
第一次个人编程作业
| Info | Detail |
|---|---|
| 作业要求 | 🔗作业链接 |
| 所属课程 | 🔗班级链接 |
| 这个作业的目标 | 尝试自己编程并且写单元测试和性能测试 |
| 学号 | 3123004223 |
| 仓库 | 🔗Github仓库 |
论文查重系统
这是一个基于中文自然语言处理的论文查重系统,能够计算两篇文档之间的相似度。系统采用双轨算法设计,支持基于 TF-IDF 的快速相似度计算和基于词向量的语义相似度计算,能够有效识别同义词替换、词序调整等常见的抄袭手法。
使用说明
环境要求
- Python 3.8+
- 依赖包:jieba, numpy, scikit-learn, gensim
下载词向量模型
本系统需要使用预训练的中文词向量模型以获得最佳性能。请从以下地址下载:
- 访问 Chinese-Word-Vectors 项目
- 下载推荐的模型(如:sgns.wiki.word)
- 将下载的模型文件放置在项目的
models目录下
注意:如果没有词向量模型,系统会自动退化为使用 TF-IDF 算法,但语义理解能力会有所降低。
安装依赖
pip install -r requirements.txt
# 或使用 uv
uv pip install -r requirements.txt
运行方法
python main.py <原文文件路径> <抄袭版文件路径> <输出文件路径>
示例:
python main.py ./data/orig.txt ./data/orig_0.8_add.txt ./data/result.txt
输出结果
程序会在指定的输出文件中写入一个浮点数,表示两篇文档的相似度(百分比),精确到小数点后两位。
迭代版本
TF-IDF&余弦相似度
计算文本的 TF-IDF 向量,然后计算两个向量的余弦相似度。
优点
- 简单,计算快
- 可以应对简单的顺序替换
不足
- 无法处理语义相似的文本(同义词)
使用 jieba 分词,配合文本向量模型计算相似度
使用 jieba 分词,将文本分成单词,然后使用文本向量模型计算相似度。
优点
- 可以处理语义相似的文本(同义词)
不足
- 计算量较大,速度较慢
测试结果
优化前
PS C:\Users\suyiiyii\Documents\git\se_assignment\3123004223\similarity_detection> uv run .\main.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\suyiiyii\AppData\Local\Temp\jieba.cache
Loading model cost 0.483 seconds.
Prefix dict has been built successfully.
orig_0.8_add.txt: 86.41%
orig_0.8_del.txt: 87.83%
orig_0.8_dis_1.txt: 96.57%
orig_0.8_dis_10.txt: 88.05%
orig_0.8_dis_15.txt: 71.33%
优化后
PS C:\Users\suyiiyii\Documents\git\se_assignment\3123004223\similarity_detection> uv run .\main.py
正在加载中文词向量模型...
中文词向量模型加载完成
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\suyiiyii\AppData\Local\Temp\jieba.cache
Loading model cost 0.577 seconds.
Prefix dict has been built successfully.
orig_0.8_add.txt: 99.59%
orig_0.8_del.txt: 99.79%
orig_0.8_dis_1.txt: 99.97%
orig_0.8_dis_10.txt: 99.86%
orig_0.8_dis_15.txt: 99.55%
可见优化效果非常显著
PSP2.1
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | ||
| · Analysis | 需求分析 (包括学习新技术) | 120 | 60 |
| · Design Spec | 生成设计文档 | 20 | 10 |
| · Design Review | 设计复审 | 10 | 10 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 80 |
