
ES集群
1.ES集群基础概念
1.不需要了解太多java即可维护ES集群
2.部署简单,主从集群,从节点加入集群,自动同步数据
3.故障转移功能,节点故障,数据自动复制到其他节点
4.理解数据分片
主分片:存储数据节点,负责读写请求
副分片:主分片的副本,提供读请求
5.部署ES集群,至少2台机器2.ES两节点部署
# 准备2个新es节点,不要带有数据
# es-node1 10.0.0.51
# es-node2 10.0.0.52
1. 安装ES
[root@es-node1 ~]#ls /opt/
all-db.sql elasticsearch-7.9.1-x86_64.rpm kibana-7.9.1-x86_64.rpm
2. # 修改内存相关参数
systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
3.修改配置文件
# es-node1
cat > /etc/elasticsearch/elasticsearch.yml <<'EOF'
cluster.name: yuchao_es
node.name: es-node1
path.data: /var/lib/elasticsearch/
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: true
network.host: 127.0.0.1,10.0.0.51
http.port: 9200
discovery.seed_hosts: ["10.0.0.51","10.0.0.52"]
cluster.initial_master_nodes: ["10.0.0.51"]
EOF
# es-node2
cat > /etc/elasticsearch/elasticsearch.yml <<'EOF'
cluster.name: yuchao_es
node.name: es-node2
path.data: /var/lib/elasticsearch/
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: true
network.host: 127.0.0.1,10.0.0.52
http.port: 9200
discovery.seed_hosts: ["10.0.0.51","10.0.0.52"]
