极客时间《消息队列高手课》阅读笔记
极客时间《消息队列高手课》阅读笔记
消息队列实现分布式事务
在实际应用中,比较常见的分布式事务实现有 2PC(Two-phase Commit,也叫二阶段提交)、TCC(Try-Confirm-Cancel) 和事务消息。每一种实现都有其特定的使用场景,也有各自的问题,都不是完美的解决方案。这里只讨论「事务消息」的实现。
事务消息的核心原理就是先发送给mq一个消息,然后执行事务,通过执行事务的结果决定最开始的那条消息是否提交或者是回滚。流程如下图所示:

对于第四步提交事务消息时失败了的情况,RocketMq和Kafka有不同的处理:
- Kafka 的解决方案比较简单粗暴,直接抛出异常,让用户自行处理。我们可以在业务代码中反复重试提交,直到提交成功,或者删除之前创建的订单进行补偿。
- RocketMQ 则提供了一种MQ反查机制,即Broker 没有收到提交或者回滚的请求,Broker 会定期去 Producer 上反查这个事务对应的本地事务的状态,然后根据反查结果决定提交或者回滚这个事务。
因此,为了支持MQ的反查,业务方需要实现一个供Broker反查的接口。
消息不丢失以及重复消费
消息不丢失和重复消费是两个相反维度的问题,消息丢失导致消费者少消费消息,重复消费会导致消费者多消费消息
消息不丢失
消息从生产到消费会经历:Producer-》Broker-》Consumer的历程,在这个过程中,有几个地方可能会导致消息的丢失:
- 生产阶段:Producer没有生产出消息导致消息丢失。
- 存储阶段:Broker因为宕机等原因导致消息丢失。
- 消费阶段:Consumer拉取到消息后,还没正常消费就确认消费导致消息丢失。
消息生产到消费的过程如下图所示:

对于不同阶段产生的消息丢失,有不同的解决思路和方法:
- 生产阶段:在生产的时候,需要检查发送是否成功,如果不成功则重试。
对于生产阶段,有一定重复生产的可能,典型场景:Producer生产后,发现超时了,那么可能生产成功,也可能生产失败。对于这样「重复生产」的场景,个人建议是通过业务的幂等消费来保证「重复生产」对业务无损~
-
存储阶段:Broker的作用和数据库其实类似,都有持久化数据的作用,因此处理消息丢失和MySQL等类似思路,但是由于MQ没有WAL,因此解决方案:
- 在收到消息后,将消息写入磁盘后再给 Producer 返回确认响应。(例如,在 RocketMQ 中,需要将刷盘方式 flushDiskType 配置为 SYNC_FLUSH 同步刷盘。)
- MQ一般是高可用集群,因此需要合理配置kafka的quorum (选举数)这样的数字。
-
消费阶段:不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。
消费阶段这样的配置解决消息丢失的问题的同时,会与生产阶段类似,引入「重复消费」的问题。
重复消费
对于消息消费,MQTT中定义了三种消息消费等级如下,这个服务质量标准不仅适用于 MQTT,对所有的消息队列都是适用的。
- At most once: 至多一次。消息在传递时,最多会被送达一次。换一个说法就是,没什么消息可靠性保证,允许丢消息。一般都是一些对消息可靠性要求不太高的监控场景使用,比如每分钟上报一次机房温度数据,可以接受数据少量丢失。
- At least once: 至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
- Exactly once:恰好一次
一般解决重复消息的办法是,在消费端,让我们消费消息的操作具备幂等性。
从对系统的影响结果来说:At least once + 幂等消费 = Exactly once。
Kafka 支持的“Exactly once”和我们刚刚提到的消息传递的服务质量标准“Exactly once”是不一样的,它是 Kafka 提供的另外一个特性,Kafka 中支持的事务也和我们通常意义理解的事务有一定的差异。在 Kafka 中,事务和 Excactly once 主要是为了配合流计算使用的特性,
再聊聊kafka中的事务与“Exactly once”
前文中我们有提到 消息队列的事务 和 kafka中的“Exactly once”是为了配合流计算使用保证“Exactly once”,本节就来聊一聊这是怎么回事。
事务
首先是「kafka中的事务」,其概念与rocketmq不同,rocketmq中的事务是为了实现分布式事务,而kafka中的事务则是实现:确保在一个事务中发送的多条消息,要么都成功,要么都失败。注意,这里面的多条消息不一定要在同一个主题和分区中,可以是发往多个主题和分区的消息。当然,你可以在 Kafka 的事务执行过程中,加入本地事务,来实现和 RocketMQ 中事务类似的效果,但是 Kafka 是没有事务反查机制的。
kafka事务的流程举例:
首先,当我们开启事务的时候,生产者会给协调者发一个请求来开启事务,协调者在事务日志中记录下事务 ID。
然后,生产者在发送消息之前,还要给协调者发送请求,告知发送的消息属于哪个主题和分区,这个信息也会被协调者记录在事务日志中。接下来,生产者就可以像发送普通消息一样来发送事务消息,这里和 RocketMQ 不同的是,RocketMQ 选择把未提交的事务消息保存在特殊的队列中,而 Kafka 在处理未提交的事务消息时,和普通消息是一样的,直接发给 Broker,保存在这些消息对应的分区中,Kafka 会在客户端的消费者中,暂时过滤未提交的事务消息。
消息发送完成后,生产者给协调者发送提交或回滚事务的请求,由协调者来开始两阶段提交,完成事务。第一阶段,协调者把事务的状态设置为“预提交”,并写入事务日志。到这里,实际上事务已经成功了,无论接下来发生什么情况,事务最终都会被提交。
之后便开始第二阶段,协调者在事务相关的所有分区中,都会写一条“事务结束”的特殊消息,当 Kafka 的消费者,也就是客户端,读到这个事务结束的特殊消息之后,它就可以把之前暂时过滤的那些未提交的事务消息,放行给业务代码进行消费了。最后,协调者记录最后一条事务日志,标识这个事务已经结束了。

