李宏毅2021春机器学习课程笔记——Tips for training:Adaptive Learning Rate
本文作为自己学习李宏毅老师2021春机器学习课程所做笔记,记录自己身为入门阶段小白的学习理解,如果错漏、建议,还请各位博友不吝指教,感谢!!
问题描述

当我们在训练一个网络时,如果观察到我们训练的loss如上图所示,越来越小,最后卡住不在下降了。我们会认为走到critical point了,因为critical point处loss的gradient等于0,所以loss值不会再发生变化。其实不然,如果loss的gradient在error surface中来回的震荡,也是会出现同样的情况。
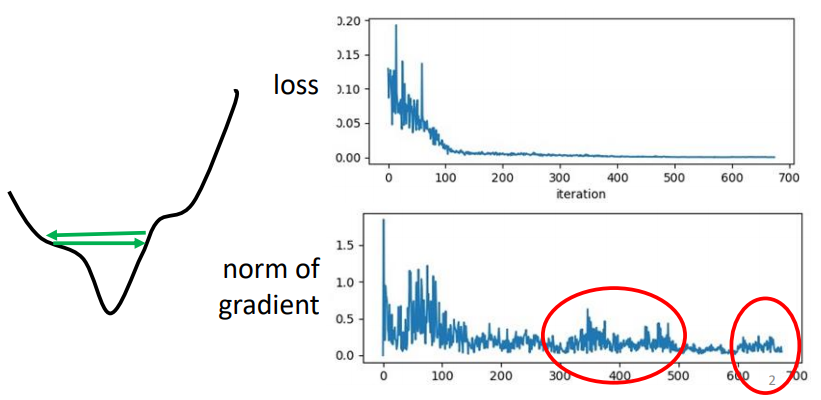
如上图所示,红圈中的gradient的norm,即gradient这个向量的长度并没有变得很小,但是同样导致了loss不会再下降得情况。
所以说,即便没有陷入critical point,我们在训练网络模型时,也是很困难的。上边说到的情况在训练网络模型时是如下这样子的:
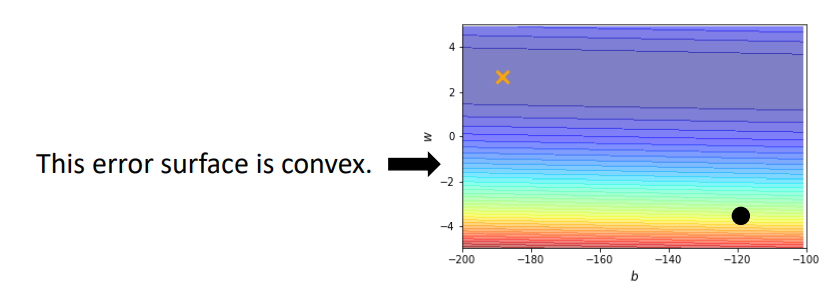
这个error surface是convex的形状,它的最低点在黄色的X处。这个error surface的等高线是椭圆形的,只是它在横轴的地方,它的gradient非常的小,它的坡度的变化非常的小,非常的平滑,所以这个椭圆的长轴非常的长,纵轴相对之下比较短,在纵轴的地方gradient的变化很大,error surface的坡度非常的陡峭。
我们用\(\eta=10^{-2}\)的学习率进行训练,化出error surface,如下图所示:

可见我们的loss在error surface的山壁两端不断地震荡,网络的loss降不下去,而且loss的gradient是很大的。
我们换用小点的学习率\(\eta=10^{-7}\)进行训练,尝试减小每次更新的步伐的大小,使得loss慢慢滑倒error surface的山谷中。效果如下图所示:

可以看到,在向上的这个地方,因为坡度很陡,gradient的值很大,loss可以逐渐的变小。但是当向左的时候,这里已经是很平滑了,如此小的learning rate是无法将loss降到最小值的。(上图中10w次的update也仅仅是让loss向左滑动一小段而已)
所以,我们需要更好的gradient descent方法,来进行我们的训练。之前我们gradient descent中,所有的参数都是共用同一个learning rate,这显然是不够的。应该为每一个参数设置特定的learning rate,以在每个参数维度上获得更好的收敛速度。