cluster.initial_master_nodes: ["10.0.0.51"]
EOF
# cluster.initial_master_nodes 作为初始化创建新es集群的作用,写一个节点就好
# 4.如果要清理原有es数据
systemctl stop elasticsearch
mv /var/lib/elasticsearch/* /tmp/es/
systemctl daemon-reload
systemctl restart elasticsearch
# 5.启动两个es
systemctl daemon-reload
systemctl restart elasticsearch
netstat -tunlp|grep 9200
curl 127.0.0.1:9200
# 6.检查es插件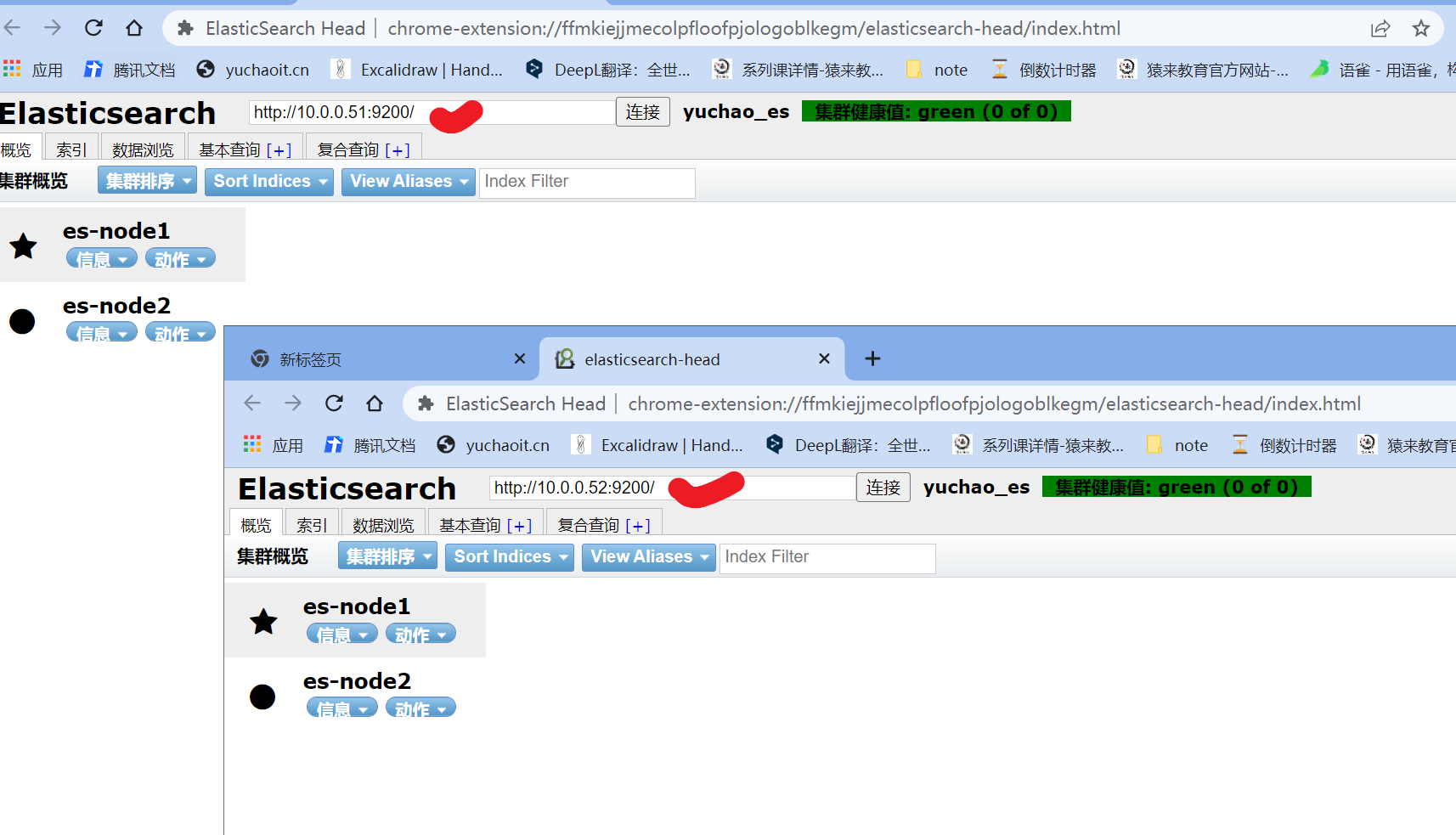
集群细节
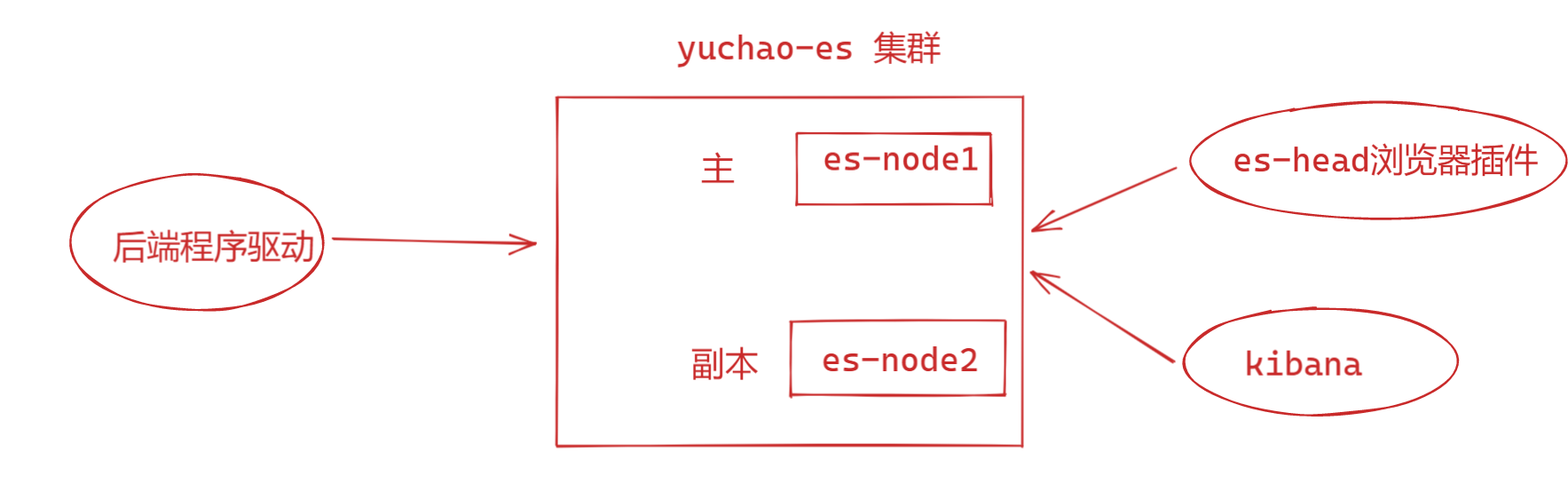
1. 读写可以在任一节点,es-head插件也是连接任一节点
2. 主节点负责读写请求,主节点挂了,父节点提升角色
