MHA
#使用Keepalived,backup所在主机会造成资源浪费
#MHA manager管理主库上的node节点(连接),集群中所有的机器都要部署node节点,node节点才是管理集群机器的
#manage可以放在集群中任意一台机器,但是不要和主库放到一起
一、MHA介绍
准备三台机器:
第一台:IP:10.0.0.51 db01 '2G内存'
第二台:IP:10.0.0.52 db02 2G内存
第三台:IP:10.0.0.53 db03 2G内存
1.简介
MHA能够在较短的时间内实现'自动故障检测和故障转移',通常在10-30秒(3*3+2 )以内;在复制框架中,MHA能够很好地解决复制过程中的'数据一致性问题',由于不需要在现有的replication中添加额外的服务器,仅需要一个'manager节点',而一个Manager能管理多套复制,所以能大大地节约服务器的数量;
另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA还提供'在线主库切换'的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。(manager与主库,1次维持,3次重新开启)
当Master出现故障时,它可以'自动将最新数据的Slave提升为新的Master',然后将所有其他的Slave重新指向新的Master。
整个故障转移过程对应用程序是完全透明的。(#可以通过日志查看)
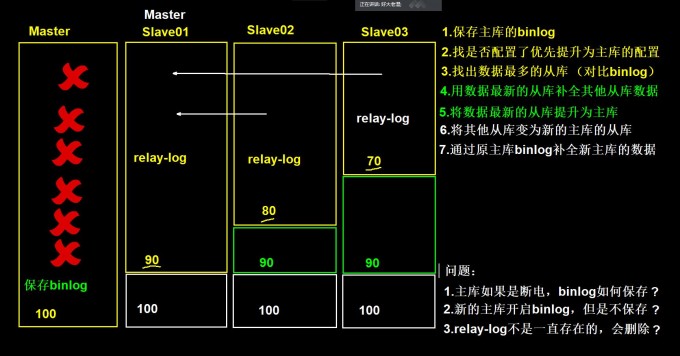
2.原理
1.把宕机的'master二进制日志保存'下来。
2.找到binlog位置点'最新的'slave。
3.在binlog位置点'最新的slave上'用relay-log(差异日志)'修复其它slave'。
4.将宕机的'master上保存下来的二进制日志'恢复到含有'最新位置点的slave上'。
5.将含有最新位置点binlog所在的'slave提升为master'。
6.将其它slave'重新指向'新提升的master,并'开启主从复制'。
3.架构
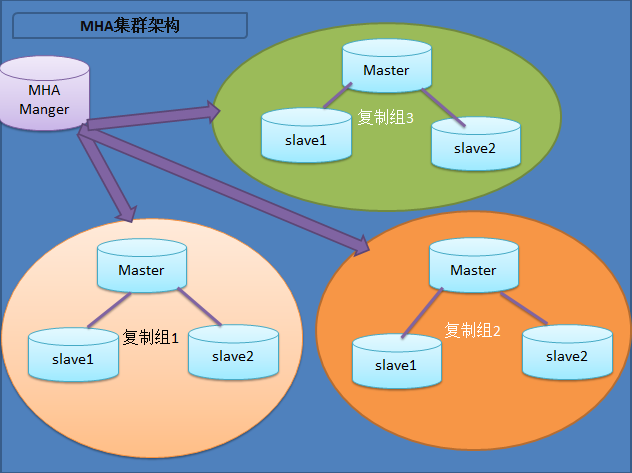
1.MHA属于C/S结构
2.一个manager节点可以管理'多套集群'
3.集群中所有的机器'都要部署node节点'
4.'node节点才是管理集群机器的'
5.manager节点通过'ssh连接'node节点,管理
6.manager可以部署在集群中'除了主库'以外的任意一台机器上
4.工具
1)manager节点的工具
#上传MHA工具包
RZ
#解压tar包,查看可执行文件
[root@db01 ~]# ll mha4mysql-manager-0.56/bin/
#检查主从状态
masterha_check_repl
#检查ssh连接(配置免密)
masterha_check_ssh
#检查MHA状态(只检查)
masterha_check_status
#自动删除死掉机器 配置文件中的配置
masterha_conf_host
...