首先,我们看一下原来的gradient descent,所有的参数共用一个learning rate:
上边的公式表示,用第t轮中计算得到的梯度g,来更新第i个参数\(\theta\)。我们将学习率\(\eta\)改写成\(\frac{\eta}{\sigma_i^t}\),来为每个参数设置不同的learning rate。对于即和更新的iteration有关又和第i个参数\(\theta_i\)的梯度有关的\(\sigma_i^t\)有如下几种计算方式。
AdaGrad算法
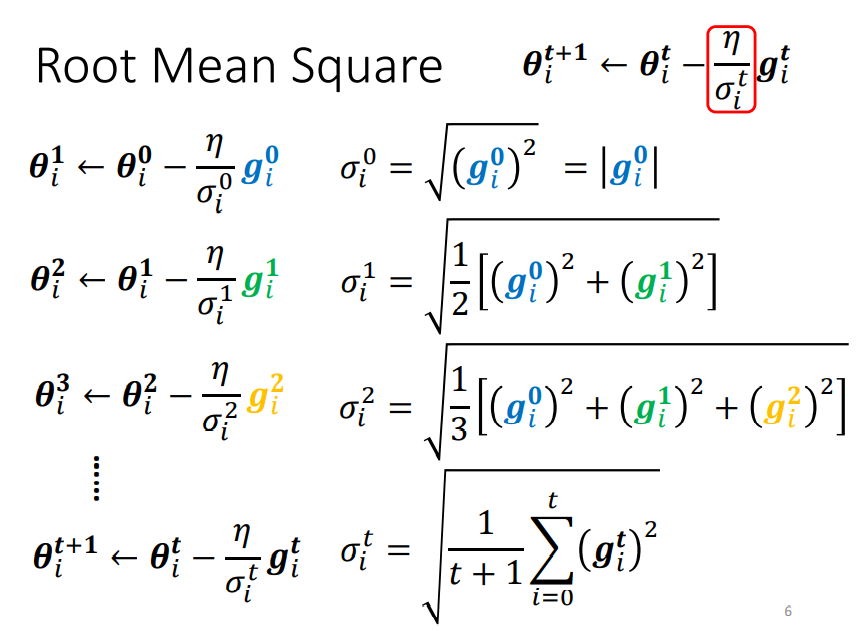
如上图所示在Adagrad算法中,梯度更新公式如下:
- 当损失函数的梯度很小时

当第i个参数的的梯度比较小时,积累的\(\sigma_i^t\)也会比较小,最终得到的学习率\(\frac{\eta}{\sigma_i^t}\)就会比较大。即,在坡度比较小的时候,学习率比较大。
- 当损失函数的梯度很大时
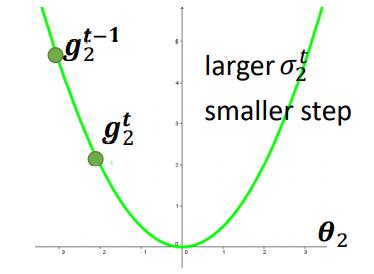
当第i个参数的的梯度比较大时,积累的\(\sigma_i^t\)也会比较大,最终得到的学习率\(\frac{\eta}{\sigma_i^t}\)就会比较小。即,在坡度比较大的时候,学习率比较小。
因此,在AdaGrad算法中,如果某个参数的偏导数累积比较大,其学习率相对较小;相反,如果其偏导数累积较小,其学习率相对较大,但整体是随着迭代次数的增加,学习率逐渐缩小。
AdaGrad算法缺点:在经过一定次数的迭代依然没有找到最优点时,由于这时的学习率已经非常小,很难再继续找到最优点。
RMSprop算法

RMSProp算法是Geoff Hinton提出的一种自适应学习率的方法。可以在有些情况下避免AdaGrad算法中学习率不断单调下降以至于过早衰减的缺点。
如上图所示,RMSProp算法中首先计算了梯度平方的指数衰减移动平均并取平方根,然后更新了参数:
其中\(\alpha\)为衰减率,一般取值为0.9。RMSProp算法和AdaGrad算法的区别在于\(\sigma_i^t\)的计算有累积方式变成了指数衰减移动平均。在迭代过程中,每个参数的学习率并不是成衰减趋势,既可以变大也可以变小。具体怎么做到的可以参考下图:
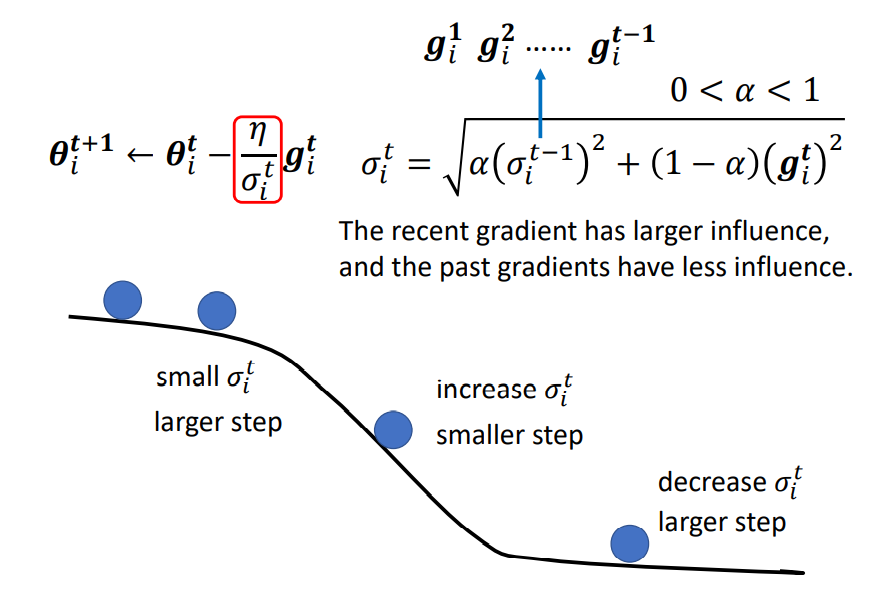
- 在梯度较大的时候,我们可以减小\(\alpha\)的值,增大现在梯度的影响,使\(\sigma_i^t\)变大,从而使整个学习率\(\frac{\eta}{\sigma_i^t}\)减小。
- 在梯度较小的时候,我们可以增大\(\alpha\)的值,减小现在梯度的影响,使\(\sigma_i^t\)变小,从而使整个学习率\(\frac{\eta}{\sigma_i^t}\)减大。
