
ES进阶
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat.html
1.监控接口
访问es的_cat接口,获取不同的属性
http://10.0.0.51:9200/_cat/health
http://10.0.0.51:9200/_cat/nodes
http://10.0.0.51:9200/_cat/master
http://10.0.0.51:9200/_cat/indices
http://10.0.0.51:9200/_cat/shards
http://10.0.0.51:9200/_cat/shards/t2
#http接口查看集群状态
# 判断是否健康
[root@es-node1 ~]#curl -s 127.0.0.1:9200/_cat/health|grep 'green' | wc -l
1
[root@es-node1 ~]#
# 统计es节点数量
[root@es-node1 ~]#curl -s 127.0.0.1:9200/_cat/nodes | wc -l
3
[root@es-node1 ~]#kibana控制台

kibana开启监控
添加监控
打开监控
查看es集群信息
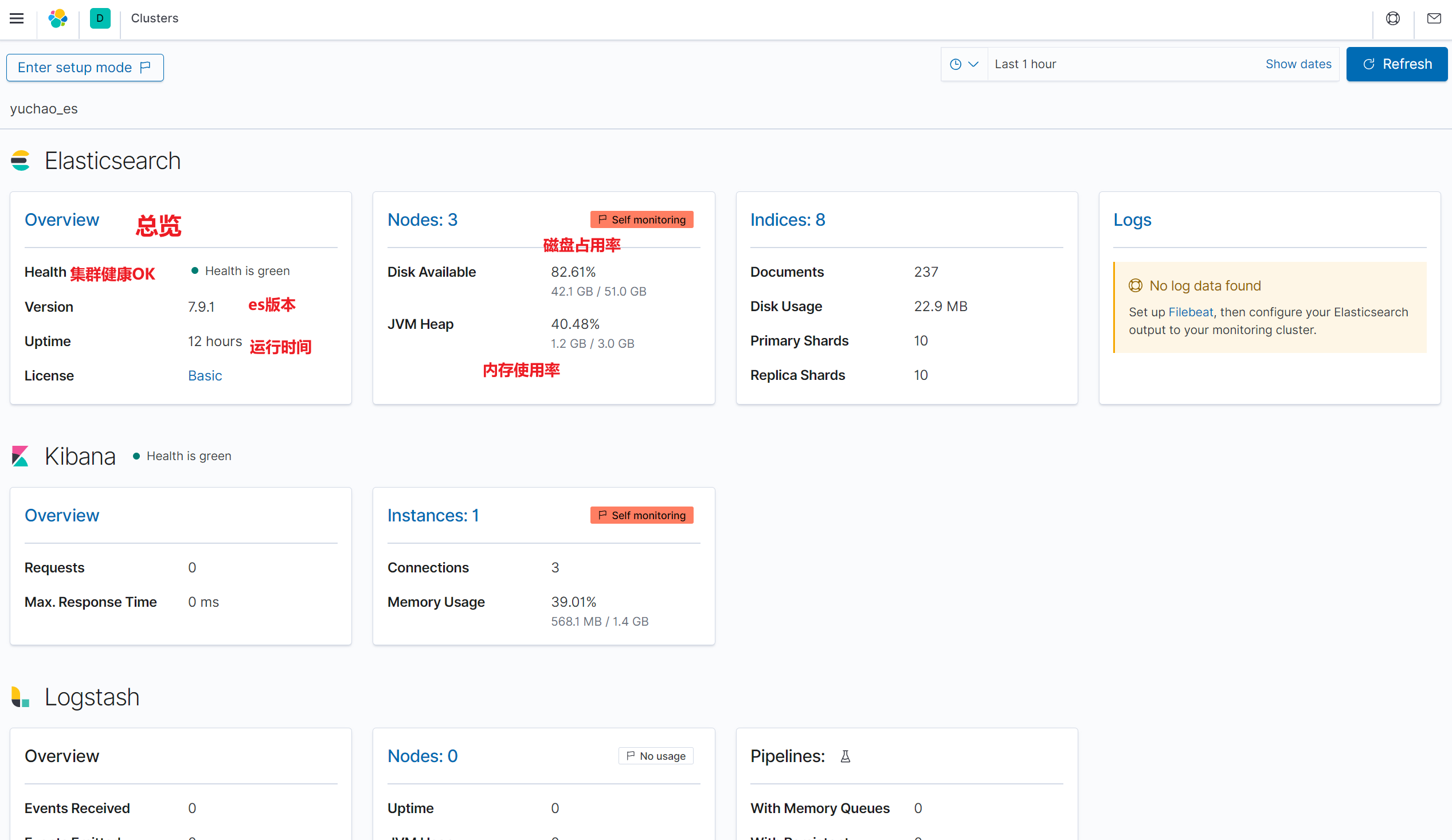
节点使用率状态
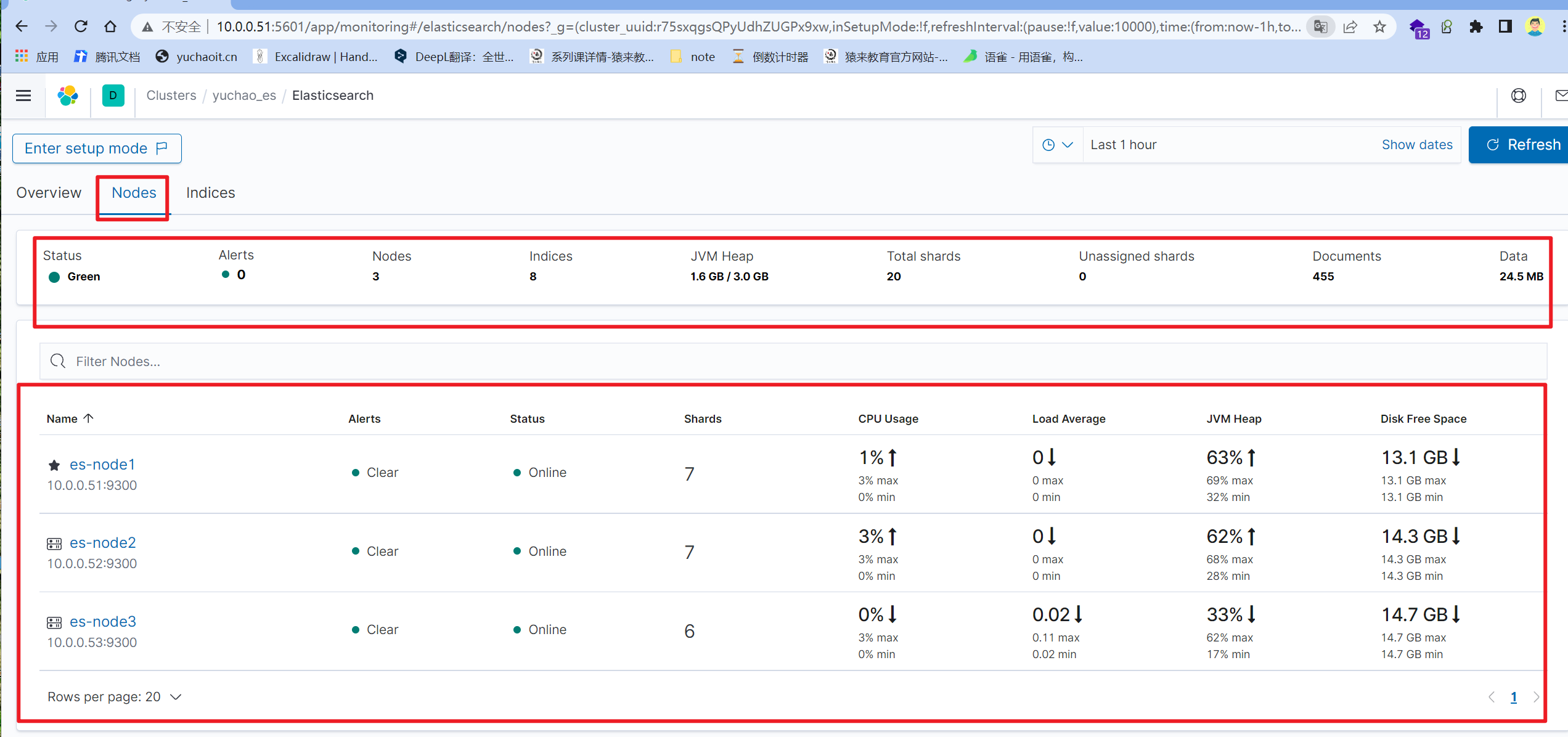
kibana生成的监控数据
kibana获取监控数据,写入es,然后kibana再读。
10s采集区间。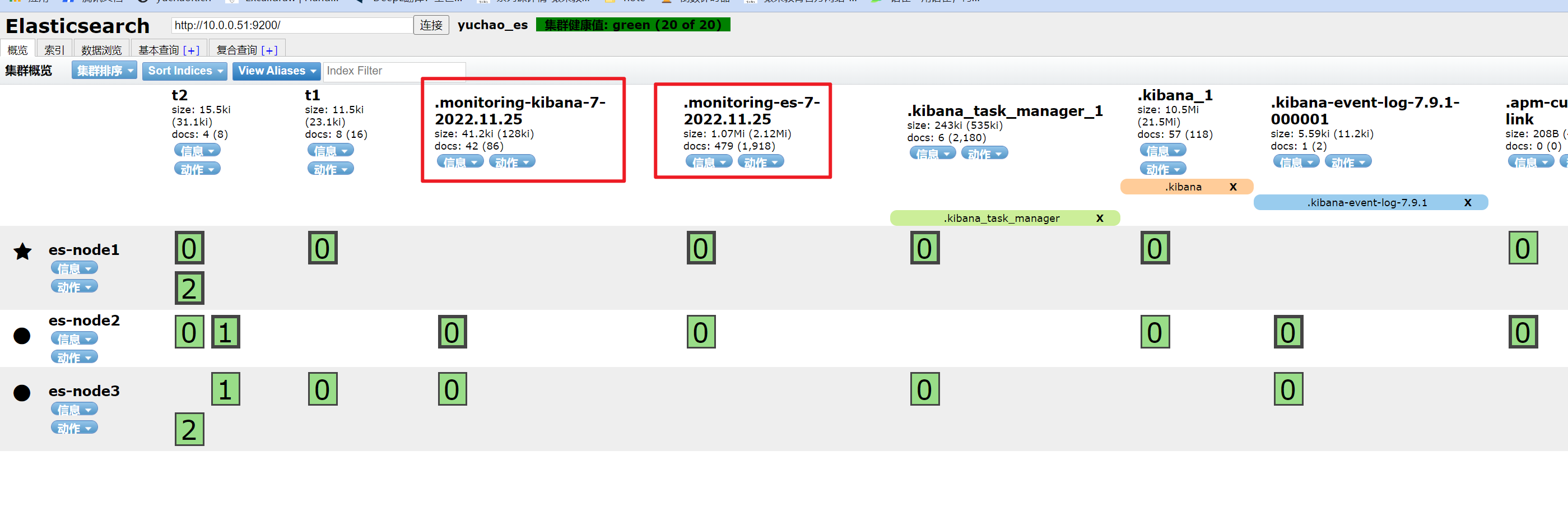
关闭kibana监控
# 查看集群状态,是否监控
GET /_cluster/settings
PUT /_cluster/settings
{
"persistent" : {
"xpack" : {
"monitoring" : {
"collection" : {
"enabled" : "false"
}
}
}
},
"transient" : { }
}
# 可以删除监控数据index2.ES中文分词器
创建测试数据
PUT /news2/_doc/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
PUT /news2/_doc/2
{"content":"公安部:各地校车将享最高路权"}