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
#mha启动程序
masterha_manager
#检测master是否宕机(1次维护,3次启动)
masterha_master_monitor
#手动故障转移
masterha_master_switch
#建立TCP连接从远程服务器(只连接)
masterha_secondary_check
#关闭进程的程序
masterha_stop
2)node节点工具
#解压node安装包
[root@db01 ~]# ll mha4mysql-node-0.56/bin/
#node节点对比relay-log,找到最新的relay-log
apply_diff_relay_logs
#防止回滚事件
filter_mysqlbinlog
#自动删除relay-log
purge_relay_logs
#node节点自动保存binlog
save_binary_logs
5.MHA优点
1)Masterfailover and slave promotion can be done very quickly
'自动故障转移快',默认只能转移一次,删除部分配置
2)Mastercrash does not result in data inconsistency
主库崩溃不存在'数据一致性'问题
3)Noneed to modify current MySQL settings (MHA works with regular MySQL)
不需要对当前'mysql环境'做重大修改
4)Noneed to increase lots of servers
'不需要添加额外的服务器'(仅一台manager就可管理上百个replication)
5)Noperformance penalty
性能优秀,可工作在'半同步复制和异步复制和基于GTID主从复制',当监控mysql状态时,仅需要每隔N秒向master发送ping包('默认3秒'),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
6)Works with any storage engine
只要replication支持的存储引擎,MHA都支持,'不会局限于innodb'
| 主机 | 内网ip | 外网ip | 角色 |
|---|---|---|---|
| db01 | 172.16.1.51 | 10.0.0.51 | 主库 |
| db02 | 172.16.1.52 | 10.0.0.52 | 从库 |
| db03 | 172.16.1.53 | 10.0.0.53 | 从库,manager |
二、搭建MHA
1.保证主从的状态(检查)
#主库
mysql> show master status;
#从库
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#从库
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
--------------------------------------------------------------------
#主从状态可以,就可以搭建MHA
2.部署MHA之前配置(参考)
#永久设置,在mysqld标签下添加
[root@mysql-db02 ~]# vim /etc/my.cnf
[mysqld]
1.关闭从库删除relay-log的功能
relay_log_purge=0
2.配置从库只读(#可以不配置,MHA会自动设置从库权限为读写)
read_only=1
3.从库保存binlog
log_slave_updates
#临时设置
#禁用自动删除relay log 功能
set global relay_log_purge=0;
#设置只读
set global read_only=1;
set global log_slave_updates=1;(#报错)
3.配置
1)主库配置
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
skip-name-resolve
2)从库01配置
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
skip-name-resolve
3)从库02配置
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
skip-name-resolve
4.部署MHA
1)安装node节点依赖(所有机器)
[root@db01 ~]# yum install perl-DBD-MySQL -y
[root@db02 ~]# yum install perl-DBD-MySQL -y
[root@db03 ~]# yum install perl-DBD-MySQL -y
2)安装manager节点依赖(manager机器,10.0.0.53)
[root@db03 ~]# yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
3)部署node节点(所有机器)
[root@db01 ~]# rz mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# rz mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# rz mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db01 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
4)部署manager节点(manager机器,10.0.0.53)
[root@db03 ~]# rz mha4mysql-manager-0.56-0.el6.noarch.rpm
[root@db03 ~]# yum localinstall -y mha4mysql-manager-0.56-0.el6.noarch.rpm
5)配置MHA(manager机器,10.0.0.53)
#创建MHA配置目录
[root@db03 ~]# mkdir -p /service/mha
#配置MHA
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
#指定日志存放路径(MHA日志)
manager_log=/service/mha/manager
#指定工作目录
manager_workdir=/service/mha/app1
#binlog存放目录(可以分别放到下面的server1处)
master_binlog_dir=/service/mysql/data
#VIP飘移脚本
master_ip_failover_script=/service/mha/master_ip_failover
#MHA管理用户
user=mha
#MHA管理用户的密码
password=mha
#manager检测主库是否存活的时间间隔
ping_interval=2
#主从用户
repl_user=rep
#主从用户的密码
repl_password=123
#ssh免密用户
ssh_user=root
ssh_port=22
[server1]
hostname=172.16.1.51
port=3306
[server2]
candidate_master=1
check_repl_delay=0
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
#这俩放一块儿就是独裁
设置为候选master,如果设置该参数以后,发生主从切换以后'将会将此从库提升为主库',即使这个主库不是集群中事件最新的slave。
candidate_master=1
默认情况下如果一个slave落后master '100M'的relay-logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会'忽略复制延时',这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0
6)创建MHA管理用户
#主库执行即可
mysql> grant all on *.* to mha@'172.16.1.%' identified by 'mha';
mysql> select user,host from mysql.user;
+------+------------+
| user | host |
+------+------------+
| root | 127.0.0.1 |
| mha | 172.16.1.% |
| rep | 172.16.1.% |
| root | ::1 |
| | db02 |
| root | db02 |
| | localhost |
| root | localhost |
+------+------------+
#这个mha用户在3台机器上都要有,rep用户在所有机器上也都要有
#远程连接(看权限,选择连接方式)
[root@db04 bin]# mysql -umha -pmha -h172.16.1.54
#本地连接默认为localhost
[root@db04 bin]# mysql -umha
7)ssh免密(三台机器每一台都操作以下内容)
#创建秘钥对
[root@db01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
#发送公钥,包括自己
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.51
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.52
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.53
...
