网络插件
网络插件:
网络插件简称CNI,是独立的内容,当kubelet控制pod时,调用网络网络插件生成CNI接口,所以有kubelet就必须要有网络插件
网络插件运行支持两种方式,做systemd管理的进程运行,或者以pod方式运行
k8s中网络通信:
- 容器间通信: 同一个pod内的多个容器,用lo
- pod间通信: pod IP到pod IP
- pod与svc通信: podIP到clusterIP
- service与集群外部通信
- CNI接口:
flannel
calico
canel
- CNI接口:
网络解决方案:
- 虚拟网桥叠加,Overlay
- 多路复用,MacVLAN,一个以太网接口上虚拟多个网络接口,每个接口有mac地址
- 硬件交换,SR-IOV,物理网卡虚拟多个网卡
- 物理路由,用物理网卡,在路由器维护路由
- 网络直连,直接分配物理机同网段
通信方式:
flannel插件:
默认使用网段: 192.168.0.0/16
默认生成文件: /run/flannel/subnet.env #保存当前节点ip范围
组件:
- cni0:
网桥设备。每个pod都对应一个 - flannel.1:
overlay网络设备。对vxlan报文处理(封包解包)
不同node之间的pod数据都是从此设备以隧道形式发送到对端
工作模式:
udp: 已过时
vxlan:
默认使用
原始模式vxlan:
主机虚拟一个网卡,与其他主机通信时,基于此虚拟网卡与对方虚拟网卡建立隧道,实现链路层的数据帧传输
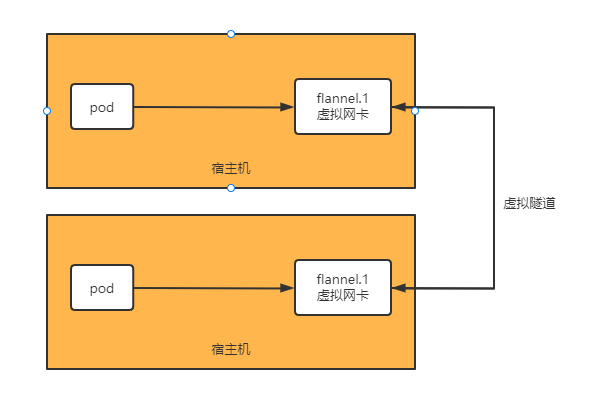
vtep(隧道端点),vtep是vxlan网络的边缘设备,是vxlan隧道的起点和终点,对用户原始数据帧的封装和解封装都在vtep上进行,vtep与物理网络相连,分配的地址为物理网ip地址,一个vtep对应一个vxlan隧道,服务器上的虚拟交换机(隧道flannel.1,就是vtep)。一个主机网络中有多个vxlan就要多个vtep对不同网络报文进行封装与解封装
数据包走向:
- pod-->flannel.1-->pod2
- pod-->宿主机路由器-->公网
使用场景:
- 可用于node不在同一网络
- 性能第三好
扩展Directrouting:
同一网段的通信使用host-gw,不是同一网段的使用Vxlan
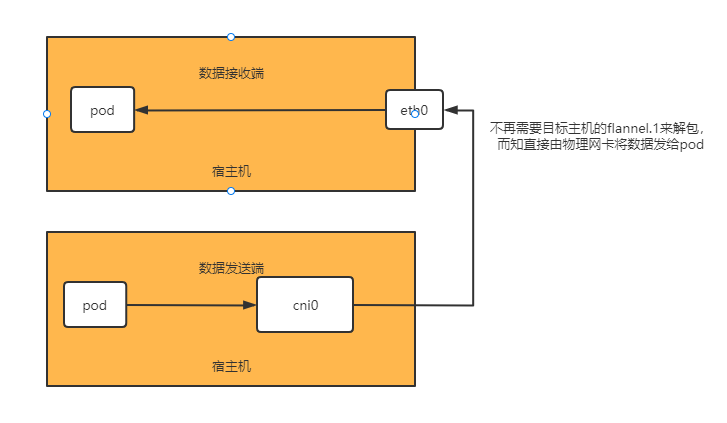
数据包走向:
- pod-->cni0-->节点2-eth0 -->pod
- pod-->cni0--eth0-->公网
使用场景:
- 可用于node不在同一网络
- 性能第二好
host-gw
虚拟一个网卡,为容器提供内部网络,当访问另外主机时,数据帧路由到虚拟网卡,非本地网段的继续路由交给物理网卡,物理网卡查询路由表后发给目标主机
目标主机交给虚拟网卡,再到达目标地址
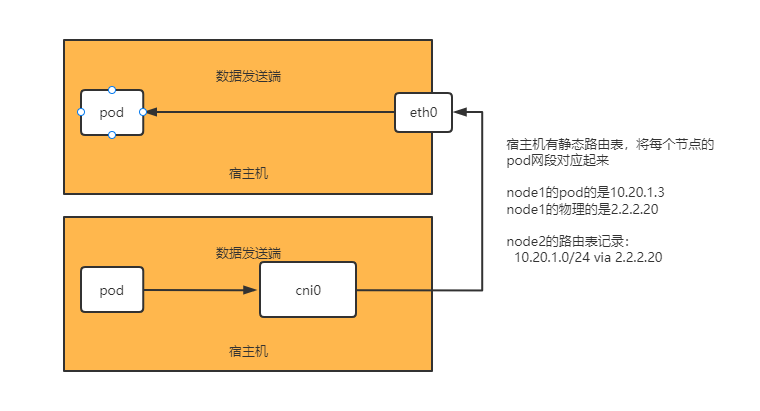
数据包走向:
- pod-->cni0--节点2-eth0-->pod
- pod-->cni0--eth0-->公网
使用场景:
- 只能用于node是同一网络