PUT /news2/_doc/3
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
PUT /news2/_doc/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}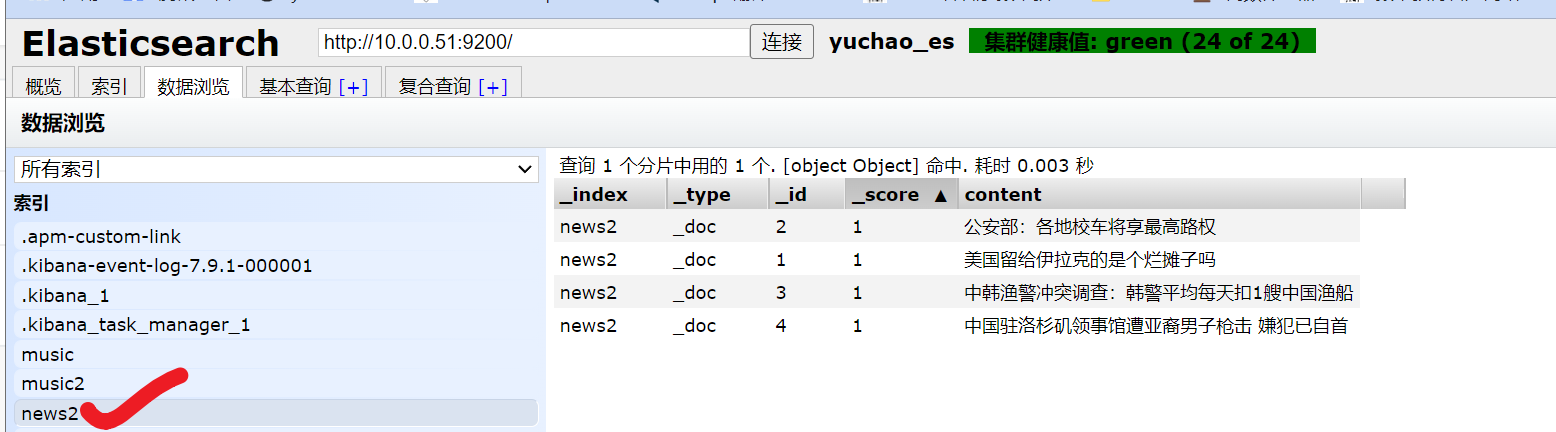
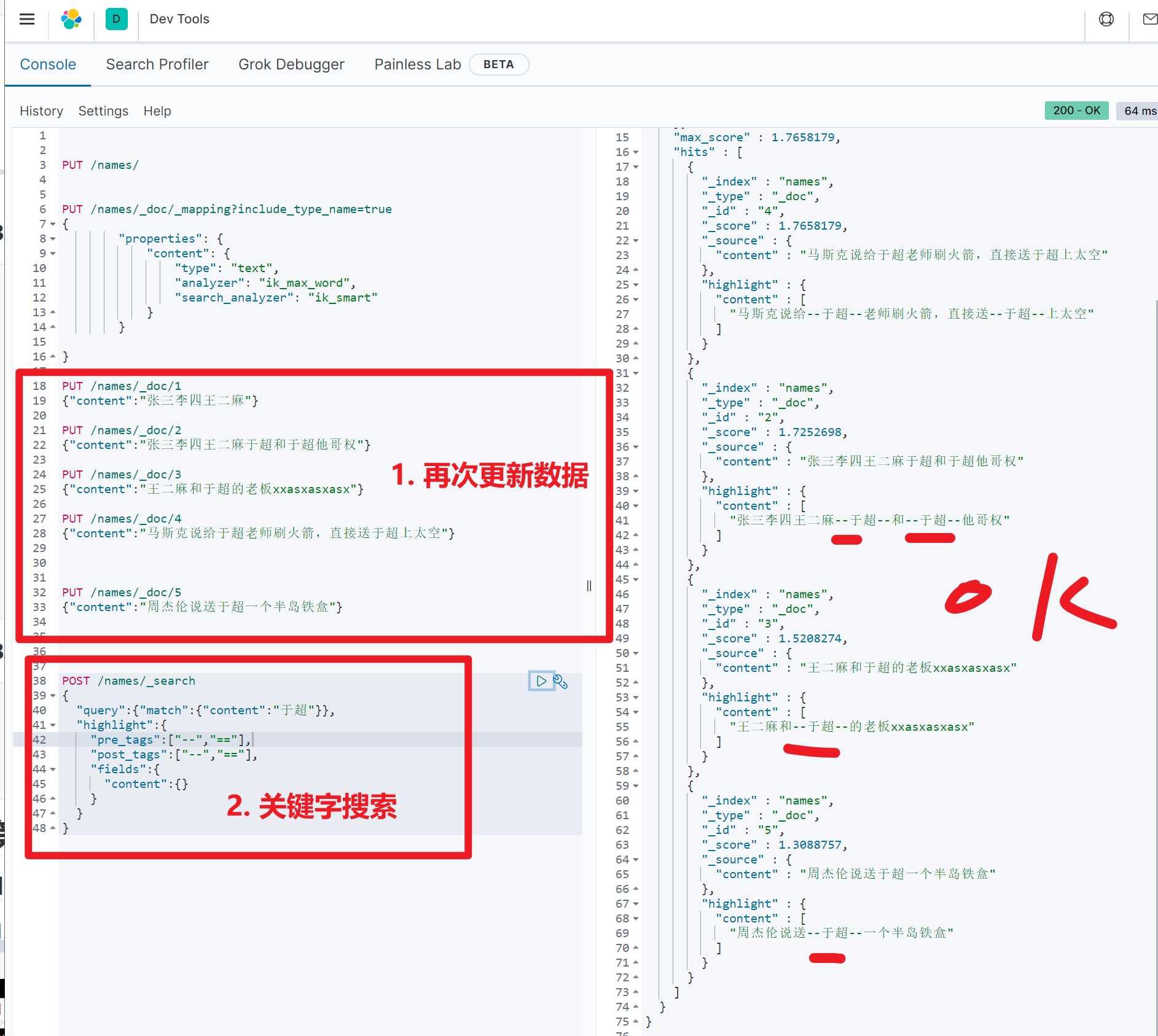
关键字查询
POST /news/_search
{
"query":{"match":{"content":"中国"}},
"highlight":{
"pre_tags":["--","=="],
"post_tags":["--","=="],
"fields":{
"content":{}
}
}
}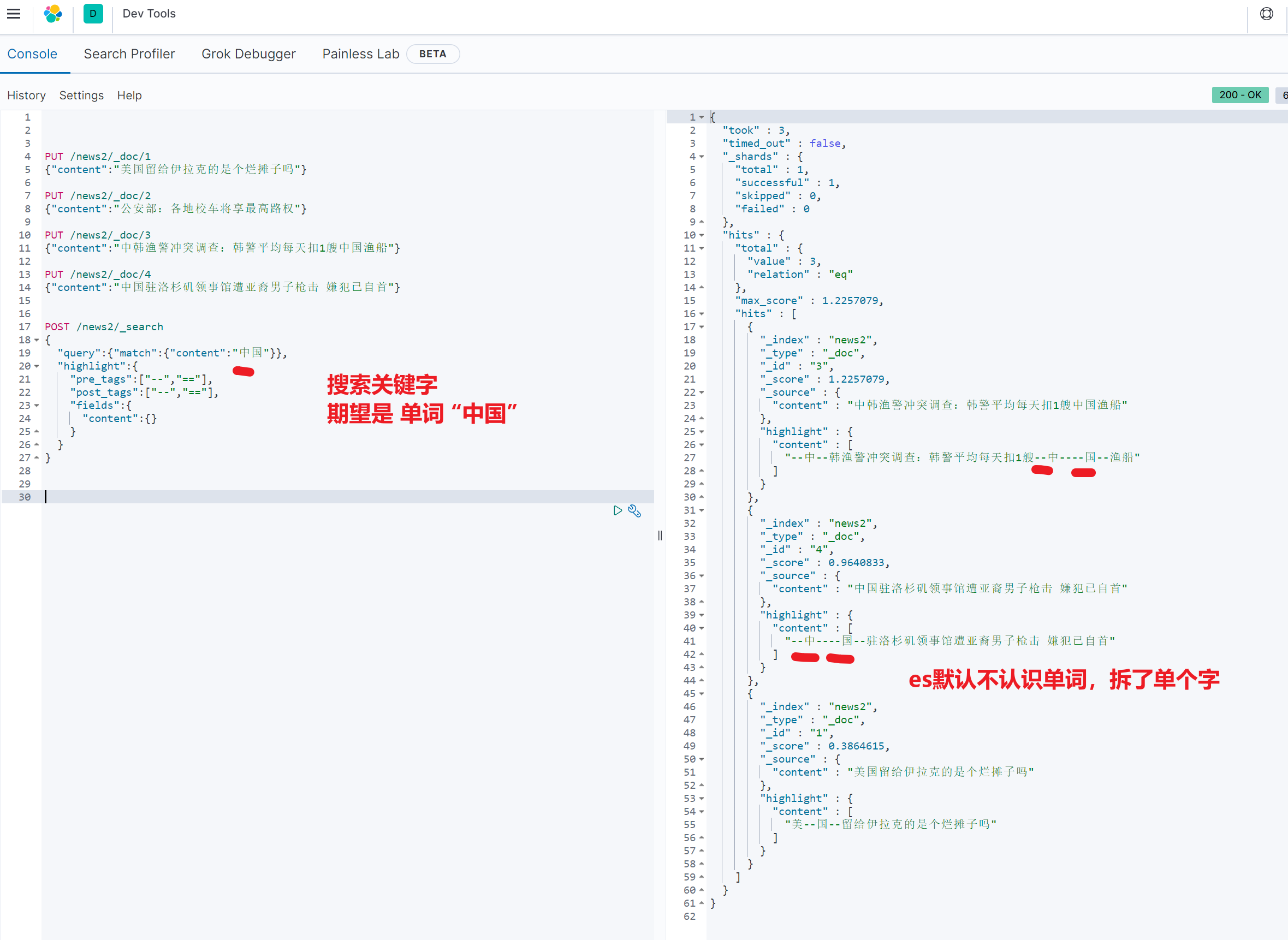
坑
你搜索的命名是词语,但是es认为是单个的字母。
修改es中文查询
1.这是第三方插件,需要给es所有节点部署,且重启
2.中文分词器版本,与es版本对应
3.下载地址
https://github.com/medcl/elasticsearch-analysis-ik安装中文分词器插件
