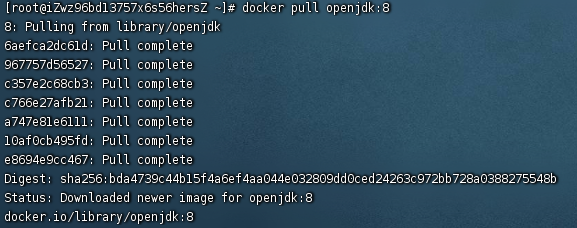
[拉镜像]
docker pull openjdk:8
[创建jdk容器]
命令:docker run -d -it --name java-8 openjdk:8
说明:docker run.. 命令用于创建一个容器,--name表示给容器的命名,后面openjdk:8表示要使用的镜像

[创建成功后,进去查看下版本并退出]
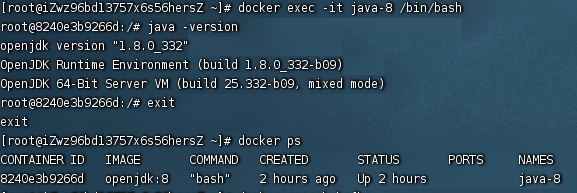
命令:docker exec -it java-8 /bin/bash
说明:进去容器内部,java-8为容器名
命令:java -version
说明:查看jdk版本的命令
命令:exit
说明:退出容器内部,返回服务器终端
至此,docker中的jdk安装完毕
安装zookeeper
前言:
1、为什么要使用zookeeper?,因为kafka使用zookeeper保存集群的元数据信息和消费者信息。
2、能不能不安装zookeeper?可以,kafka中自带了zookeeper,但是不推荐,考虑性能,资源等问题,考虑自行安装zookeeper集群。
3、能不能不使用zookeeper?这个也可以,kafka2.8以上版本就去除了对zookeeper的依赖。这里不多赘述。
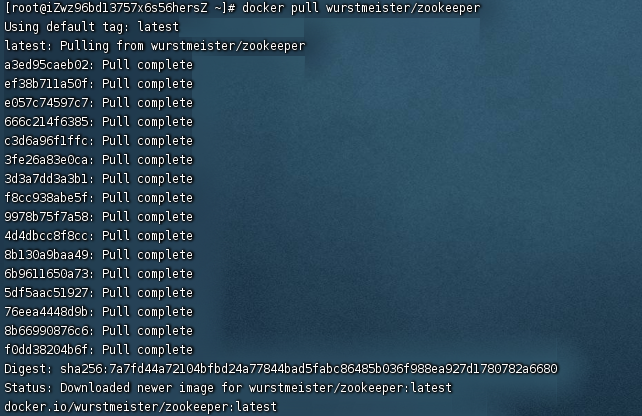
[拉镜像]
命令:docker pull wurstmeister/zookeeper
说明:wurstmeister/zookeeper是常用的zookeeper镜像
[创建zookeeper容器]
命令:docker run -d --name zookeeper -p 2181:2181 wurstmeister/zookeeper
说明:-d:后台方式运行
--name:为容器命名
-p:端口映射,格式为:主机端口:容器端口
最后接的是镜像名
连接起来理解:通过wurstmeister/zookeeper镜像构建一个名为zookeeper的容器,以后台方式运行,并映射的端口为2181
zookeeper扩展之集群构建
此章节为扩展篇,单点的zookeeper已经够用了,但集群的zookeeper将会提高kafka的可用性。集群构建方式有两种,一个个的构建结点,此种方式会比较麻烦,第二就是通过docker-compose的方式来构建。
方式一:一个个建结点
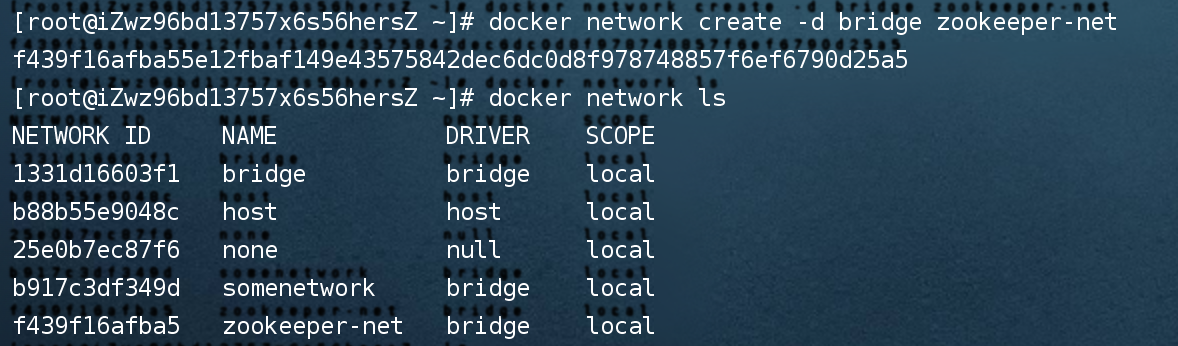
[建网络]
说明:先建网络的目的是为了让集群中的各节点能够互通互联。
命令:docker network create --driver bridge --subnet=172.19.0.0/16 --gateway=172.19.0.1 zookeeper-net
说明:构建一个名为zookeeper-net的网络,网络类型为bridge
命令:docker network ls
说明:查看网络列表
[一个个建容器]
命令:
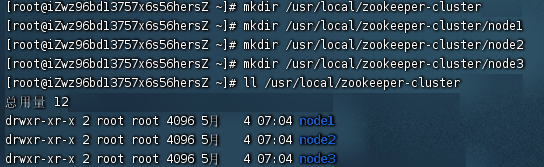
mkdir /usr/local/zookeeper-cluster
mkdir /usr/local/zookeeper-cluster/node1
mkdir /usr/local/zookeeper-cluster/node2
mkdir /usr/local/zookeeper-cluster/node3
ll /usr/local/zookeeper-cluster
说明:建集群主目录与各节点的目录,并通过ll命令查看
命令:
docker images
说明:查看已经pull下来的镜像,复制wurstmeister/zookeeper的镜像ID。以下命令的末尾串即为此镜像ID(3f43f72cb283)
