吴恩达第一课第二周随笔
目录
2.1二分分类
解释:预测是与否y只有0和1
logistics回归是一个用于二分分类的算法
约定一个X矩阵的构成:
n*m :n维m列,即每一个样本有n个特征,共m个样本
2.2 logistic回归
延伸:实际上,并不是非黑即白的世界,你无法利用 做到y只输出0或者1
做到y只输出0或者1
所以需要利用sigmod函数来解决
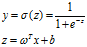
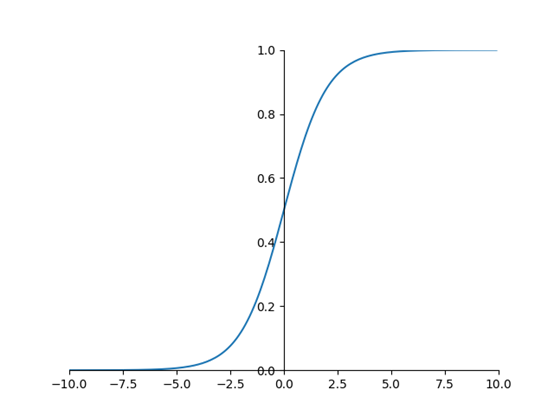
sigmod图像
任务时求出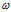 和b,通常会把
和b,通常会把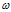 和b拆开来学习
和b拆开来学习
再是考虑成本函数
2.3 logistic成本函数
为了训练模型的参数 和b,需要定义一个成本函数
和b,需要定义一个成本函数
如果直接用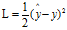 作为损失函数,将会造成这个函数变成非凸函数,不利于梯度下降优化
作为损失函数,将会造成这个函数变成非凸函数,不利于梯度下降优化
所以对于sigmod函数,找了一个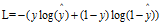

L要最小,但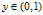 ,且前面加了一个负号,那么L的取值区间就变成了
,且前面加了一个负号,那么L的取值区间就变成了 ;
;
将每个样本的损失做全局平均和就变成了成本函数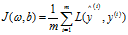
2.4 梯度下降法
while 未达到全局最优点:
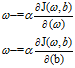
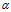 为学习率(考虑如何选择)
为学习率(考虑如何选择)
 在
在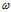 方向,成本函数J下降最快的方向,也是判断是否达到最优点的依据
方向,成本函数J下降最快的方向,也是判断是否达到最优点的依据
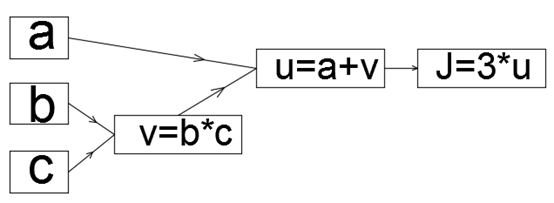
2.5 流程图
J(a,b,c)=3(a+bc) ps正向传播
2.6 计算图的导数计算
微积分的链式法则
2.7 logistic回归中单个样本的梯度下降
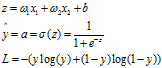
Sigmod函数 
注意其导数,可以说与z无关
过程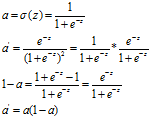
2.8 m个样本成本函数梯度下降法
算法:
初始化 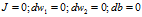
for i to m
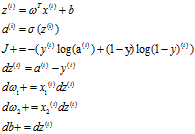
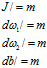
上面求出的是在J在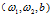 处的偏导
处的偏导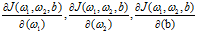
然后应用一步梯度下降更新一下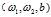 ,靠近最优点
,靠近最优点
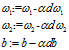
重复上面的过程,更新一次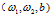 ,需要遍历一次样本,求梯度
,需要遍历一次样本,求梯度
2.9 向量化
向量化通常是消除代码中的for循环语句的艺术,尤其是在需要遍历数据时
for循环太占用时间了
数据越大,矩阵运行速度越快,for循环差距越明显
gpu,cpu都有并行化指定,有时候也称作SIMD指定(单指定多数据流)
numpy的矩阵运算,能充分的利用并行化
GPU更擅长做SIMD计算
2.10 更多的向量化指定
np.dot: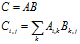 ,并不是对应位相乘
,并不是对应位相乘
算法优化:
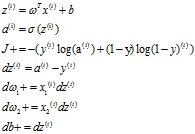
把dw1,dw2这一小循环先优化了
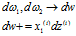
然后再是把上面的大循环给优化
有 
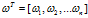
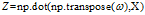 +b 有numpy的广播功能存在
+b 有numpy的广播功能存在
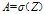
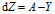
所以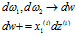 ,这个可以再一次优化
,这个可以再一次优化

dot,点积已经相加了
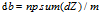
算法汇总:
fori in range (1000):
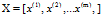
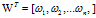
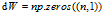
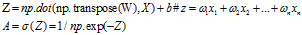
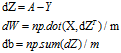
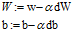
一搞一搞,把成本函数给去了,发现成本函数虽然需要自己构造,但构造出来,是让你求梯度的,并不需要放入算法里进行计算
矩阵化计算,大大缩短了运算时间,比起for循环
注意点:一个是dot已经累加了,做dw+=xdz时,矩阵运算不需要加了
另一个是b是实数,他会自动加到每一个元素上去,这是numpy的广播性质
2.11 广播
(m,n) +-*/ (m,1):会让(m,1)横向复制n次
(m,n) +-*/ (1,n):会让(m,1)竖向向复制m次
2.12 不要使用秩为1的数组
a=np.random.randn(5)
创建的并不是行向量和列向量,创建的是一个秩为1的数组
a=np.random.randn(5,1)
使用上面这种方式才是创建了一个列向量
矩阵转置并不需要用到np.transpose这个函数,直接用A.T就行了
常用reshape,确保形状,唯独
常用.shape查看数组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号