...
8)检测MHA状态
#检测主从
[root@db03 ~]# masterha_check_repl --conf=/service/mha/app1.cnf
Mon Jul 27 19:12:32 2020 - [warning] Global configuration file /etc/masterha_default.cnf 'not found'. Skipping.
Mon Jul 27 19:12:32 2020 - [info] 'Reading' application default configuration from /service/mha/app1.cnf.. #读取的配置文件
Mon Jul 27 19:12:32 2020 - [info] 'Reading' server configuration from /service/mha/app1.cnf..
Mon Jul 27 19:12:32 2020 - [info] MHA::MasterMonitor version 0.56.
Mon Jul 27 19:12:33 2020 - [info] 'GTID' failover mode = 0
Mon Jul 27 19:12:33 2020 - [info] 'Dead' Servers:
Mon Jul 27 19:12:33 2020 - [info] 'Alive' Servers: #总数
Mon Jul 27 19:12:33 2020 - [info] 172.16.1.52(172.16.1.52:3306)
Mon Jul 27 19:12:33 2020 - [info] 172.16.1.53(172.16.1.53:3306)
Mon Jul 27 19:12:33 2020 - [info] 172.16.1.54(172.16.1.54:3306)
Mon Jul 27 19:12:33 2020 - [info] 'Alive Slaves': #从库
Mon Jul 27 19:12:33 2020 - [info] 172.16.1.53(172.16.1.53:3306) Version=5.6.46-log (oldest major version between slaves) log-bin:enabled
Mon Jul 27 19:12:33 2020 - [info] Replicating from 172.16.1.52(172.16.1.52:3306)
Mon Jul 27 19:12:33 2020 - [info] 172.16.1.54(172.16.1.54:3306) Version=5.6.46-log (oldest major version between slaves) log-bin:enabled
Mon Jul 27 19:12:33 2020 - [info] 'Replicating from' 172.16.1.52(172.16.1.52:3306) (#谁的从库)
Mon Jul 27 19:12:33 2020 - [info] Current 'Alive Master': 172.16.1.52(172.16.1.52:3306)
Mon Jul 27 19:12:33 2020 - [info] 'Checking' slave configurations..
Mon Jul 27 19:12:33 2020 - [info] Checking replication filtering settings..
Mon Jul 27 19:12:33 2020 - [info] binlog_do_db= , binlog_ignore_db= (#过滤复制的白名单,黑名单)
Mon Jul 27 19:12:33 2020 - [info] Replication filtering 'check' ok.
Mon Jul 27 19:12:33 2020 - [info]' GTID' (with auto-pos) is not supported
Mon Jul 27 19:12:33 2020 - [info] Starting 'SSH' connection tests..
Mon Jul 27 19:12:35 2020 - [info] All SSH connection tests passed successfully.
Mon Jul 27 19:12:35 2020 - [info] 'Checking MHA Node' version..
Mon Jul 27 19:12:36 2020 - [info] Version check ok.
Mon Jul 27 19:12:36 2020 - [info] Checking SSH publickey authentication settings on the current master..
...
172.16.1.52(172.16.1.52:3306) (current master) #从库
+--172.16.1.53(172.16.1.53:3306)
+--172.16.1.54(172.16.1.54:3306)
...
Mon Jul 27 19:12:37 2020 - [warning] master_ip_failover_script is not defined.(#master_ip_failover_script VIP漂移的脚本)
Mon Jul 27 19:12:37 2020 - [warning] shutdown_script is not defined.
Mon Jul 27 19:12:37 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
#检测ssh
[root@db03 ~]# masterha_check_ssh --conf=/service/mha/app1.cnf
Mon Jul 27 11:40:06 2020 - [info] All SSH connection tests passed successfully.
