
Python高级应用程序设计任务要求
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取链家北京地区的房地产信息
2.主题式网络爬虫爬取的内容与数据特征分析
爬取房子的地区与价格分布,分析其关系
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
python鼓励解耦合开发及时功能的拆分和模块的相对独立,所以本次方案我选择用scrapy爬虫框架进行爬取相关信息,
技术难点:爬虫文件编写的整体逻辑和框架配置,作图
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
经过很多次试探发现,他的翻页是由pg里面的参数定的,所以可以将目标网页后面参数改成pg{},然后用rang遍历自己要的页面数量
2.Htmls页面解析
右键点击自己想查看的参数就可以得到源码位置,下面几个是我要爬取的参数,分别是住房名字,房子类型,价钱,地区,
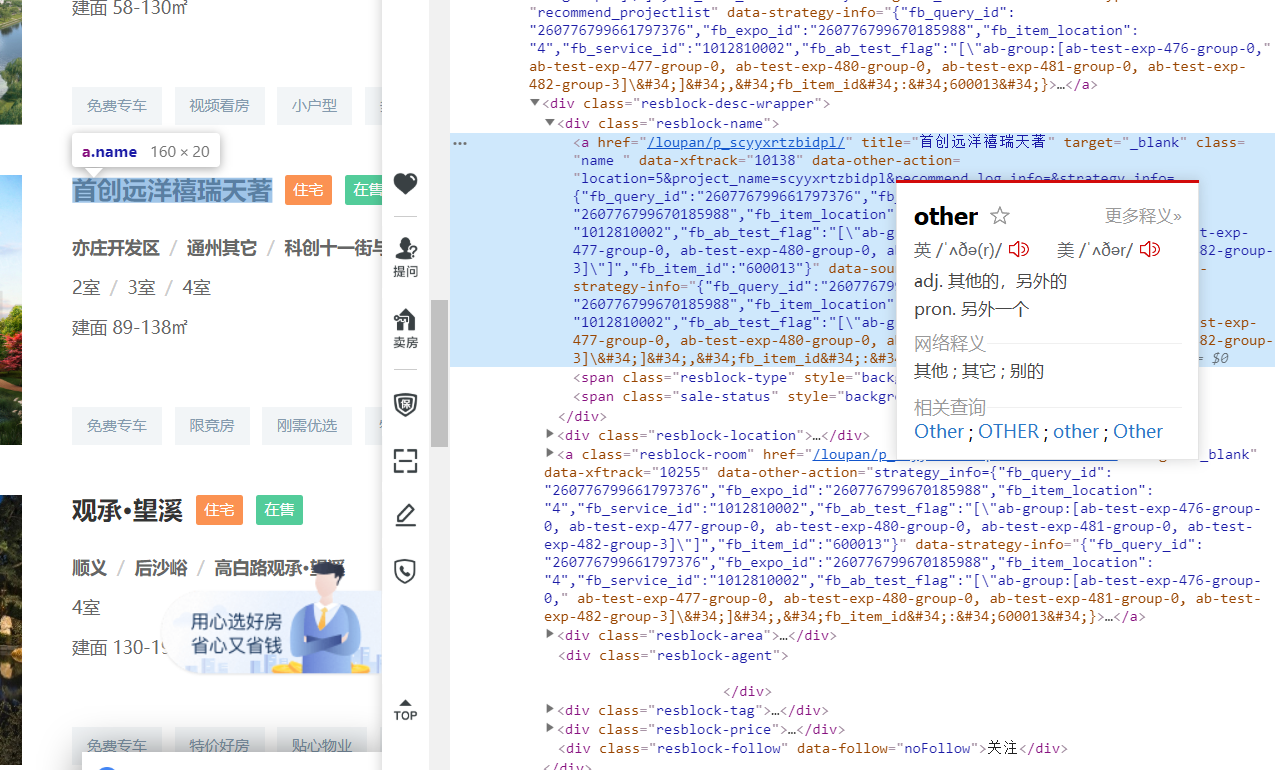

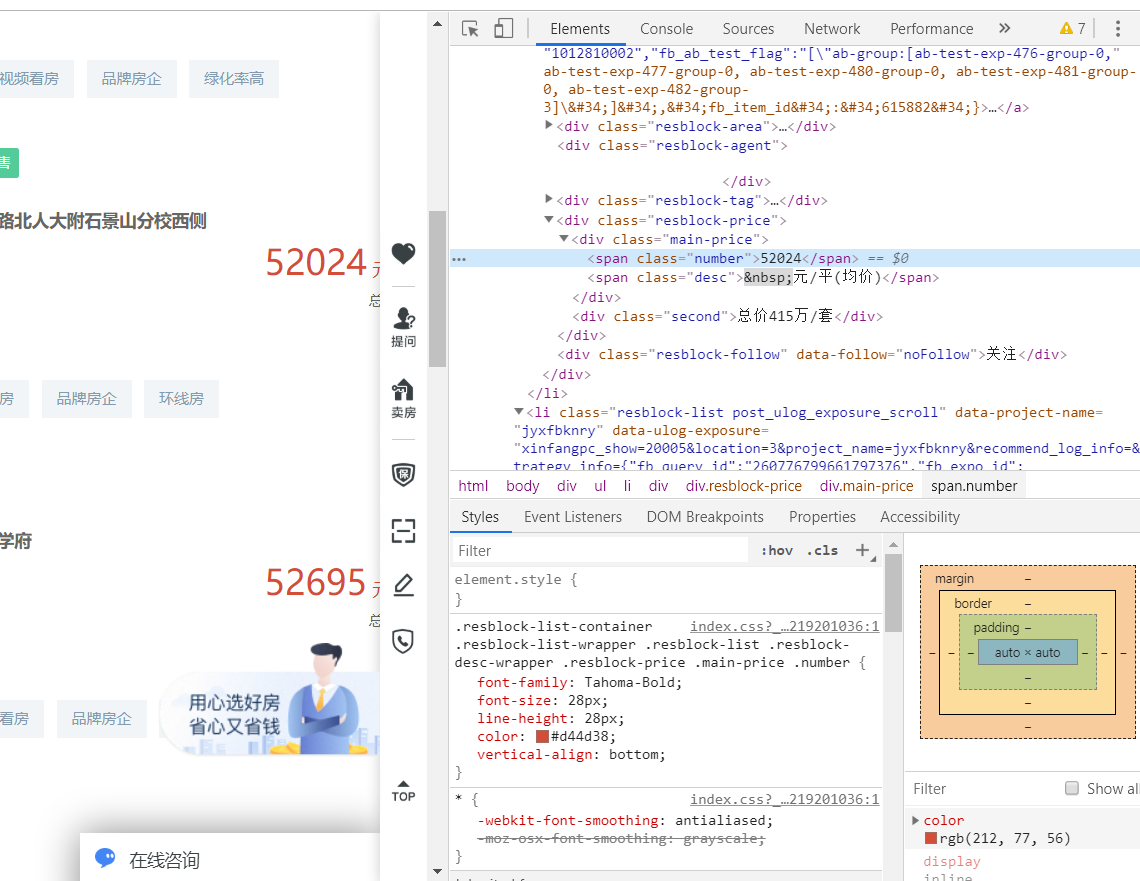

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
我要爬取的东西是在li标签里的,所以我要获取每个楼盘的li,遍历每个li标签,获取想要的字段
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
我做了两次,一次是不做筛选一次是做筛选的
不做筛选:
# -*- coding: utf-8 -*- import scrapy import json # 导入 item 开启管道,关闭机器人协议 from demo.items import DemoItem class LianjiaSpider(scrapy.Spider): name = 'lianjia' allowed_domains = ['liania.com'] # 链家的 api,共21页数据 start_urls = [f'https://bj.fang.lianjia.com/loupan/pg{i}/?_t=1' for i in range(1, 22)] def parse(self, response): # 将返回的数据转格式,否则可能会有ascii码显示的中文 data = json.loads(response.body.decode()) item = DemoItem() item['data'] = data['data']['list'] yield item
做筛选,这里我用的xpath爬取的,比较简单一点