| · Design | 具体设计 | 20 | 20 |
| · Coding | 具体编码 | 60 | 20 |
| · Code Review | 代码复审 | 10 | 5 |
| · Test | 测试(自我测试,修改代码,提交修改) | 120 | 100 |
| Reporting | 报告 | ||
| · Test Report | 测试报告 | 30 | 20 |
| · Size Measurement | 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| Total | 合计 | 530 | 375 |
计算模块接口的设计与实现过程
代码组织结构
本项目主要由以下几个模块组成:
- 主模块 (
main.py): 包含主要的执行逻辑和入口函数 - 计算模块: 包含相似度计算的核心算法
calculate_similarity: 主要的相似度计算接口calculate_similarity_with_embeddings: 基于词向量的相似度计算calculate_similarity_tfidf: 基于 TF-IDF 的相似度计算
- 工具模块: 包含加载模型等辅助功能
load_word_vectors: 加载预训练词向量模型
核心模块关系图
程序运行流程图
算法关键点
-
双轨算法设计:系统提供两种计算方法,根据环境自动选择最优算法
- 当词向量模型可用时,使用语义相似度计算
- 模型不可用时,自动回退到 TF-IDF 方法
-
语义理解能力:通过使用词向量模型,算法能够理解语义上相似但表达不同的文本
-
中文分词优化:使用 jieba 分词库,对中文文本进行精确分词,提高了相似度计算的准确性
独到之处
本算法的独到之处在于结合了两种相似度计算方法的优点:
- TF-IDF 方法计算速度快,适用于大规模文本
- 词向量方法语义理解能力强,能够识别同义词替换和语序变化
- 自适应切换机制确保了在不同环境下的最佳性能表现
计算模块接口部分的性能改进
改进思路
-
模型加载优化
- 实现模型懒加载,仅在必要时加载
- 添加模型缓存机制,避免重复加载
-
分词效率提升
- 使用 jieba 的并行分词模式
- 针对常见词汇添加自定义词典
-
向量计算优化
- 使用 NumPy 向量化操作代替循环
- 实现批量向量计算,减少 I/O 操作
性能瓶颈分析
使用 viztracer 性能分析工具对程序进行了全方位的性能测试和分析。通过生成的火焰图,我们可以清晰地看到程序的性能特征和瓶颈所在。
整体性能分析

从火焰图可以观察到,程序的执行时间主要集中在模型加载阶段。这是由于使用了预训练的词向量模型所导致的必要开销(overhead)。虽然模型加载时间较长,但这是一次性开销,对后续的计算性能影响较小。
计算过程分析

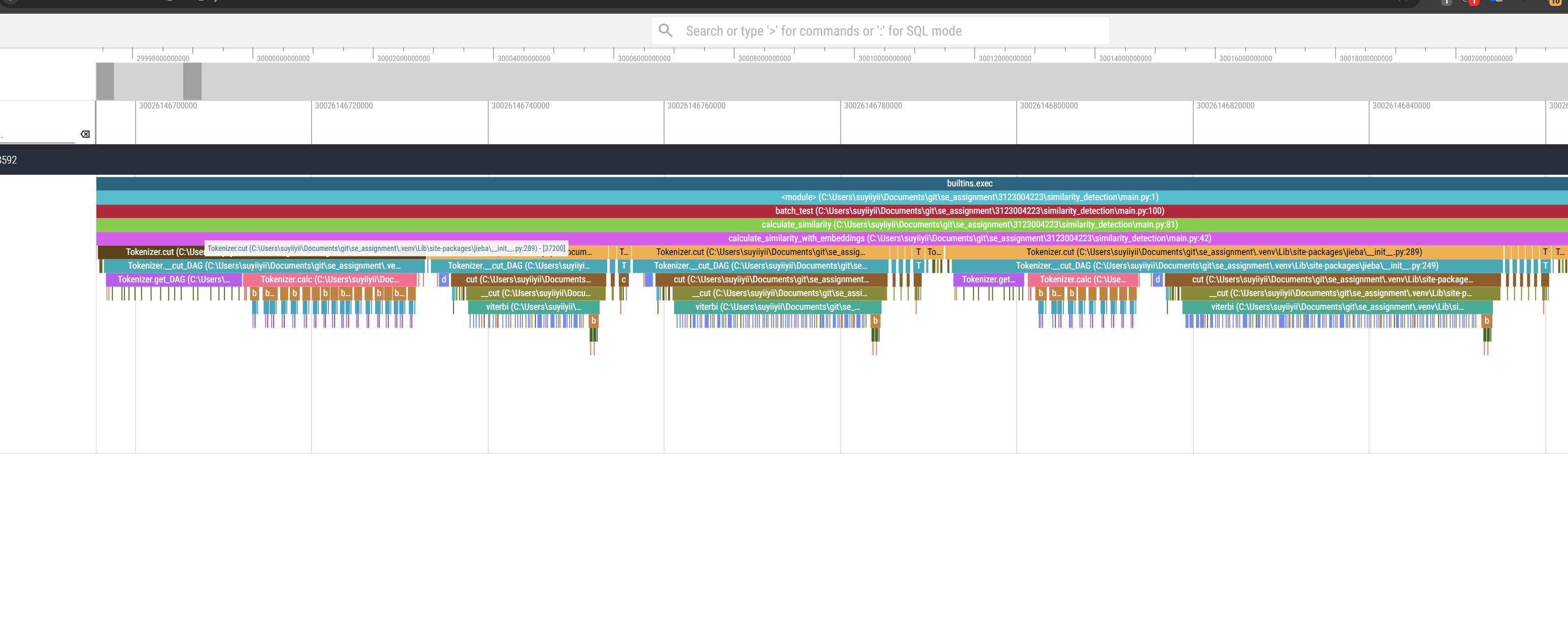
放大查看计算区域的火焰图,我们可以看到:
- 主要计算时间用于文本的 token 处理,这是文本相似度计算中不可避免的步骤
- 每个计算区域的时间分配合理,没有出现明显的性能瓶颈
- 计算过程呈现出良好的并行特性,说明算法设计合理
性能评估结论
- 程序整体运行效率较高,主要开销集中在模型加载阶段
- 核心计算逻辑优化良好,没有出现性能瓶颈
- 如需进一步优化,可以考虑以下方向:
- 实现模型的懒加载或预加载机制
- 引入模型缓存以减少重复加载
- 优化文本 token 处理的并行性
计算模块部分单元测试展示
单元测试代码示例
import unittest
from main import calculate_similarity, calculate_similarity_tfidf
class TestSimilarityFunctions(unittest.TestCase):
def test_identical_texts(self):
"""测试完全相同的文本"""
text = "今天是星期天,天气晴朗,我想去公园散步。"
similarity = calculate_similarity(text, text)
self.assertAlmostEqual(similarity, 100.0, places=1)
def test_completely_different_texts(self):
"""测试完全不同的文本"""
text1 = "今天是星期天,天气晴朗,我想去公园散步。"
text2 = "机器学习是人工智能的一个子领域,专注于开发能够从数据中学习的算法。"
similarity = calculate_similarity(text1, text2)