9)启动MHA
#启动
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
nohup ... & #后台启动
masterha_manager #启动命令
--conf=/service/mha/app1.cnf #指定配置文件
--remove_dead_master_conf #移除挂掉的主库配置
--ignore_last_failover #忽略最后一次切换(作用于第二次主库切换)
< /dev/null > /service/mha/manager.log 2>&1 #启动日志输出到空
#MHA保护机制:
1.MHA主库切换后,'8小时'内禁止再次切换,8小时后可以正常切换
2.切换后会生成一个'锁文件',下一次启动MHA需要检测该文件是否存在
#
[root@db03 ~]# ps -ef|grep mha
root 29888 26120 0 19:35 pts/1 00:00:00 perl /usr/bin/masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
root 30405 26120 0 19:48 pts/1 00:00:00 grep --color=auto mha
[root@db03 ~]# cp /service/mha/{app1.cnf,app1.cnf.bak}
5.报错总结
1)报错1:
rep用户在主库和从库都要存在
#原因:
从库没有rep用户
#解决方式:
主库再次授权rep用户
从库配置rep用户
2)报错2:
反向解析
#原因:
连接时被反向解析
#解决方式:
[root@db01 ~]# vim /etc/my.cnf
skip-name-resolve
3)报错3:
基于GTID主从复制,配置文件漏写
#原因:
从库没有开启'保存binlog'
#解决方式:
[root@db01 ~]# vim /etc/my.cnf
log-slave-updates
4)报错4:
从库IO线程连接失败
#重启指定的mysql
/etc/init.d/mysqld restart
5)报错5:
Can''t locate MHA/BinlogManager.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at /usr/bin/apply_diff_relay_logs line 24
解决办法是在5台机器上面做软连接,把这个32位的依赖链接到64位的支持库里面去
6.测试MHA
#监控manager日志
[root@db04 ~]# tail -f /service/mha/manager
#停掉主库
/tec/init.d/mysqld stop
#查看manager的日志
Mon Jul 27 19:52:44 2020 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away)
Mon Jul 27 19:52:44 2020 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/service/mysql/data --output_file=/var/tmp/save_binary_logs_test --manager_version=0.56 --binlog_prefix=mysql-bin
Mon Jul 27 19:52:44 2020 - [info] HealthCheck: SSH to 172.16.1.52 is 'reachable'. #可达
Mon Jul 27 19:52:46 2020 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.16.1.52'' (111)) #第一次检测,不能连接到52,隔2秒检查第二次
Mon Jul 27 19:52:46 2020 - [warning] Connection failed 2 time(s)..
Mon Jul 27 19:52:48 2020 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.16.1.52' (111))
Mon Jul 27 19:52:48 2020 - [warning] Connection failed 3 time(s)..
Mon Jul 27 19:52:50 2020 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.16.1.52' (111))
Mon Jul 27 19:52:50 2020 - [warning] Connection failed 4 time(s)..
Mon Jul 27 19:52:50 2020 - [warning] Master is not reachable from health checker!
Mon Jul 27 19:52:50 2020 - [warning] 'Master' 172.16.1.52(172.16.1.52:3306) is not 'reachable'!
Mon Jul 27 19:52:50 2020 - [warning] 'SSH is reachable'.
Mon Jul 27 19:52:50 2020 - [info] Connecting to a master server failed. 'Reading configuration file' /etc/masterha_default.cnf and /service/mha/app1.cnf again, and trying to connect to all servers to check server status..
Mon Jul 27 19:52:50 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon Jul 27 19:52:50 2020 - [info] 'Reading' application default configuration from /service/mha/app1.cnf..
Mon Jul 27 19:52:50 2020 - [info] 'Reading' server configuration from /service/mha/app1.cnf..
Mon Jul 27 19:52:51 2020 - [info] 'GTID' failover mode = 0
Mon Jul 27 19:52:51 2020 - [info] 'Dead Servers':
Mon Jul 27 19:52:51 2020 - [info] 172.16.1.52(172.16.1.52:3306)
Mon Jul 27 19:52:51 2020 - [info] 'Alive Servers':
Mon Jul 27 19:52:51 2020 - [info] 172.16.1.53(172.16.1.53:3306)
Mon Jul 27 19:52:51 2020 - [info] 172.16.1.54(172.16.1.54:3306)
Mon Jul 27 19:52:51 2020 - [info] 'Alive Slaves':
Mon Jul 27 19:52:51 2020 - [info] 172.16.1.53(172.16.1.53:3306) Version=5.6.46-log (oldest major version between slaves) log-bin:enabled
Mon Jul 27 19:52:51 2020 - [info] Replicating from 172.16.1.52(172.16.1.52:3306)
Mon Jul 27 19:52:51 2020 - [info] 172.16.1.54(172.16.1.54:3306) Version=5.6.46-log (oldest major version between slaves) log-bin:enabled
Mon Jul 27 19:52:51 2020 - [info] 'Replicating from '172.16.1.52(172.16.1.52:3306) #主库是谁
Mon Jul 27 19:52:51 2020 - [info] Checking slave configurations..