# 在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.1/elasticsearch-analysis-ik-7.9.1.zip
# 离线安装,3个机器
[root@es-node3 ~]#/usr/share/elasticsearch/bin/elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.9.1.zip
-> Installing file:///root/elasticsearch-analysis-ik-7.9.1.zip
-> Downloading file:///root/elasticsearch-analysis-ik-7.9.1.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
-> Installed analysis-ik
# 重启3个节点的es
systemctl restart elasticsearch.service测试中文分词器
1. 要创建支持中文的索引模板
PUT /news_cn/
2. 创建索引使用哪一款分词器
PUT /news_cn/_doc/_mapping?include_type_name=true
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
# 根据教程走即可
https://github.com/medcl/elasticsearch-analysis-ik
# 插入新数据解释
ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”
拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。完整中文分词效果
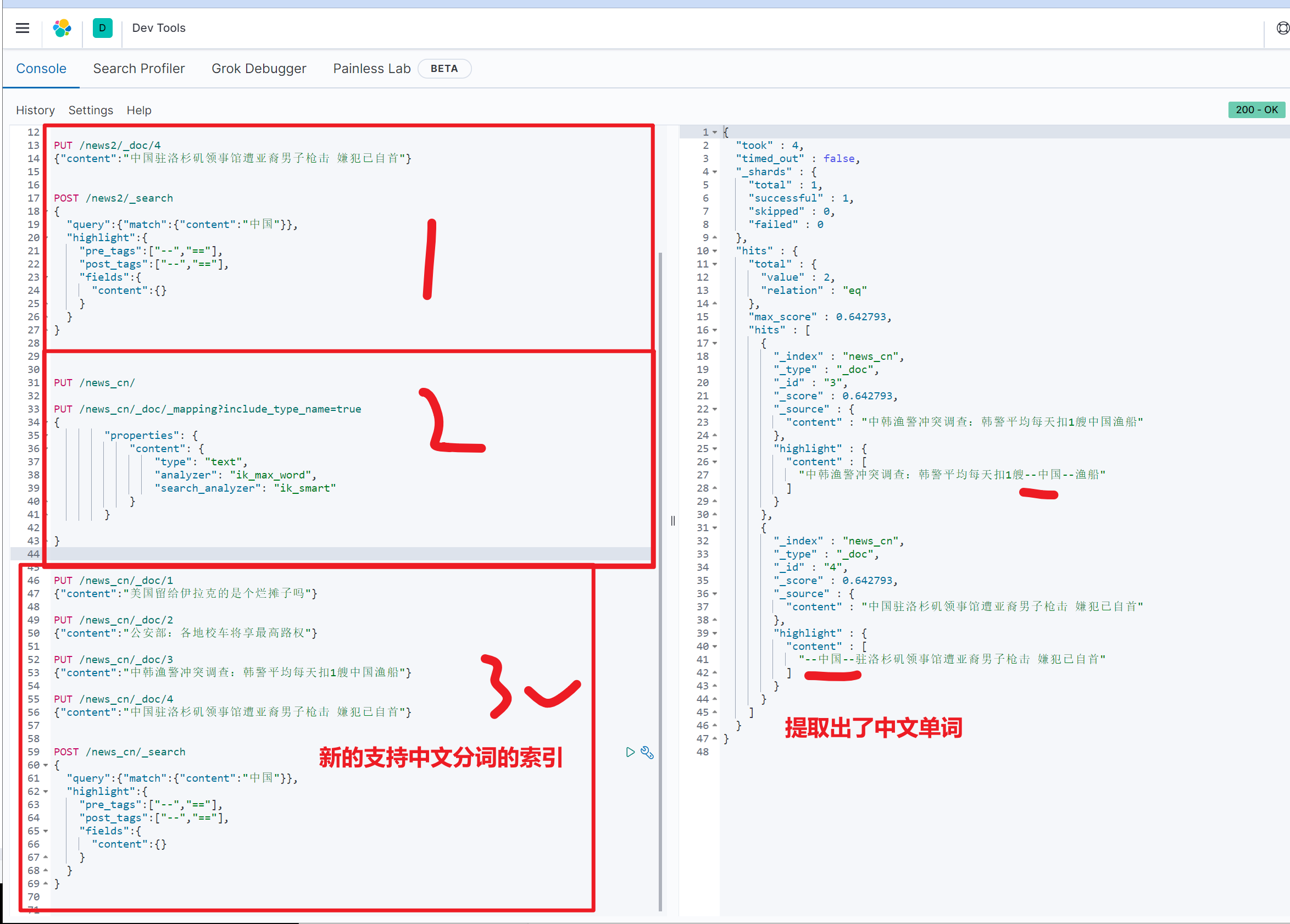
POST /news/_search
{
"query":{"match":{"content":"中国"}},
"highlight":{
"pre_tags":["--","=="],
"post_tags":["--","=="],
"fields":{
"content":{}
}
}
}
创建自带中文词库