# -*- coding: utf-8 -*- import scrapy import json # 导入 item 开启管道,关闭机器人协议 from demo.items import DemoItem class LianjiaSpider(scrapy.Spider): name = 'lianjia' allowed_domains = ['liania.com'] # 共21页数据 start_urls = ['https://bj.fang.lianjia.com/loupan/pg{i}/' for i in range(1,22)] def parse(self, response): li_list = response.xpath('//ul[@class="resblock-list-wrapper"]/li') # 遍历每个li标签,获取想要的字段 for li in li_list: # 楼盘 title = li.xpath('./a/@title').extract()[0] print(title) # 地区 area = li.xpath('.//div[@class="resblock-location"]/span[1]/text()').extract()[0] print(area) # 类型 type_name = li.xpath('.//span[@class="resblock-type"]/text()').extract()[0] print(type_name) # 均价(元/平米) price = li.xpath('.//span[@class="number"]/text()').extract()[0] print(price) # 存入item item = DemoItem() item['title'] = title item['type_name'] = type_name item['price'] = price item['area'] = area yield item
这是我运行main爬下来的数据,这里我遇到了个问题,就是vsc不会切换目录,导致我一直运行失败,每次都要在命令行手动切换到我的demo目录,好像pycharm不会出现这个问题,但是我卸了后没下载了,因为我的vsc是当时aconda里下载的,后来懒得弄其他的编译器了

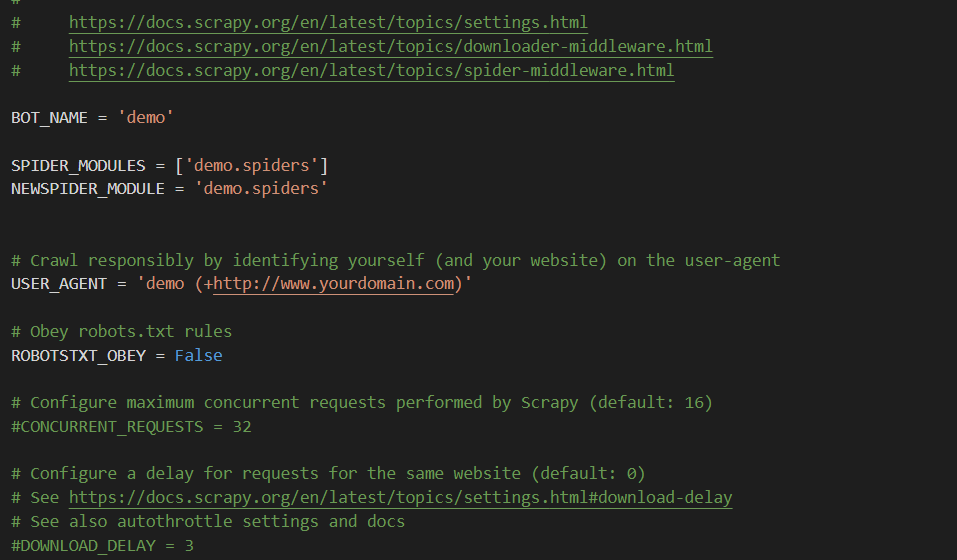