Mon Jul 27 19:52:51 2020 - [info] Checking replication filtering settings..
Mon Jul 27 19:52:51 2020 - [info] Replication filtering check ok.
Mon Jul 27 19:52:51 2020 - [info] 'Master is down!' #master死了
Mon Jul 27 19:52:51 2020 - [info] 'Terminating monitoring script.' #监控脚本
Mon Jul 27 19:52:51 2020 - [info] Got exit code 20 (Master dead).
Mon Jul 27 19:52:51 2020 - [info] MHA::MasterFailover version 0.56.
Mon Jul 27 19:52:51 2020 - [info] 'Starting master failover.' #开启主库切换
..................
Mon Jul 27 19:52:56 2020 - [info] mysql-bin.000003:120 #新库位置点
Mon Jul 27 19:52:56 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.16.1.53', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=120, MASTER_USER='rep', MASTER_PASSWORD='xxx'; #MHA自动帮从库执行
...
Mon Jul 27 19:52:58 2020 - [info] Resetting slave 172.16.1.54(172.16.1.54:3306) and starting replication from the new master 172.16.1.53(172.16.1.53:3306).. #开启slave
Mon Jul 27 19:52:58 2020 - [info] 'Executed' CHANGE MASTER.
Mon Jul 27 19:52:58 2020 - [info] Slave started.
Mon Jul 27 19:52:58 2020 - [info] End of log messages from 172.16.1.54.
Mon Jul 27 19:52:58 2020 - [info] -- Slave recovery on host 172.16.1.54(172.16.1.54:3306) succeeded.
Mon Jul 27 19:52:58 2020 - [info] All new slave servers recovered successfully. #新的主从关系恢复
Mon Jul 27 19:52:58 2020 - [info]
Mon Jul 27 19:52:58 2020 - [info] * Phase 5: New master cleanup phase..
Mon Jul 27 19:52:58 2020 - [info]
Mon Jul 27 19:52:58 2020 - [info] Resetting slave info on the new master..
Mon Jul 27 19:52:58 2020 - [info] 172.16.1.53: Resetting slave info succeeded. #修改配置文件
Mon Jul 27 19:52:58 2020 - [info] Master failover to 172.16.1.53(172.16.1.53:3306) completed successfully.
Mon Jul 27 19:52:58 2020 - [info] Deleted server1 entry from /service/mha/app1.cnf .
Mon Jul 27 19:52:58 2020 - [info]
----- Failover Report -----
app1: MySQL Master failover 172.16.1.52(172.16.1.52:3306) to 172.16.1.53(172.16.1.53:3306) succeeded #切换成功
Master 172.16.1.52(172.16.1.52:3306) is 'down!'
Check MHA Manager logs at db04:'/service/mha/manager' for details.
Started automated(non-interactive) failover.
The latest slave 172.16.1.53(172.16.1.53:3306) has all relay logs for recovery.
Selected 172.16.1.53(172.16.1.53:3306) as a new master.
172.16.1.53(172.16.1.53:3306): OK: Applying all logs succeeded.
172.16.1.54(172.16.1.54:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
172.16.1.54(172.16.1.54:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.16.1.53(172.16.1.53:3306)
172.16.1.53(172.16.1.53:3306): Resetting slave info succeeded.
Master failover to 172.16.1.53(172.16.1.53:3306) completed successfully.
#查看主从状态
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.1.53 #主库切换
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 120
Relay_Log_File: db04-relay-bin.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#查看MHA进程
[root@db04 ~]# ps -ef|grep mha
root 30667 26120 0 20:21 pts/1 00:00:00 grep --color=auto mha
#如果启动数据库的时候主库已经死亡,那么,主库将会直接切换,之后mha停止运行
三、恢复MHA
1.修复数据库
systemctl start mysqld.service
/etc/init.d/mysqld start
2.恢复主从
#将恢复的数据库当成新的从库加入集群
#找到binlog位置点(多个的话取后面的)
[root@db04 mha]# grep 'CHANGE MASTER TO' /service/mha/manager | tail -1 | sed 's#xxx#123#g' | awk -F: '{print $4}'
CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000016', MASTER_LOG_POS=120, MASTER_USER='rep', MASTER_PASSWORD='123';
#恢复的数据库执行change master to(基于GTID)
CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='123';
#普通的change
CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306,MASTER_USER='rep', MASTER_PASSWORD='123',master_log_file='mysql-bin.0000016',master_log_pos=120;
mysql> start slave;
Query OK, 0 rows affected (0.05 sec)
3.恢复MHA
1.