- 应用于较大内网环境,性能是最好的
配置参数:
注意: 只能是在安装k8s集群时配置,安装完成后修改就不能动态修改,必须删除插件重新安装才能生效,且所有pod不能在更换期间运行,或删除插件,重新安装插件后重启宿主机
NetWork: #flannel使用的CIDR格式的网络地址,用于配置pod网段
SubnetLen: #把NetWork网段切分为子网提供给node时,掩码是多少,默认24位
SubnetMin: #子网划分时,起始位置
SubnetMax: #子网划分时,结束位置
Backend: #pod之间通信使用的工作方式,vxlan、host-gw、udp
例1: 设置为混合vxlan(vxlan+gw)
vim kube-flannel.yml
#在130行
net-conf.json: |
net-conf.json: |
{
"Network": "10.20.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true
}
}
设置为host-gw:
vim kube-flannel.yml
#在130行
net-conf.json: |
{
"Network": "10.20.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
安装:
以配置清单运行pod:
wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
#按需配置网络模式后,部署
vim kube-flannel.yml
kubectl apply -f kube-flannel.yml
以kubeasz部署:
#修改网络插件
vim /etc/kubeasz/clusters/k8s-01/hosts
CLUSTER_NETWORK="flannel"
#可选,自定义svc和pod使用网段
SERVICE_CIDR="10.10.0.0/16"
CLUSTER_CIDR="10.20.0.0/16"
#指定flannel配置
vim /etc/kubeasz/clusters/k8s-01/config.yml
FLANNEL_BACKEND: "vxlan"
DIRECT_ROUTING: true
calico插件:
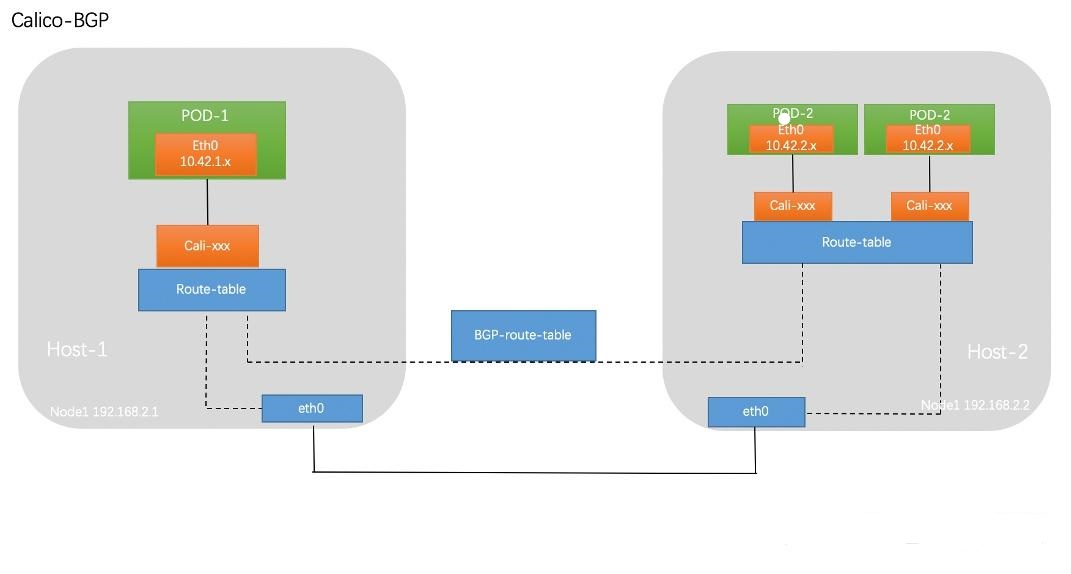
纯3层的网络解决方案,将每个节点当成一个路由器,各节点通过BGP边界网关协议,学习后动态生成路由规则(每个node都有到出自己以外的所有节点的路由)
可用于网络控制策略,calico是目前支持该功能的插件之一
公有云使用calico的ip-ip、bgp时,必须支持BGP协议,否则不能生成路由表
默认使用网段: 192.168.0.0/16
BGP协议:
- 自动学习、维护路由表
- 直接使用物理机作为虚拟路由器,不用创建tunnel(虚拟隧道)
组件:
- felix:calico客户端,所有节点运行。 负责接口管理、路由规则、ACL 规则、状态报告