还有我其他的框架文件,下面这个是setting文件,大部分网站会有机器人协议,去settings里设置一下,USER_AGENT这里是一个简单的伪装用来防反爬
我那个demo由于需要存数据嘛,就开了item,类里面的字段相当于一个数据库建模,之前代码里有写,我那个代码可以把这个类实例化传参的
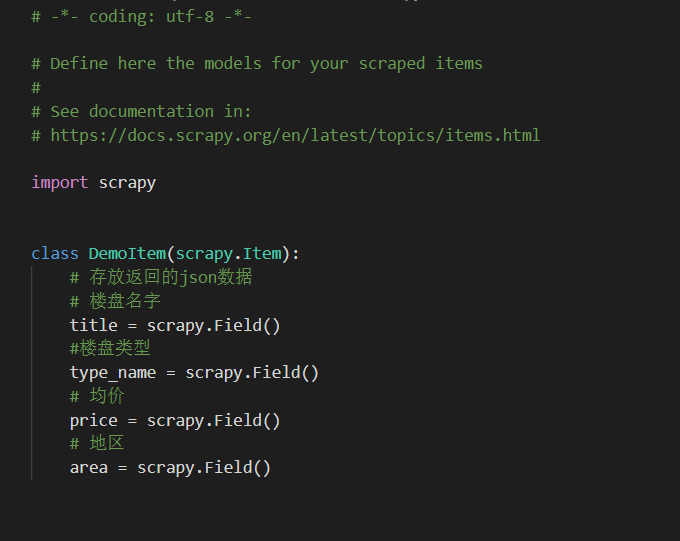
然后items的数据给pipeine来处理,这样就不会出现多线程导致的数据问题了
pipeline:
2.对数据进行清洗和处理
因为我后来改良了,在爬取的时候专门选了我自己需要的数据,所以不需要清洗,不过之前我是有做的,那是因为爬下来的时候没做过滤选择,之前的数据清洗代码在下面
import json with open('lianjia.json', 'r') as f: # 读取为处理的数据,并转换为列表 data = json.load(f) # 创键存放数据的容器 data_list = [] for i in data: # 楼盘名字 name = i.get('title') # 地区 district_name = i.get('district_name') # 类型 house_type = i.get('house_type') # 均价 avg_price = i.get('show_price') print(name) print(district_name) print(house_type) print(avg_price) data_list.append({'楼盘': name, '地区': district_name, '类型': house_type, '均价(元/平米)': avg_price}) with open('done_data.json', 'w') as f: # 将数据再写入done_data.json json.dump(data_list, f, ensure_ascii=False)
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
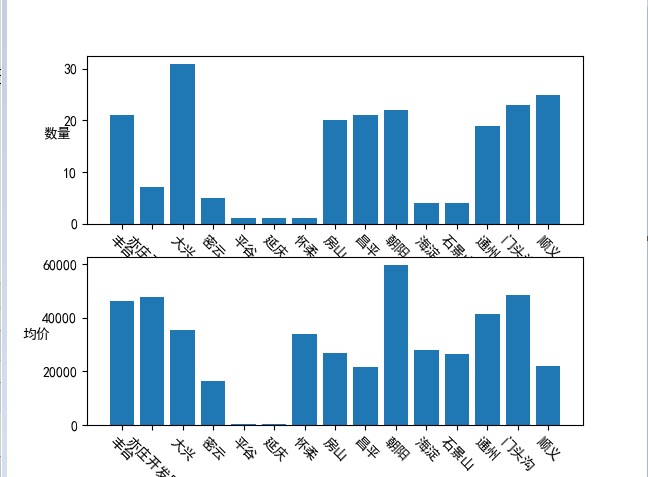
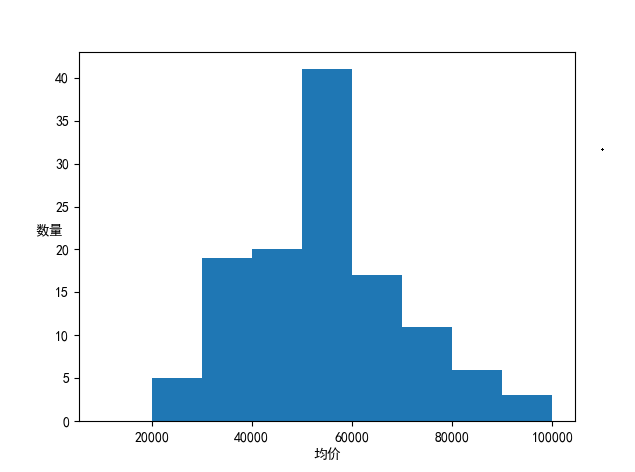
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
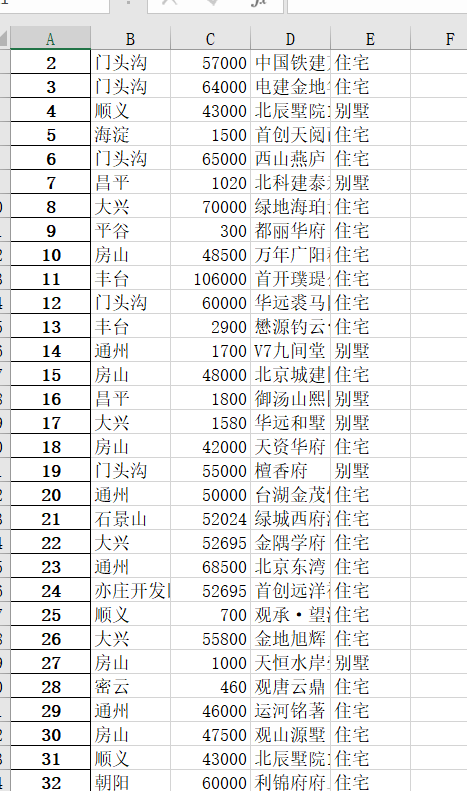
5.数据持久化
6.附完整程序代码
代码太多了
这里我把作图的程序放上,我觉得这部分还是挺难的