#manager所在主机,将恢复的数据库配置到MHA配置文件(用过的配置会自动删除)
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
manager_log=/service/mha/manager
manager_workdir=/service/mha/app1
master_binlog_dir=/service/mysql/data
password=mha
ping_interval=2
repl_password=123
repl_user=rep
ssh_user=root
user=mha
[server1]
hostname=172.16.1.51
port=3306
candidate_master=1
check_repl_delay=0
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[root@db04 ~]# cp /service/mha/{app1.cnf,app1.cnf.bak}
[root@db04 ~]# \cp /service/mha/{app1.cnf.bak,app1.cnf}
2.
#启动MHA
nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
#关闭MHA
masterha_stop --conf=/service/mha/app1.cnf
#检测mha进程
[root@db04 ~]# !ps
ps -ef|grep mha
root 30716 26120 2 20:48 pts/1 00:00:00 perl /usr/bin/masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
root 30748 26120 0 20:48 pts/1 00:00:00 grep --color=auto mha
#查看主库
mysql> show slave status\G
#可再次验证mha的自动主库切换
[root@db03 ~]# /etc/init.d/mysqld stop
Shutting down MySQL..... SUCCESS
一、MHA搭建(步骤总结)
1.安装依赖
2.部署node节点
3.部署manager节点
4.编写配置文件
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
manager_log=/service/mha/manager
manager_workdir=/service/mha/app1
master_binlog_dir=/usr/local/mysql/data
password=mha
ping_interval=2
repl_password=123
repl_user=rep
ssh_user=root
user=mha
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
candidate_master=1
check_repl_delay=0
[server3]
hostname=172.16.1.53
port=3306
[binlog1]
no_master=1
hostname=172.16.1.53
master_binlog_dir=/root/binlog/
#
5.创建mha管理用户
6.集群中所有机器互相做免密
7.检测MHA状态
8.启动MHA
#创建用户
useradd mha
#远程保存binlog
mysqlbinlog -R --host=172.16.1.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
9.备份mha配置文件
[root@db04 mha]# cp /service/mha/{app1.cnf,app1.cnf.bak}
二、修复MHA故障
1.手动修复
1)修复挂掉的数据库(不是主库了)
[root@db02 ~]# systemctl start mysqld
2)将修复的机器加入主从
#找到change master to语句
[root@db03 ~]# grep 'CHANGE MASTER TO' /service/mha/manager | tail -1 | awk -F: '{print $4}' | sed 's#xxx#123#g'
CHANGE MASTER TO MASTER_HOST='172.16.1.51', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='123';
#到修复的数据库执行(基于GTID)
mysql -e "CHANGE MASTER TO MASTER_HOST='172.16.1.51', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='123';"
#修复的数据库启动线程
[root@db02 ~]# mysql -uroot -p -e "start slave"
3)修复MHA
#将修复的库配置加到MHA配置文件
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
manager_log=/service/mha/manager
manager_workdir=/service/mha/app1
master_binlog_dir=/usr/local/mysql/data
password=mha
ping_interval=2
repl_password=123
repl_user=rep
ssh_user=root
user=mha
master_ip_failover_script=/service/mha/master_ip_failover
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
candidate_master=1
check_repl_delay=0
[server3]
hostname=172.16.1.53
port=3306
no_master=1
master_binlog_dir=/root/binlog/
#重启MHA
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
2.编写脚本修复MHA
manager节点上的脚本(位置待定)
[root@db04 ~]# vim check_mha.sh
#过滤出坏掉主机的ip
mha_master_host=`grep 'as a new master' /service/mha/manager | tail -1 | awk -F "[ ,(]" '{print $2}'`
#启动保存binlog
cd /root/binlog/ && nohup mysqlbinlog -R --host="$mha_master_host" --user=mha --password=mha --raw --stop-never mysql-bin.000001 >/dev/null &
node节点上的脚本
[root@db04 ~]# cat start_mha.sh
#判断数据库是否挂掉
mysql_pid=`ps -ef | grep [m]ysqld | wc -l`
#如果挂掉则重启,如果没挂则杀掉重启
if [ $mysql_pid -eq 0 ];then
systemctl start mysqld
else
pkill mysqld
systemctl start mysqld
fi
sleep 3
#获取change master to语句
change=`ssh 172.16.1.54 "grep 'CHANGE MASTER TO' /service/mha/manager | tail -1 | sed 's#xxx#123#g'" | awk -F: '{print $4}'`
#重启的数据库后,执行change master to
mysql -uroot -p123 -e "${change};start slave" &>/dev/null
#修复MHA配置文件
ssh 172.16.1.54 "\cp /service/mha/app1.cnf.bak /service/mha/app1.cnf"
#过滤出坏掉主机的ip
down_ip=`grep 'is down!' /service/mha/manager|tail -1|awk -F'[ ,(]' '{print $2}'`
#启动保存binlog
ssh 172.16.1.54 'cd /root/binlog/ && nohup mysqlbinlog -R --host="$down_ip" --user=mha --password=mha --raw --stop-never mysql-bin.000001 &>/dev/null &'
#启动MHA
ssh 172.16.1.54 'nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &'
三、MHA主库切换
1.MHA主库切换,判断谁为第二个主库
1.读取配置中的指定优先级
candidate_master=1
check_repl_delay=0
2.如果数据量不同,数据'最新'的为主库
3.如果数据量相同,按照'[主机标签]',值越小优先级越高(#SQL线程数据量小的时候,走这个)
#主从复制中,所有主机的配置必须相同,不然会浪费配置
#es中,内存是共享的
#atlas读写分离中,所有主机的配置可以不同
2.主机标签优先级测试
#配置MHA
[root@db03 ~]# vim /service/mha/app1.cnf
......