- BGP客户端: 监听fellix生成的路由信息,将Felix的路由信息读入内核,并通过BGP协议在集群中广播分发(与所有节点建立连接)。在Calico语境中,此组件是通用的BIRD,因此任何BGP客户端(如GoBGP等)都可以从内核中提取路由并对其分发对于它们来说都适合的角色
- Route Reflector(RR): 路由反射器,BGP客户端将路由从FIB(转发信息库)通告到RR时,RR将路由通告给集群其他节点,所有的BGP客户端与路由反射器做同步,只用连接rr节点就可以获取集群所有路由,不用再与每个节点建立连接。RR只用于管理BGP网络路由规则,不产生pod数据通信
- Calicoctl: calico命令行管理工具

网络模式:
BGP模式:
直接用物理机作为虚拟路由,不再额外创建tunnel隧道
使用bgp协议,可以在部署calico时配置开启或关闭
数据包走向:
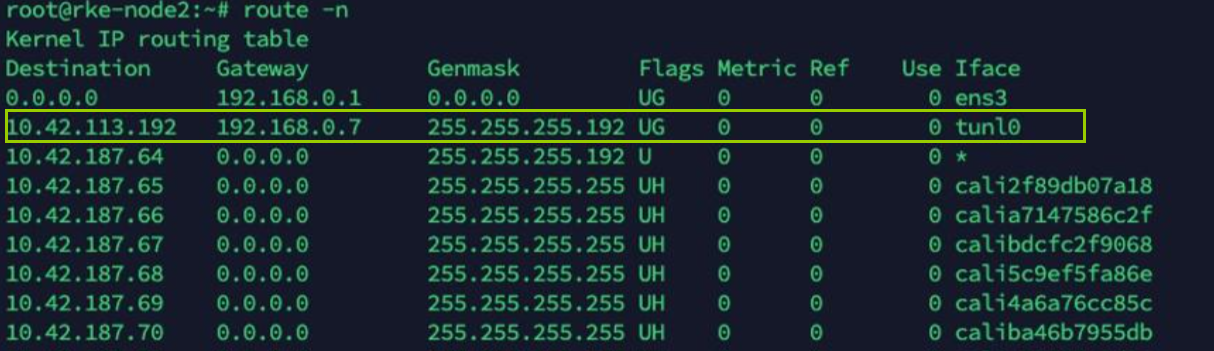
无tunl0网卡,直接使用物理网卡
与 Flannel 的 host-gw类似,基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息
pod veth设备 --> cali虚拟网卡 -->本地eth0(路由表) --> 目标eth0 --> ... --> pod
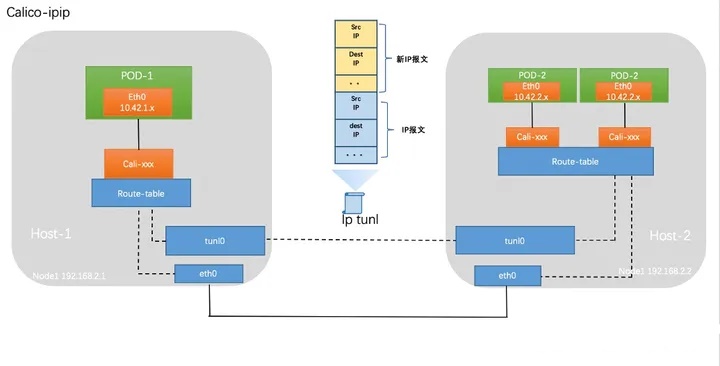
IPIP模式:
默认模式,类似flannel的vxlan
相比较VxLAN的二层隧道来说,IPIP隧道的开销较小,但其安全性也更差一些
linux内核的驱动程序,可以对数据包进行隧道
作用:
-
IPIP可以实现不同网段建立路由通信,
-
将各node的路由之间做一个tunnel隧道,把两个网络连接起来,并在node节点创建tunl0的虚拟网卡进行封装、解包
数据包走向:
有tunl0网卡,类似flannel的vxlan,需要tunl0做数据封包解包
在原有 IP 报文中封装一个新的 IP 报文,新的 IP 报文中将源地址 IP 和目的地址 IP 都修改为对端宿主机 IP
pod --> 本地tunl0 --> 本地eth0 --> 目标eth0 --> 目标tunl0 --> pod
cross-subnet模式:
对于一些主机跨子网而又无法使用 BGP 的场景可以使用 cross-subnet 模式,实现同子网机器使用 calico-BGP 模式,跨子网机器使用 calico-ipip 模式
BGP路由模式
全互联模式(node-to-node mesh):
Calico的CNI插件会为每个容器设置一个veth pair设备,然后把另一端接入到宿主机网络空间,由于没有网桥,CNI插件还需要在宿主机上为每个容器的veth pair设备配置一条路由规则,用于接收传入的IP包
有了这样的veth pair设备以后,容器发出的IP包就会通过veth pair设备到达宿主机,这些路由规则都是Felix维护配置的,而路由信息则是calico bird组件基于BGP分发而来。Calico实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过BGP交换路由,这些节点我们叫做BGP Peer