import matplotlib.pyplot as plt import json import pandas as pd # 读取 json 文件数据 def func(): with open('../demo/lianjia.json','r',encoding='utf8')as fp: data = json.load(fp) loupan = [] diqu = [] leixing = [] price = [] for i in data: loupan.append(i.get('楼盘')) diqu.append(i.get('地区')) leixing.append(i.get('类型')) price.append(int(i.get('均价(元/平米)'))) data= {'楼盘':loupan,'地区':diqu,'类型':leixing,'均价':price} # 转为DataFrane 格式数据 df1 = pd.DataFrame(data) #df1.to_excel('链家.xlsx') # 数据清洗 index1 = df1['均价']==0 index1 = df1[index1].index df1.drop(labels=index1, axis=0, inplace=True) # # 去除 均价为0 的行 有两行 # 小数定标标准化 # df1['均价'] = df1['均价']/10**np.ceil(np.log10(df1['均价'].max())) # print(df1) #分析数据 # print(df1['均价'].max()) # 最大值 99500 # print(df1['均价'].min()) # 最小值 1000 # print(type(df1['均价'])) salary = [int(i) for i in df1['均价']] #salary = list(df1['均价']) # --------------------------------- # 总体图 plt.figure() #修改默认字体 plt.rcParams['font.sans-serif'] = 'SimHei' #正常显示符号,解决方块问题 plt.rcParams['axes.unicode_minus'] = False group = [i for i in range(10000,110000,10000)] plt.hist(salary,group) plt.xlabel('均价') plt.ylabel('数量',rotation = 0) plt.savefig('总体.png') # --------------------------------- # 