3. es端口是 9200、9300
[root@es-node1 ~]#netstat -tunlp|grep java
tcp6 0 0 10.0.0.51:9200 :::* LISTEN 8813/java
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 8813/java
tcp6 0 0 10.0.0.51:9300 :::* LISTEN 8813/java
tcp6 0 0 127.0.0.1:9300 :::* LISTEN 8813/java
[root@es-node1 ~]#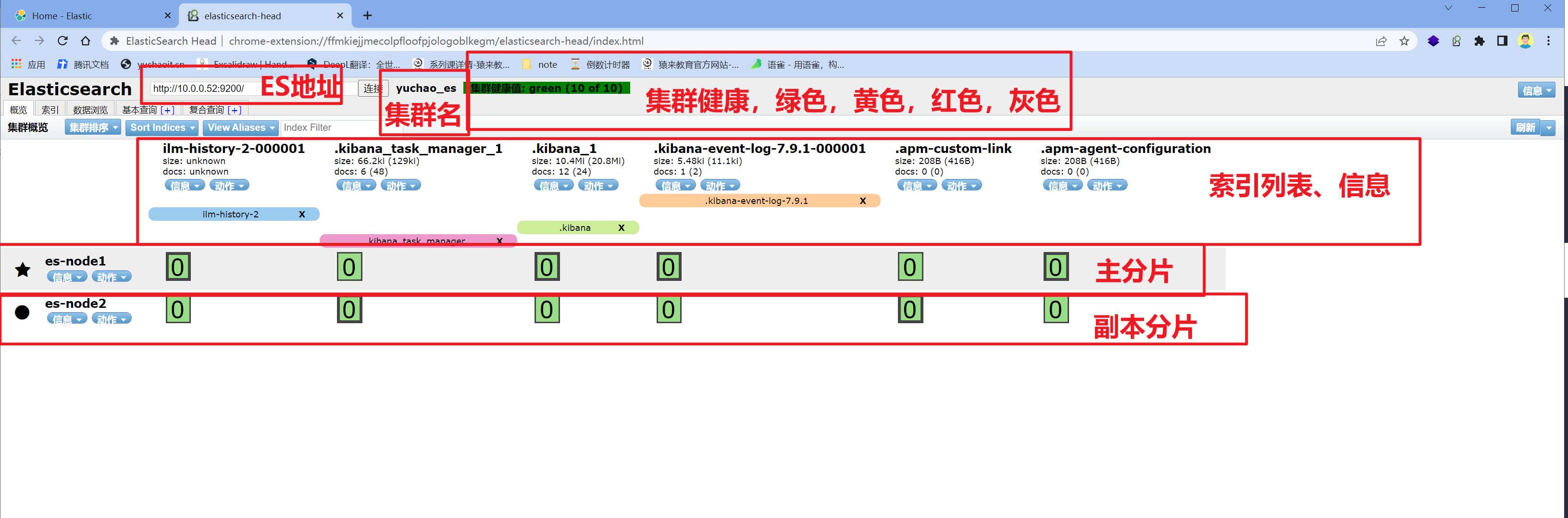
集群节点信息
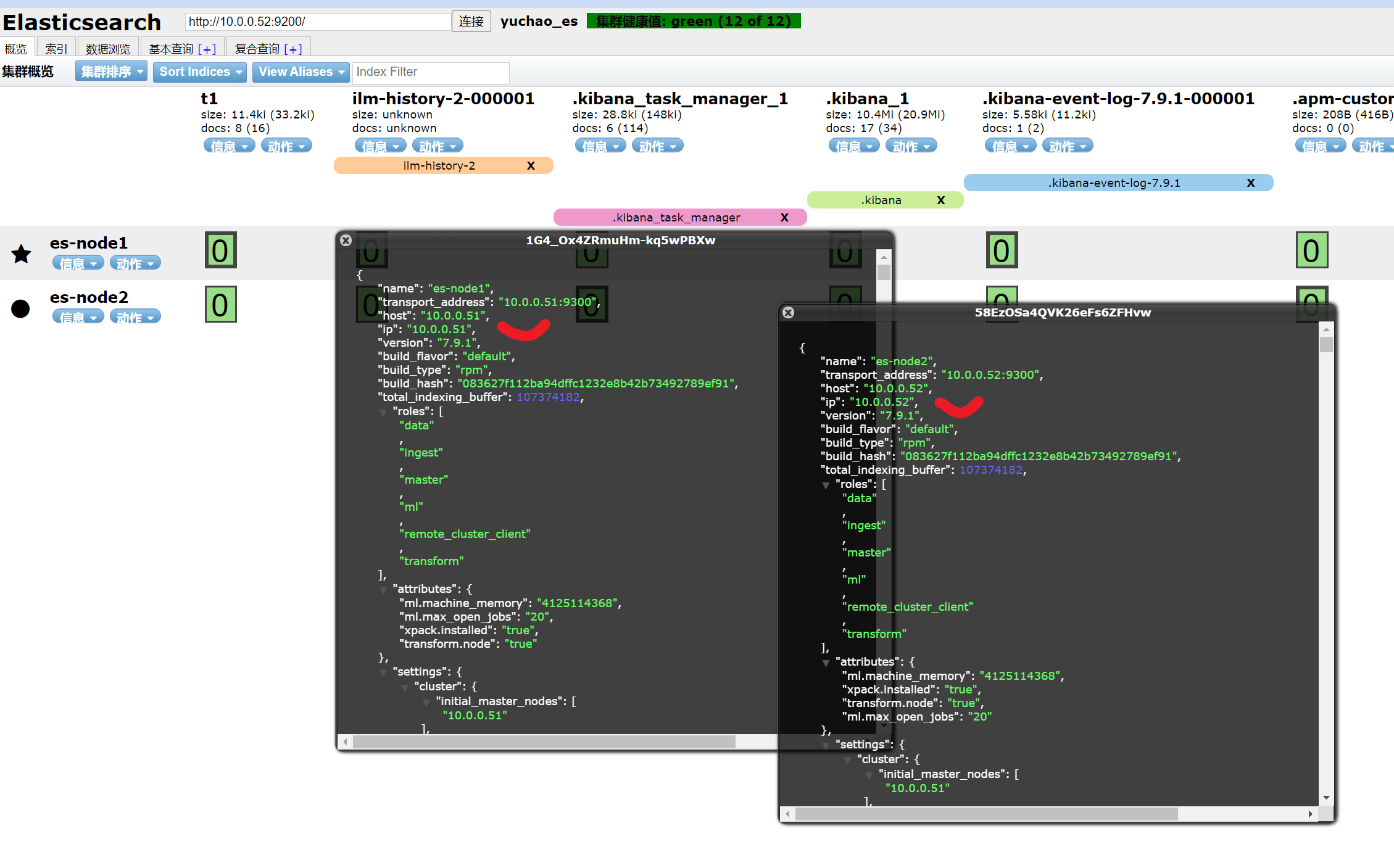
集群维护
创建index且定义副本与分片
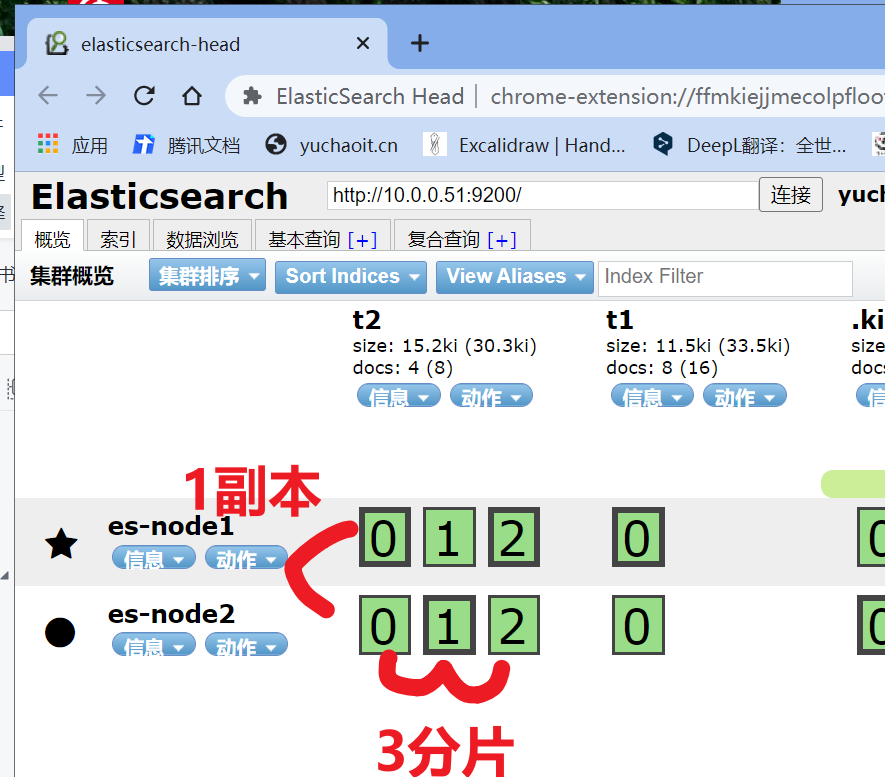
7.x版本es之后,默认一个分片,一个副本。
- 数据完整,表示分片正常
- 主分片读写,副本分片读。
put /t2/