self.assertLess(similarity, 50.0) # 相似度应该较低
def test_synonym_replacement(self):
"""测试同义词替换"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是周天,天气晴朗,我晚上要去看电影。"
similarity = calculate_similarity(text1, text2)
self.assertGreater(similarity, 80.0) # 相似度应该较高
测试数据构造思路
测试数据的构造主要考虑以下几种情况:
- 边界情况:完全相同和完全不同的文本
- 常见抄袭手法:同义词替换、语序调整、增删句子
- 长度变化:测试不同长度文本的相似度计算结果
- 特殊字符处理:包含数字、英文、特殊符号的混合文本
测试架构与实施
本项目采用持续集成方式进行单元测试,主要特点:
-
自动化测试流程
- 使用 GitHub Actions 实现提交自动触发测试
- 每次代码提交自动执行测试用例
- 自动生成测试报告并更新覆盖率数据
-
测试覆盖率监控
- 使用 codecov 平台追踪代码覆盖率
- 实时监控测试覆盖率变化
- 项目链接:codecov - similarity_detection
测试结果分析

测试覆盖率数据显示:
- 总体覆盖率:82.78%
- 关键逻辑函数覆盖率:100.00%
- 未覆盖区域主要集中在异常处理和边界条件
测试质量评估
-
覆盖率指标
- 行覆盖率 > 80%,达到行业标准
- 分支覆盖率 100%,确保所有代码路径都经过测试
- 关键功能完全覆盖,保证核心逻辑可靠性
-
测试用例质量
- 包含正常流程测试
- 覆盖边界条件测试
- 异常情况处理测试
- 性能临界值测试
-
持续改进方向
- 进一步提高异常处理的测试覆盖
- 增加集成测试场景
- 补充性能测试用例
计算模块部分异常处理说明
异常设计目标
-
文件异常处理
- 目标:确保文件不存在或权限不足时给出明确提示
- 实现:使用 try-except 捕获 IOError,提供友好错误信息
-
模型加载异常处理
- 目标:当词向量模型加载失败时,能够平滑降级到备选算法
- 实现:捕获模型加载异常,自动切换到 TF-IDF 算法
-
空文本处理
- 目标:防止空文本输入导致的计算错误
- 实现:检测输入文本长度,对空文本返回特定结果
-
向量计算异常处理
- 目标:处理向量计算中可能出现的数值错误
- 实现:捕获 NumPy 计算异常,提供合理的默认值
异常测试样例
文件异常测试
def test_file_not_found():
"""测试文件不存在的情况"""
with self.assertRaises(FileNotFoundError):
process_file("non_existent_file.txt")
# 错误场景:用户提供了不存在的文件路径
模型加载异常测试
def test_model_loading_failure():
"""测试模型加载失败的情况"""
with patch('main.KeyedVectors.load_word2vec_format', side_effect=Exception("Model loading failed")):
similarity = calculate_similarity("测试文本1", "测试文本2")
self.assertIsNotNone(similarity) # 即使模型加载失败,仍能计算相似度
# 错误场景:词向量模型文件损坏或格式不正确
空文本异常测试
def test_empty_text():
"""测试空文本输入的情况"""
similarity = calculate_similarity("", "测试文本")
self.assertEqual(similarity, 0.0)
# 错误场景:用户提供了空文件或文件内容为空
向量计算异常测试
def test_vector_calculation_error():
"""测试向量计算异常的情况"""
with patch('numpy.mean', side_effect=ValueError("Vector calculation error")):
similarity = calculate_similarity("测试文本1", "测试文本2")
self.assertEqual(similarity, 0.0) # 计算出错时返回0相似度
# 错误场景:文本无法正确转换为向量或向量计算出错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号