每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,BGP连接总数就是N^2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式(默认使用)
路由反射模式Router Reflection(RR):
使用路由反射器来集中管理路由规则
指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式
配置参数:
calico_backend: "bird" #,可选bird、gobgp、vxlan、none。默认即”bird”即开启, “gobgp”无ipip模式
CALICO_IPV4POOL_IPIP #ipip开关
CALICO_IPV4POOL_CIDR #pod网段
DATASTORE_TYPE #数据存储方式
安装:
以配置清单创建pod运行:
wget --no-check-certificate https://docs.projectcalico.org/v3.14/manifests/calico.yaml
#或者
wget --no-check-certificate https://docs.projectcalico.org/manifests/calico.yaml
#部署前修改
vim calico.yaml
...
containers:
- ...
env:
- name: CALICO_IPV4POOL_CIDR #配置pod使用网段
4801 value: "10.20.0.0/16"
- name: CALICO_IPV4POOL_IPIP
value: "Always"
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
#部署后修改cm资源
kubectl get cm -n kube-system calico-config
以kubeasz部署:
#修改网络插件
vim /etc/kubeasz/clusters/k8s-01/hosts
CLUSTER_NETWORK="calico"
#可选,自定义svc和pod使用网段
SERVICE_CIDR="10.10.0.0/16"
CLUSTER_CIDR="10.20.0.0/16"
#指定calico配置
vim /etc/kubeasz/clusters/k8s-01/config.yml
CALICO_IPV4POOL_IPIP: "Always"
CALICO_NETWORKING_BACKEND: "brid"
网络访问控制
单独写
canal插件:
基于calico,并结合了flannel,具有calico相同的网络访问控制功能
一般用于辅助flanne,flannel不能提供网络访问控制,所有pod都可以跨namespace访问,canal能够对控制网络访问
安装:
curl https://docs.projectcalico.org/manifests/canal.yaml -O
kubectl apply -f canal.yml
网络访问控制:
参考calico

 浙公网安备 33010602011771号
浙公网安备 33010602011771号