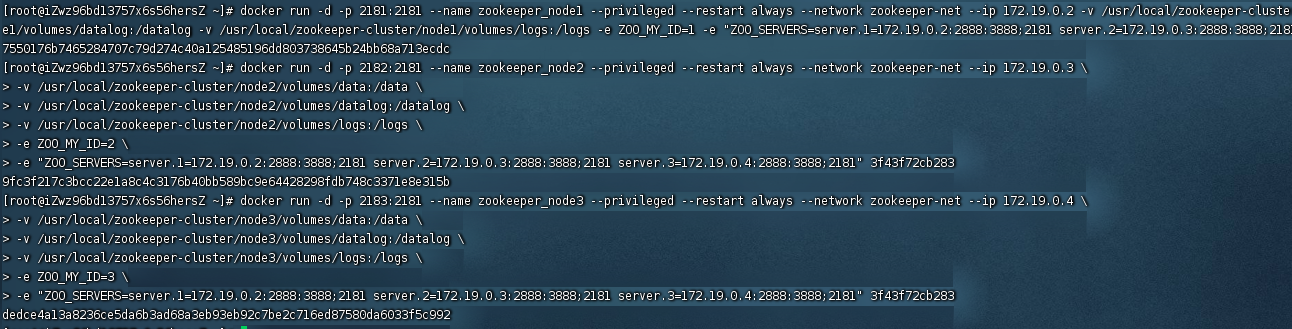
命令:docker run -d -p 2181:2181 --name zookeeper_node1 --privileged --restart always --network zookeeper-net --ip 172.19.0.2
-v /usr/local/zookeeper-cluster/node1/volumes/data:/data
-v /usr/local/zookeeper-cluster/node1/volumes/datalog:/datalog
-v /usr/local/zookeeper-cluster/node1/volumes/logs:/logs
-e ZOO_MY_ID=1
-e "ZOO_SERVERS=server.1=172.19.0.2:2888:3888;2181 server.2=172.19.0.3:2888:3888;2181 server.3=172.19.0.4:2888:3888;2181" 3f43f72cb283
说明:运行集群的zookeeper实例1,设置ip为172.18.0.2,主机的目录/usr/local/zookeeper-cluster/node1/volumes/data映射到容器的/data,主机的目录...,主机的2181端口映射到容器的2181,--restart always设置重启策略,设置此容器的网络为zookeeper-net,名称为zookeeper_node1,-e表示设置容器的环境变量,ZOO_MY_ID 和 ZOO_SERVERS 是搭建 ZK 集群需要设置的两个环境变量,其中 ZOO_MY_ID 表示 ZK 服务的 id,它是1-255 之间的整数,必须在集群中唯一;ZOO_SERVERS 是ZK 集群的主机列表,2888是zookeeper容器间通信的端口,3888是zookeeper选举投票的端口,一般来说都是固定的。
命令:docker run -d -p 2182:2181 --name zookeeper_node2 --privileged --restart always --network zookeeper-net --ip 172.19.0.3
-v /usr/local/zookeeper-cluster/node2/volumes/data:/data
-v /usr/local/zookeeper-cluster/node2/volumes/datalog:/datalog
-v /usr/local/zookeeper-cluster/node2/volumes/logs:/logs
-e ZOO_MY_ID=2
-e "ZOO_SERVERS=server.1=172.19.0.2:2888:3888;2181 server.2=172.19.0.3:2888:3888;2181 server.3=172.19.0.4:2888:3888;2181" 3f43f72cb283
命令:docker run -d -p 2183:2181 --name zookeeper_node3 --privileged --restart always --network zookeeper-net --ip 172.19.0.4
-v /usr/local/zookeeper-cluster/node3/volumes/data:/data
-v /usr/local/zookeeper-cluster/node3/volumes/datalog:/datalog
-v /usr/local/zookeeper-cluster/node3/volumes/logs:/logs