[serverc]
hostname=172.16.1.53
port=3306
[serverb]
hostname=172.16.1.52
port=3306
[serverd]
hostname=172.16.1.51
port=3306
......
#停掉主库,查看切换
mysql> show slave status\G
Master_Host: 172.16.1.52
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
3.指定优先级测试
#配置优先级
[root@db03 ~]# vim /service/mha/app1.cnf
......
[server3]
candidate_master=1
check_repl_delay=0
hostname=172.16.1.53
port=3306
......
#停掉主库,查看切换
mysql> show slave status\G
Master_Host: 172.16.1.53
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
4.数据量不同时切换的优先级
1)主库建库
mysql -uroot -p123 -e 'use test;create table linux9(id int not null primary key auto_increment,name varchar(10))';
2)脚本循环插入数据
[root@db03 ~]# vim insert.sh
#/bin/bash
while true;do
mysql -e "use test;insert linux9(name) values('lhd')"
sleep 1
done &
或者
#/bin/bash
while true;do
mysql -uroot -p123 -e 'use test;insert linux9(name) select * from linux'
sleep 1
done &
[root@db03 ~]# sh insert.sh
3)停掉一台机器的IO线程
#此时db03是主库,停掉db01的IO线程,使db01的数据量比db02少
mysql> stop slave io_thread;
4)停掉db03的主库
[root@db03 ~]# systemctl stop mysqld
5)查看主库切换
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.1.52
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 67437
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 14904
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
5.如果主库宕机,binlog如何保存
1)配置MHA实时备份binlog
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
manager_log=/service/mha/manager
manager_workdir=/service/mha/app1
master_binlog_dir=/usr/local/mysql/data
password=mha
ping_interval=2
repl_password=123
repl_user=rep
ssh_user=root
user=mha
master_ip_failover_script=/service/mha/master_ip_failover
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
#开启binlog server
[server3]
hostname=172.16.1.53
port=3306
no_master=1
master_binlog_dir=/root/binlog/
......
[binlog1]
#[]可以改为,不会成为主库的server标签
no_master=1
#永远不为主库,防止自己拿自己的
hostname=172.16.1.53
#拿过来的binlog放在哪,不能跟当前机器数据库的binlog存放目录一样(防止覆盖本机binlog)
master_binlog_dir=/root/binlog/
2)创建binlog存放目录
[root@db03 ~]# mkdir binlog
3)手动执行备份binlog
#进入该目录
[root@db03 ~]# cd /root/binlog/
#备份binlog
[root@db03 binlog]# mysqlbinlog -R --host=172.16.1.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
-R :读取远程的地址
--raw :一种格式
--stop-never :不停止
root@db04 binlog]# !ps
ps -ef|grep mha
root 39354 1 0 16:50 ? 00:00:01 perl /usr/bin/'masterha_manager' --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover
root 40755 35143 2 17:32 pts/1 00:00:00 'mysqlbinlog' -R --host=172.16.1.52 --user=mha --password=x x --raw --stop-never mysql-bin.000001
#停止主库可导致该manage所在主机后台进程(mysqlbinlog)退出
4)重启MHA
[root@db03 binlog]# masterha_stop --conf=/service/mha/app1.cnf
Stopped app1 successfully.