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}
POST /t2/_doc
{
"website":"www.yuchaoit.cn"
}
#############负载均衡

集群颜色状态
绿色,数据完整,副本数正确。
黄色,数据完整,副本数错误。
红色,索引数据异常不完整。副本数异常,黄色
PUT /t2/_settings/
{
"settings":{
"number_of_replicas":2 # 将t2库的数据,设置2个副本。
}
}
# 黄色表示你某个es机器挂了,副本数不对了。
# es限制,一个机器,只能有一个i节点
# 恢复绿色
PUT /t2/_settings/
{
"settings":{
"number_of_replicas":1 # 将t2库的数据,设置2个副本。
}
}
# 修改所有索引的副本
PUT /_all/_settings/
{
"settings":{
"number_of_replicas":0
}
}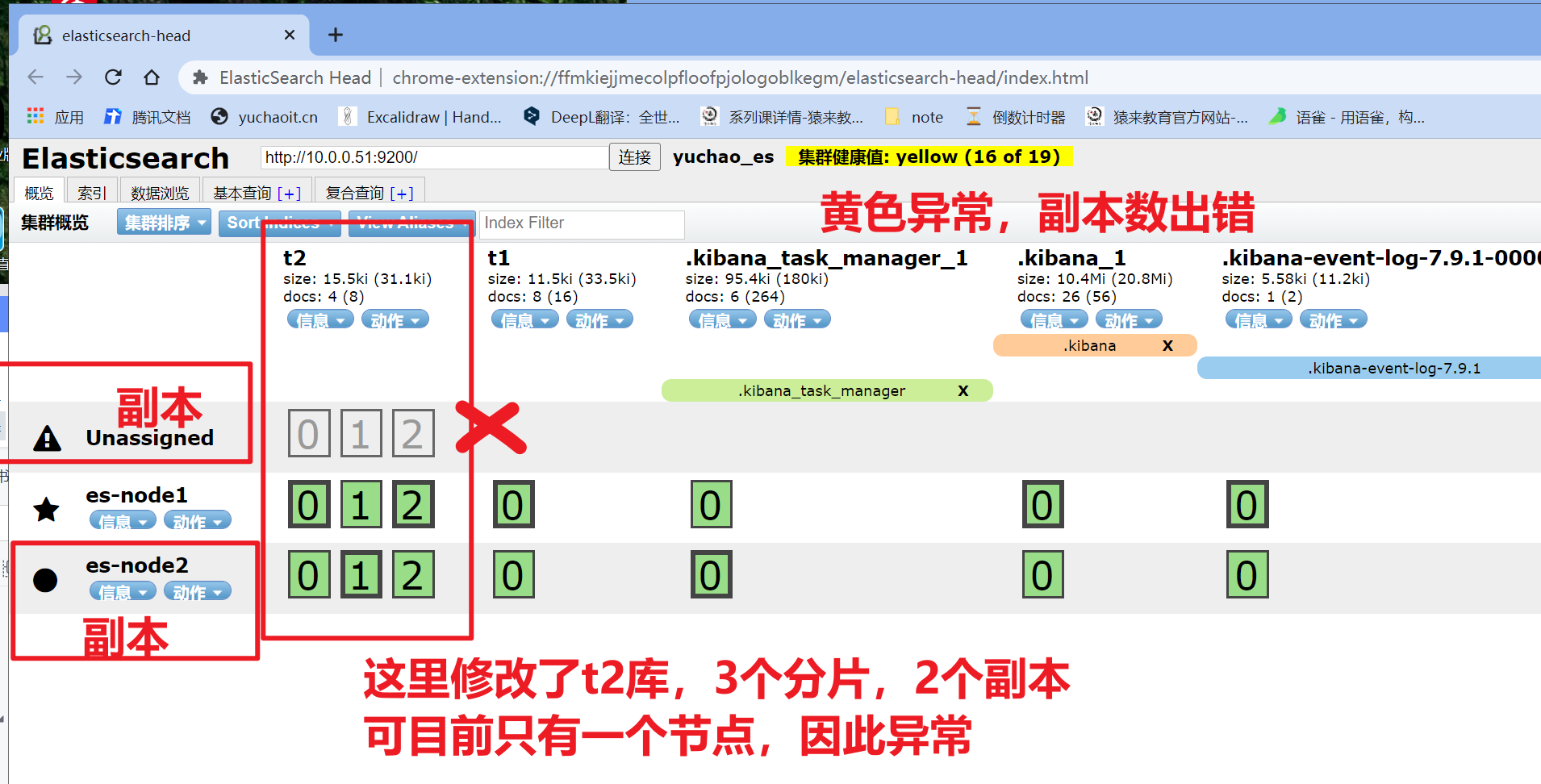
索引异常,红色
当某个索引出错,es集群提示红色。