Adam算法
Adam算法可以看作动量法和RMSprop算法的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。
Adam算法参数更新公式如下:
- 首先计算梯度平方的指数加权平均并取平方根(和RMSprop算法类似)。
其中\(\alpha_2\)使衰减率,通常为0.99。我们可以把\((\sigma^t)^2\)看作梯度未减去均值的方差。
- 计算梯度的指数加权平均(和动量法类似)
其中\(\alpha_1\)为衰减率,通常取值为0.9。我们可以把\(M^t\)看作梯度的均值。
- 假设\(M^0_i=0, \sigma^0_i=0\),那么在迭代初期\(M^t,\alpha^t\)的值会比真实的均值和方差要小。特别当\(\alpha_1, \alpha_2\)都接近于1时,偏差会很大。因此,需要对偏差进行修正。
- 更新参数的值
其中\(\eta\)是学习率,通常设为0.001,并且也可以进行衰减 ,比如\(\eta^t = \frac{\eta^0}{\sqrt{t}}\)。
Learning Rate Scheduling
现在我们使用AdaGrad训练问题描述中的网络模型,画出error surface如下图所示:
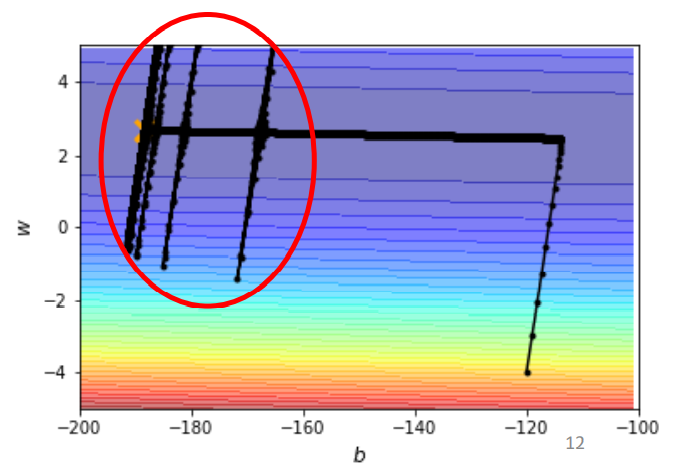
- 在损失函数向左滑动的这一段,因为gradient很小,所以learning rate会自动调整变大,让损失函数滑动步伐变大,可以不断的向左滑动。
- 但是在快接近最优值的附近,损失函数突然发生来爆炸的情况。出现这种情况的原因就是,在损失函数向左滑动的过程中,在纵轴上的gradient是很小的,一段时间后会积累出很小的\(\sigma\),导致在纵轴上的learning rate突然变大,爆炸出去。
- 爆炸出去,损失函数来到的地方的gradient是很大的,所以\(\sigma\)又会变大,导致在纵轴上的learning rate变小,得以让损失函数有逐渐滑向谷底。
所以,在上边error surface中,损失函数走着走着会突然的往左右喷一下,但是这个喷一下并不会永远的震荡,不会做简谐运动停不下来,这个力道慢慢变小,有摩擦力,让它慢慢地慢慢地,滑回中间地峡谷。然后积累一段时间后,又会喷出去,再慢慢滑回来。对于这种情况可以使用learning rate scheduling来解决。
Learning Rate Decay
从经验上看,学习率在一开始要保持大些来保证收敛速度,在收敛到最优点附近时要小些以避免来回振荡.比较简单的学习率调整可以通过学习率衰减(Learning Rate Decay)的方式来实现,也称为学习率退火(Learning Rate Annealing).