[root@db03 binlog]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
5)主库添加数据查看binlog
#主库
mysql> create database mha;
Query OK, 1 row affected (0.01 sec)
[root@db02 ~]# ll /usr/local/mysql/data/mysql-bin.000008
-rw-rw---- 1 mysql mysql 67576 Jul 28 10:33 /usr/local/mysql/data/mysql-bin.000008
#MHA机器查看binlog
[root@db03 binlog]# ll
total 96
-rw-rw---- 1 root root 852 Jul 28 10:30 mysql-bin.000001
-rw-rw---- 1 root root 214 Jul 28 10:30 mysql-bin.000002
-rw-rw---- 1 root root 214 Jul 28 10:30 mysql-bin.000003
-rw-rw---- 1 root root 214 Jul 28 10:30 mysql-bin.000004
-rw-rw---- 1 root root 465 Jul 28 10:30 mysql-bin.000005
-rw-rw---- 1 root root 214 Jul 28 10:30 mysql-bin.000006
-rw-rw---- 1 root root 214 Jul 28 10:30 mysql-bin.000007
-rw-rw---- 1 root root 67576 Jul 28 10:33 mysql-bin.000008
四、VIP漂移
1.VIP漂移的两种方式
1.keeplaived的方式
2.MHA自带的脚本进行VIP漂移('原理'与Keepalived一样)
#keeplaived
缺点:
只能'两台'主机之间实现VIP飘移,
keeplaived不能确定要切换的是哪台主机是'数据最多'的,可能会导致主从切换数据一致性问题
#阿里云不能使用VIP,因为用户不能添加网卡,但是可以使用弹性网卡
2.配置MHA读取VIP漂移脚本
#编辑配置文件
[root@db03 ~]# vim /service/mha/app1.cnf
#在[server default]标签下添加,MHA自带脚本
[server default]
master_ip_failover_script=/service/mha/master_ip_failover
3.编写脚本
#MHA默认脚本存放在
[root@db01 ~]# ll mha4mysql-manager-0.56/samples/scripts/
total 32
-rwxr-xr-x 1 4984 users 3648 Apr 1 2014 master_ip_failover
#1.上传现成的VIP脚本
rz
#2.编辑脚本
[root@db03 mha]# vim master_ip_failover
.......
my $vip = '172.16.1.50/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth1:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down";
#my $ssh_user=xx
#my $ssh_port=xx
......
#一个网卡只能绑定一个ip
关闭外网网卡,不能使用ssh
[root@db02 ~]# ifconfig eth0 down
关闭内网网卡,该网卡下的虚拟网卡不收影响
[root@db02 ~]# ifconfig eth1 down
添加一块虚拟网卡
[root@db02 ~]# ifconfig eth1:1 172.16.1.49/24
修改虚拟网络
[root@db02 ~]# ifconfig eth1:1 172.16.1.48/24
删除虚拟网卡
[root@db02 ~]# ifconfig eth1:1 down
4.手动绑定主库VIP
[root@db01 ~]# ifconfig eth1:1 172.16.1.55/24
[root@db01 ~]# ip a
inet 172.16.1.51/24 brd 172.16.1.255 scope global noprefixroute eth1
valid_lft forever preferred_lft forever
inet 172.16.1.55/24 brd 172.16.1.255 scope global secondary eth1:1
#解绑VIP
[root@db01 ~]# ifconfig eth1:1 [172.16.1.55] down
#在主库加个VIP,VIP才能飘移
5.重启MHA
#启动MHA
[root@db03 mha]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
#启动失败:
1.检查配置文件语法是否正确
2.授权是否正确
[root@db03 mha]# chmod 755 master_ip_failover
3.脚本格式要正确
[root@db03 mha]# dos2unix master_ip_failover
dos2unix: converting file master_ip_failover to Unix format ...
6.测试VIP漂移
#停止主库
[root@db01 ~]# systemctl stop mysqld.service
#查看切换成主库的ip地址
[root@db02 ~]# ip a
inet '10.0.0.53/24' brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::711:b645:9476:9d39/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::b3e2:5f27:90eb:1101/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:91:48:c1 brd ff:ff:ff:ff:ff:ff
inet '172.16.1.53/24' brd 172.16.1.255 scope global noprefixroute eth1
valid_lft forever preferred_lft forever
inet '172.16.1.55/24' brd 172.16.1.255 scope global secondary eth1:1
报错
#问题:
1.去掉VIP飘逸的脚本后,MHA切换时仍然报错说要读取脚本
#报错:
master_ip_failover_script or purge_relay_log 在同一台机器运行
#解决:
重新写一个MHA配置文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号