ELK架构采用的index设置
3分片,1副本即可。
3.ES加入节点,3节点
1.直接复制超哥前面的部署文档,新加一个es机器
rpm -ivh elasticsearch-7.9.1-x86_64.rpm
2. # 修改内存相关参数
systemctl edit elasticsearch
[Service]
LimitMEMLOCK=infinity
3.修改配置文件,这里有坑,只需要写发现新节点即可
# 写入自身,集群任意节点都可以同步数据
# es-node1
cat > /etc/elasticsearch/elasticsearch.yml <<'EOF'
cluster.name: yuchao_es
node.name: es-node3
path.data: /var/lib/elasticsearch/
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: true
network.host: 127.0.0.1,10.0.0.53
http.port: 9200
discovery.seed_hosts: ["10.0.0.51","10.0.0.53"]
EOF
# 5.启动两个es
systemctl daemon-reload
systemctl restart elasticsearch
netstat -tunlp|grep 9200
curl 127.0.0.1:9200检查新3节点es集群状态
7.x系列的es默认副本规则是,1分片,1副本
有变化的是,我们自己设置的,原本的t2索引,规则是3分片,1副本
以及ES确保所有节点能负载均衡数据。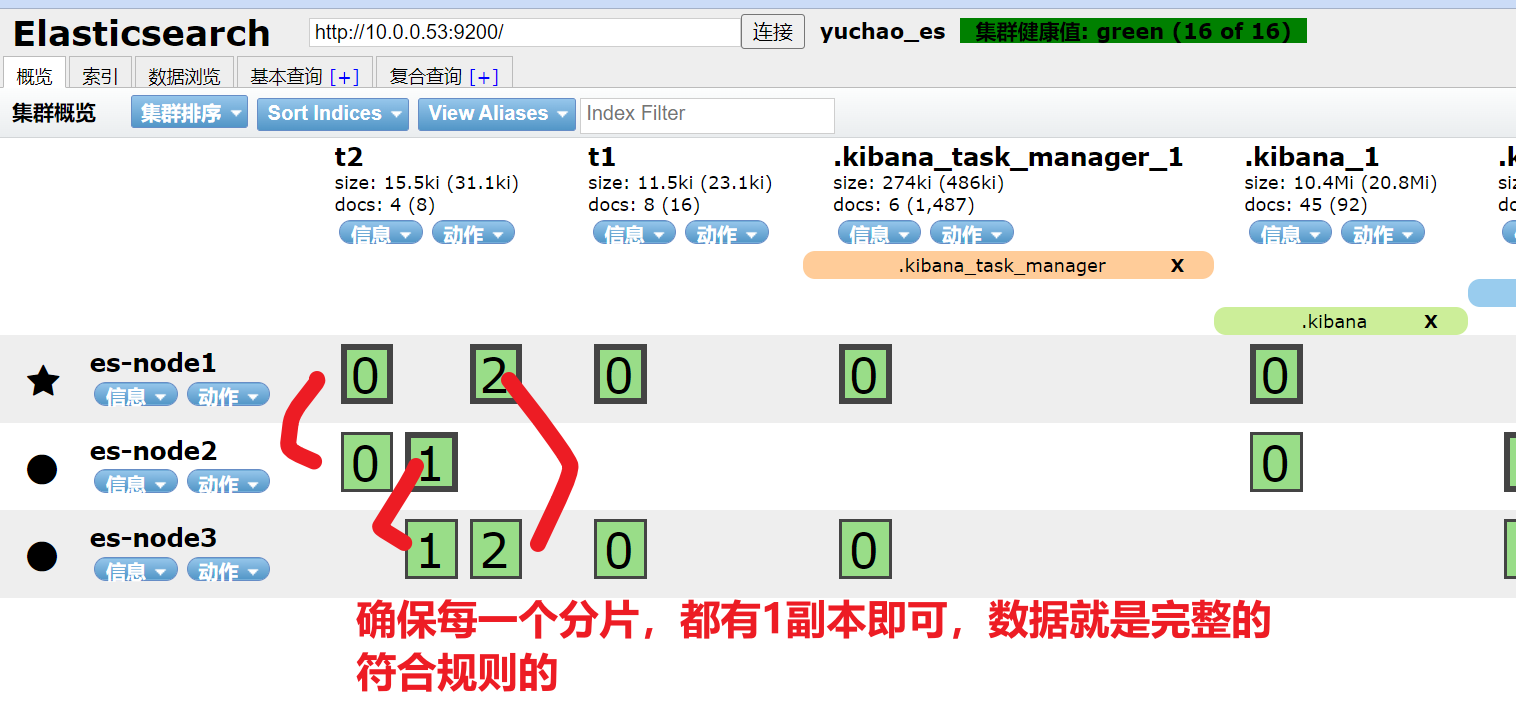

es节点故障情况
关闭es-node3
[root@es-node3 ~]#systemctl stop elasticsearch.service
[root@es-node3 ~]#
1.es集群会在短暂的故障后,将数据切换到其他节点,确保健康,以及保障index的分片、副本数。
2. es 7.x系列之后,要求,至少有2个节点正常,就是健康的。
3. es数据分片颜色状态(插件观察)
- 紫色,迁移中
- 黄色,复制中
- 绿色,正常
 浙公网安备 33010602011771号
浙公网安备 33010602011771号