[root@es-node3 /etc/elasticsearch/analysis-ik]#wc -l main.dic
275908 main.dic更新中文词库
1. 安装nginx
[root@es-node1 ~]#yum install nginx -y
2.写好词典文件
cat >> /usr/share/nginx/html/my_word.txt <<'EOF'
北京
上海
江苏
淮安
山东
于超
周杰伦
EOF
3.启动访问nginx的词典
[root@es-node1 ~]#nginx
[root@es-node1 ~]#
[root@es-node1 ~]#curl 10.0.0.51/my_word.txt
北京
上海
江苏
淮安
山东
于超
周杰伦
[root@es-node1 ~]#
4.修改es中文分词器插件
[root@es-node1 ~]#
cat >/etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml <<'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://10.0.0.51/my_word.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
EOF
5.同步3个机器的配置文件
cd /etc/elasticsearch/analysis-ik/
scp IKAnalyzer.cfg.xml root@10.0.0.52:/etc/elasticsearch/analysis-ik/
scp IKAnalyzer.cfg.xml root@10.0.0.53:/etc/elasticsearch/analysis-ik/
6.重启所有节点的es,检查日志
systemctl restart elasticsearch.service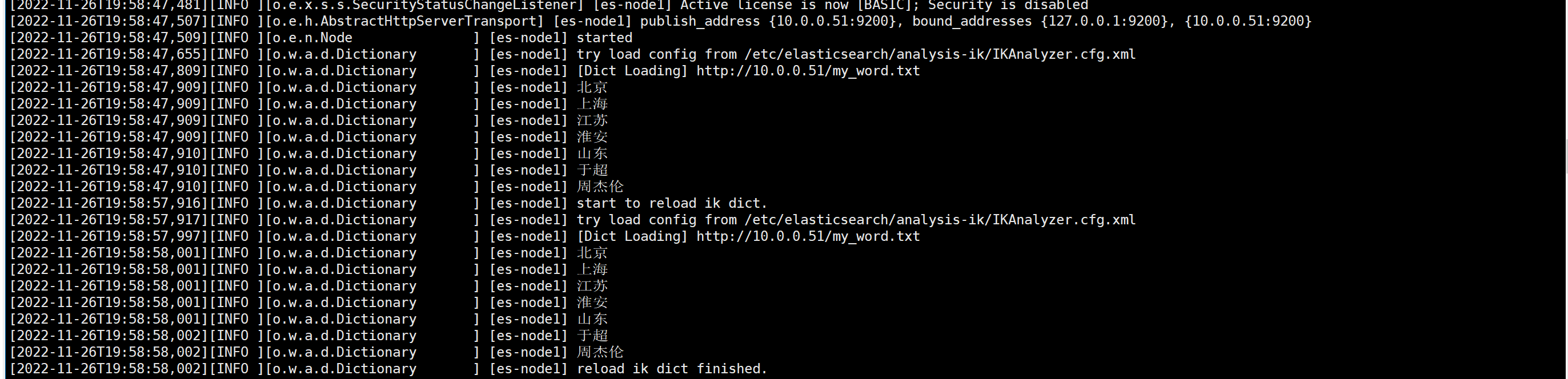
试试是否识别自定义中文词典
# 默认词库里是没有的
[root@es-node3 /etc/elasticsearch/analysis-ik]#grep '于超' main.dic
# 注意修改索引,采用中文分词插件
# 注意步骤,先创建index,修改属性
PUT /names/
PUT /names/_doc/_mapping?include_type_name=true
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