Exactly Once
Kafka 中的 Exactly Once 又是解决的什么问题呢?Kafka 的 Exactly Once 机制,是为了解决在“读数据 - 计算 - 保存结果”这样的计算过程中数据不重不丢,而不是我们通常理解的只消费一次。具体来说:其解决的是,在流计算中,用 Kafka 作为数据源,并且将计算结果保存到 Kafka 这种场景下,数据从 Kafka 的某个主题中消费,在计算集群中计算,再把计算结果保存在 Kafka 的其他主题中。这样的过程中,保证每条消息都被恰好计算一次,确保计算结果正确。
kafka与流计算Flink如何完成「端到端exactly once」
在开始之前我们先要知道:什么是端到端exactly once:如下面这张图所示,数据从 Kafka 的 A 主题消费,发送给 Flink 的计算集群进行计算,计算结果再发给 Kafka 的 B 主题。在这整个过程中,无论是 Kafka 集群的节点还是 Flink 集群的节点发生故障,都不会影响计算结果,每条消息只会被计算一次,不能多也不能少。

只有kafka的事务可没法保证「端到端的exactly once」,实际上「端到端的exactly once」的实现还需要依赖于Flink 的 CheckPoint 机制。
Flink 通过 CheckPoint 机制来定期保存计算任务的快照,这个快照中主要包含两个重要的数据:
- 整个计算任务的状态。这个状态主要是计算任务中,每个子任务在计算过程中需要保存的临时状态数据。比如,上节课例子中汇总了一半的数据。
- 数据源的位置信息。这个信息记录了在数据源的这个流中已经计算了哪些数据。如果数据源是 Kafka 的主题,这个位置信息就是 Kafka 主题中的消费位置。
有了 CheckPoint,当计算任务失败重启的时候,可以从最近的一个 CheckPoint 恢复计算任务。具体的做法是,每个子任务先从 CheckPoint 中读取并恢复自己的状态,然后整个计算任务从 CheckPoint 中记录的数据源位置开始消费数据,只要这个恢复位置和 CheckPoint 中每个子任务的状态是完全对应的,或者说,每个子任务的状态恰好是:“刚刚处理完恢复位置之前的那条数据,还没有开始处理恢复位置对应的这条数据”,这个时刻保存的状态,就可以做到严丝合缝地恢复计算任务,每一条数据既不会丢失也不会重复。
因为每个子任务分布在不同的节点上,并且数据是一直在子任务中流动的,所以确保 CheckPoint 中记录的恢复位置和每个子任务的状态完全对应并不是一件容易的事儿,Flink 是怎么实现的呢?
Flink 通过在数据流中插入一个 Barrier(屏障)来确保 CheckPoint 中的位置和状态完全对应。下面这张图来自Flink 官网的说明文档。
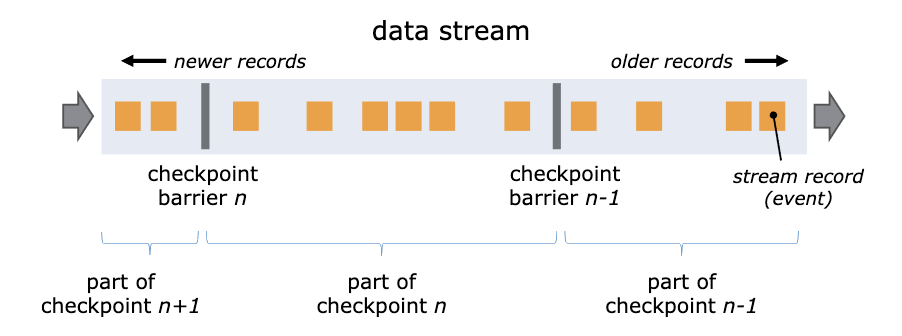
每个 Flink 的 CheckPoint 对应一个 Kafka 事务。Flink 在创建一个 CheckPoint 的时候,同时开启一个 Kafka 的事务,完成 CheckPoint 同时提交 Kafka 的事务。当计算任务重启的时候,在 Flink 中计算任务会恢复到上一个 CheckPoint,这个 CheckPoint 正好对应 Kafka 上一个成功提交的事务。未完成的 CheckPoint 和未提交的事务中的消息都会被丢弃,这样就实现了端到端的 Exactly Once。
至于「完成 CheckPoint 同时提交 Kafka 的事务」这就是一个典型的分布式事务了~
在公司的woator建设中,就存在一条链路:kafka-》streamsql-》kafka-》下游
完整链路为:mysql --binlog--》kafka-》streamsql-》kafka-》datasource(数据源)-》指标计算
👋 大家好,我是思无邪,某go中厂开发工程师,也是OSPP2024的学生参与者!
🚀 如果你觉得我的文章有帮助,记得三连支持一下哦!
🍂 目前正在深入研究源码,与你们一起进步,共同攻克编程难关!
📝 欢迎关注我的公众号【小菜先生的编程随想】,一起学习、一起成长!💡

 浙公网安备 33010602011771号
浙公网安备 33010602011771号