李宏毅2021春机器学习课程笔记——Tips for training:数据预处理
本文作为自己学习李宏毅老师2021春机器学习课程所做笔记,记录自己身为入门阶段小白的学习理解,如果错漏、建议,还请各位博友不吝指教,感谢!!
数据预处理
一般而言,样本特征由于来源以及度量单位不同,他们的尺度(Scale)(即取值范围)往往差异很大。如果一个机器学习算法在缩放全部或部分特征后不影响它的学习和预测,我们就成该算法具有尺度不变性(Scale Invariance)。比如线性分类器是尺度不变的,而最近邻分类器就是尺度敏感的。所以,对于尺度敏感的模型,必须先对样本进行预处理,将各个维度的特征转换到相同的取值区间,并且消除不同特征之间的相关性,才能获得比较理想的结果,以避免尺度大的特征会起到主导作用。
从理论上,神经网络应该具有尺度不变性,可以通过参数的调整来适应不同特征的尺度。但尺度不同的输入特征会增加训练难度。
比如:假设一个只有一层的网络\(y=tanh(w_1x_1+w_2x_2+b)\),其中\(x_1 \in [0,10], x_2 \in [0,1]\)。\(tanh\)函数的导数是在区间[-2, 2]上敏感的,其余范围的倒数接近于0。因此,如果\(w_1x_1+w_2x_2+b\)过大或者过小,都会导致梯度过小,使训练很难进行下去。我们可以将\(w_1\)设得小一些(比如[-0.1, 0.1]之间),让\(w_1x_1+w_2x_2+b\)落在[-2,2]之间,来提高训练效率。
当网络参数少的时候,这样手动的选择参数还行的通,但是参数太多,就没法一个个的设计每一个参数了。除了参数初始化比较困难外,不同输入特征的尺度差异比较大时,梯度下降法的效率也会受到影响。
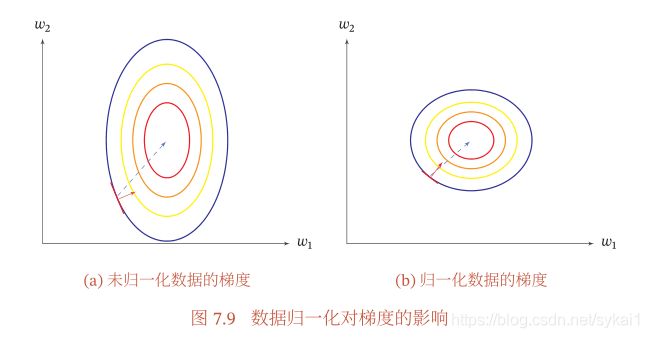
如上图(a)所示,尺度不同会造成在大多数位置上的梯度方向并不是最优的搜索方向,这样在使用梯度下降法寻求最优解时,会导致需要很多次的迭代才能收敛。而(b)中经过归一化之后,大多数位置的梯度方向都近似于最优解的方向,这样在使用梯度下降算法时,会大大提高训练效率。
归一化
归一化(Normalization)方法泛指把数据特征转换为相同尺度的方法,比如把数据特征映射到 [0, 1] 或 [−1, 1] 区间内,或者映射为服从均值为 0、方差为1的标准正态分布。
最小最大值归一化
最小最大值归一化(Min-Max Normalization)是一种非常简单的归一化方法,通过缩放将每一个特征的取值范围归一到[0,1]或[-1,1]之间。假设有N个样本\(\{x^{(n)}\}^N_{n=1}\),对于每一维特征\(x\),归一化后的特征为:
其中\(min(x)\)和\(max(x)\)分别是所有样本中的最小值和最大值。
标准化
标准化(Standardization)也叫Z值归一化(Z-Score Normalization),来源于统计上的标准分数。将每一个维特征都调整为均值为0,方差为1。假设有N个样本\(\{x^{(n)}\}^N_{n=1}\),对于每一维特征\(x\),我们先计算它的均值和方差:
然后,将每一个特征\(x^{(n)}\)减去均值,并除以标准差,得到新的特征值\(\hat{x^{(n)}}\):
其中,标准差\(\sigma\)不能为0。如果标准差为0,说明这一维特征没有任何区分性,可以直接删掉。
白化
白化(Whitening)是一种重要的预处理方法,用来降低输入数据特征之间的冗余性.输入数据经过白化处理后,特征之间相关性较低,并且所有特征具有相同的方差.白化的一个主要实现方式是使用主成分分析(Principal Component Analysis,PCA)方法去除掉各个成分之间的相关性.

参考材料:
《神经网络与深度学习》 邱锡鹏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号