分类图 # data1 = df1[['地区', '楼盘']].groupby(by='地区').count().reset_index() diqu1 = list(data1['地区']) diqu = [i for i in range(len(diqu1))] geshu = list(data1['楼盘']) geshu = [int(i) for i in geshu] p1 = plt.figure() plt.rcParams['font.sans-serif'] = 'SimHei' #正常显示符号,解决方块问题 plt.rcParams['axes.unicode_minus'] = False p1.add_subplot(2,1,1) plt.bar(diqu,geshu) plt.xlabel('地区') plt.ylabel('数量',rotation = 0) plt.xticks(diqu,diqu1) # 第二张图 p1.add_subplot(2,1,2) data2 = df1[['地区', '均价']].groupby(by='地区').mean().reset_index() print(data2) diqu1 = list(data2['地区']) diqu = [i for i in range(len(diqu1))] junjia = list(data2['均价']) #junjia = [i for i in junjia] plt.bar(diqu,junjia) plt.xlabel('地区') plt.ylabel('均价',rotation = 0) plt.xticks(diqu,diqu1) plt.savefig('分类.png') plt.show() if __name__ == '__main__': func()
这里我有的注释掉了,因为excel只输出一份就够了,其他几个print是写的时候看看有没有0值什么的
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
得到了一个结论就是,哪怕北京最便宜的地段的房我也买不起
还有用各地段的平均房价,可以来判断繁华程度,离市中心越近越贵
这里的数据是有一点问题的,就是平谷只有一个房源,而且标价是一套而不是每平米,所以图出现了问题,我还是后来搜发现的
2.对本次程序设计任务完成的情况做一个简单的小结。
学到了很多,知道了scrapy框架里的东西都是干嘛的,也懂了很多以前不知道的东西,深入了解了python的特性.也学到了很多的英语单词