-e ZOO_MY_ID=3
-e "ZOO_SERVERS=server.1=172.19.0.2:2888:3888;2181 server.2=172.19.0.3:2888:3888;2181 server.3=172.19.0.4:2888:3888;2181" 3f43f72cb283
方式二:用docker-compose
暂略
安装kafka
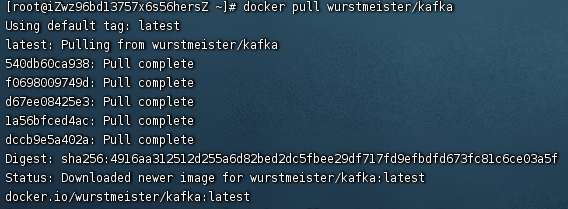
[下载kafka镜像]
命令:docker pull wurstmeister/kafka
说明:wurstmeister/kafka为常用的kafka镜像
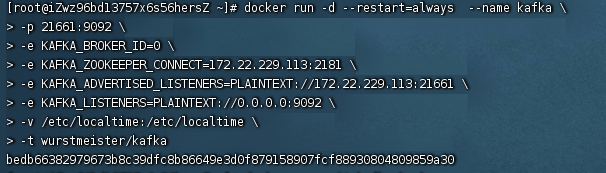
[构建kafka容器]
命令:docker run -d --restart=always --name kafka
-p 21661:9092
-e KAFKA_BROKER_ID=0
-e KAFKA_ZOOKEEPER_CONNECT=172.22.229.113:2181
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.22.229.113:21661
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
-v /etc/localtime:/etc/localtime
-t wurstmeister/kafka
说明:
-p 21661:9092 kafka的 9092 端口映射为 21661 端口
-e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka用BROKER_ID来区分自己 , 如需配置kafka集群可 修改此id 和 上述 21661 端口号映射即可部署集群
-e KAFKA_ZOOKEEPER_CONNECT=172.22.229.113:2181 配置zookeeper连接地址
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.22.229.113:21661 把kafka的地址注册给zookeeper,如果是远程访问要改成外网IP,否则可能出现无法连接
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口
-v /etc/localtime:/etc/localtime 容器时间同步虚拟机的时间
[测试发布与订阅消息]
命令:docker exec -it kafka bash
cd /opt/kafka/bin
./kafka-console-producer.sh --broker-list localhost:9092 --topic test_topic
说明:进入kafka容器内部,进入指定目录,创建一个主题为test_topic,并输入消息Test Message 1(见下图)

命令:./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --from-beginning
说明:消息主题为test_topic的消息

总结
至此,kafka的安装完毕,安装kafka只是使用它的第一步,而且我安装的是单节点,并没有构建kafka集群,对于docker-compose来构建集群比一个个建结点要方便,推荐使用。
推荐阅读
1、懂了这三点,kafka的运行脉络一清二楚,公司封装的框架也能看得懂了
2、kafka那些重要的概念,broker、偏移量、主题与分区、日志片段
3、kafka几个最想问且最想知道的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号