学习率衰减可以让\(\eta\)随着时间不断地减小。在上面地问题中,当损失函数快要接近最优值发生左右乱喷地时候,让它乘上已经变得很小地\(\eta\)停下来,这样就可以慢慢走向最优值,如下图所示:
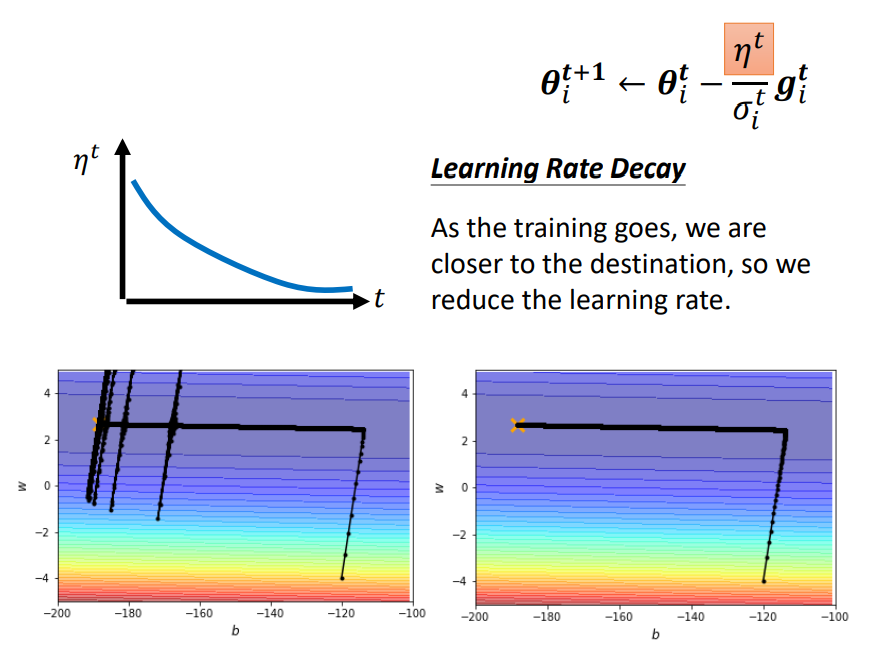
学习率是按每次迭代(Iteration)进行,也可以按每m次迭代或每个回合(Epoch)进行。衰减率通常和总迭代次数相关。
设置衰减方式为按迭代次数进行衰减,假设初始化学习率为\(\eta_0\),在第t次迭代时地学习率为\(\eta_t\),常见地衰减方法有以下几种:
分段常数衰减(Piecewise Constant Decay)
即每经过\(T_1,T_2,\cdots, T_m\)次迭代将学习率衰减为原来地\(\beta_1, \beta_2, \cdots, \beta_m\)倍,其中\(T_m\)和\(\beta_m < 1\)为根据经验设置地超参数。分段常数衰减也称为阶梯衰减(Step Decay)。
逆时衰减(Inverse Time Decay)
其中\(\beta\)为衰减率。
指数衰减(Exponential Decay)
其中\(\beta < 1\)为衰减率。
自然指数衰减(Natural Exponential Decay)
其中\(\beta\)为衰减率。
余弦衰减(Cosine Decay)
其中\(T\)为总的迭代次数。
下图给出了不同衰减方法地示例(假设初始学习率为1)

Learning Rate Warmup
在小批量梯度下降法中,当批量大小(Batch Size)地设置比较大时,通常需要比较大的学习率。但在刚开始训练时,由于参数是随机初始化的,梯度往往也比较大,再加上比较大的初始学习率,会使得训练不稳定。
为了提高训练稳定性,可以在最初几轮迭代时,采用比较小的学习率,等梯度下降到一定程度后再恢复到初始的学习率,这种方法称为学习率预热(Learning Rate Warmup)。
一个常用的学习率预热方法是逐渐预热(Gradual Warmup)。假设预热的迭代次数为\(T'\),初始学习率为\(\alpha_0\),在预热过程中每次更新的学习率为:
当预热过程结束,再选择一种学习率衰减方法来逐渐降低学习率。
《神经网络与深度学习》 邱锡鹏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号