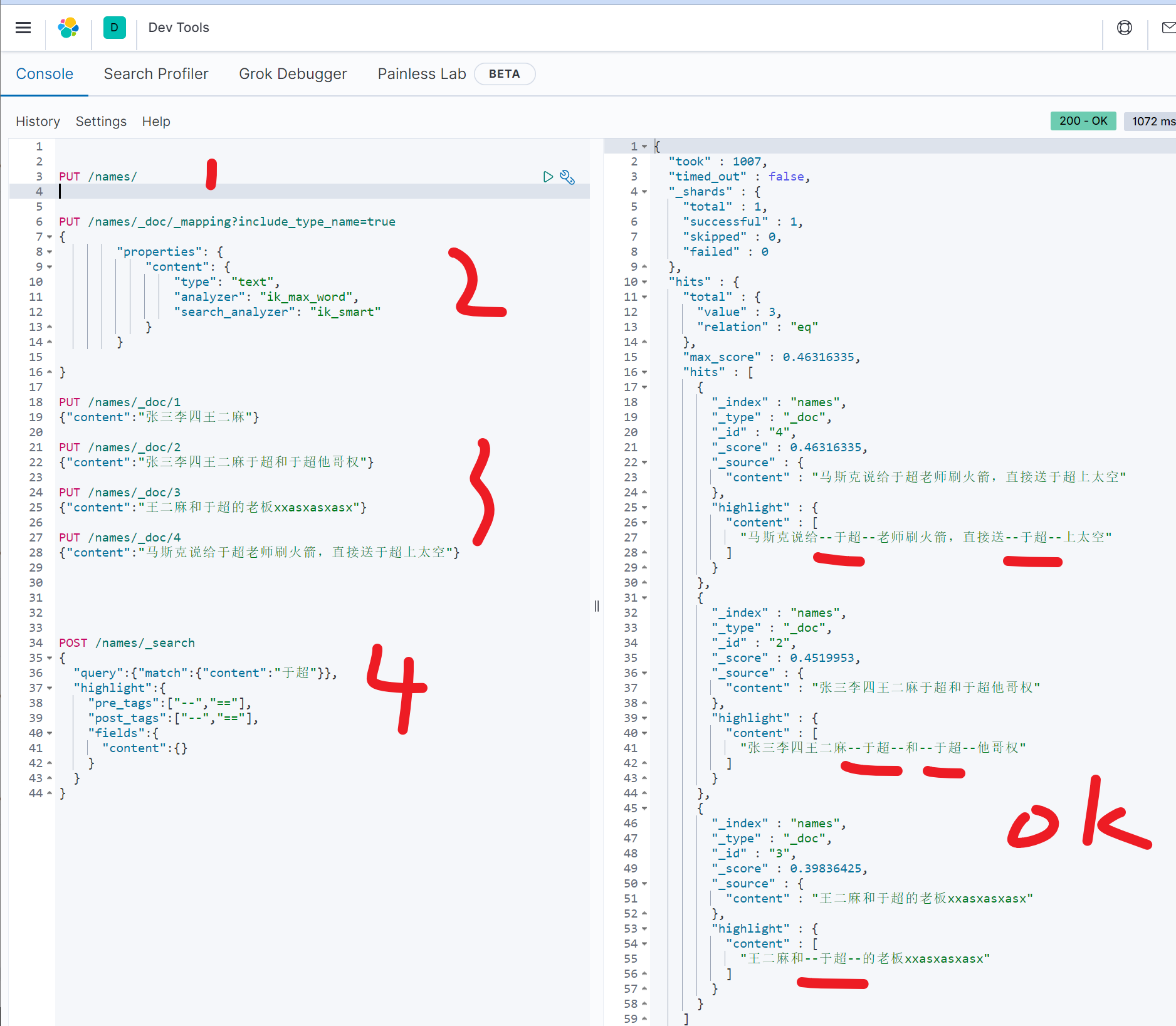
# 再写入数据
PUT /names/_doc/1
{"content":"张三李四王二麻"}
PUT /names/_doc/2
{"content":"张三李四王二麻于超和于超他哥权"}
PUT /names/_doc/3
{"content":"王二麻和于超的老板xxasxasxasx"}
PUT /names/_doc/4
{"content":"马斯克说给于超老师刷火箭,直接送于超上太空"}图示,提取了中文于超
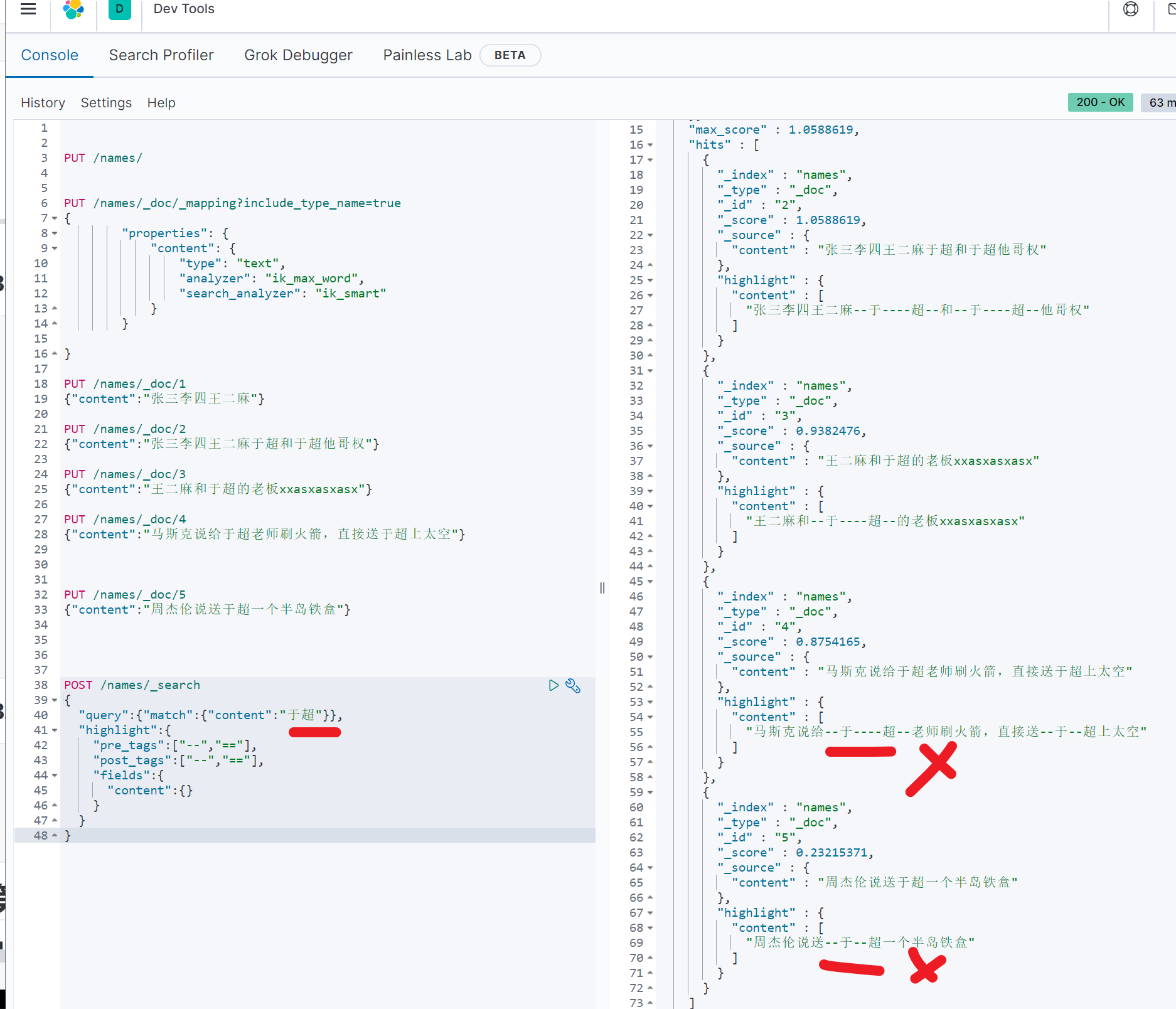
去掉词库的中文单词
es中文插件以支持nginx的热更新
去掉单词,于超
此时已经不认识了单词“于超”
再次添加nginx词典,热更新
1. 60s 更新时间
2. 注意,数据要更新index(公司里后端开发,会主动更新,新产品的关键词,更新词典,然后再录入数据)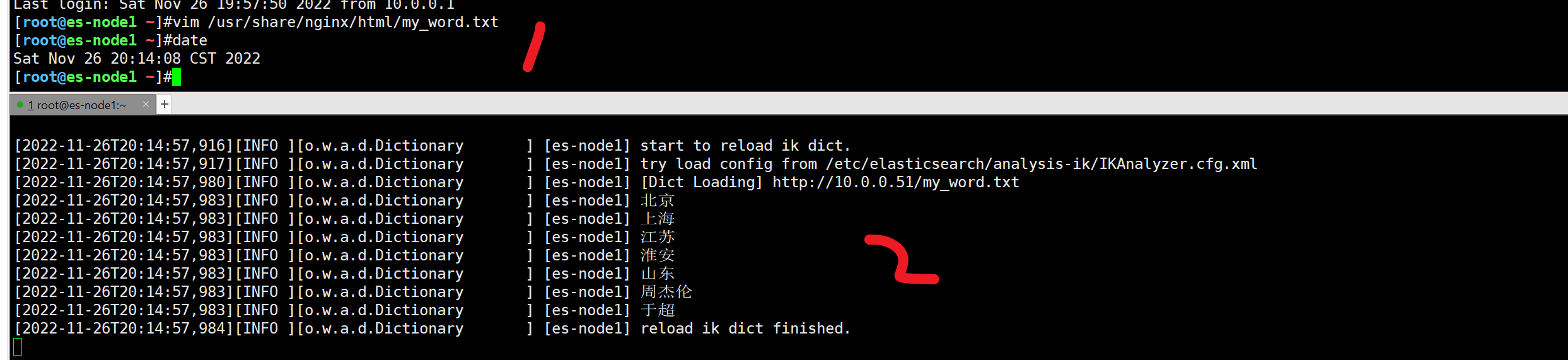

 浙公网安备 33010602011771号
浙公网安备 33010602011771号