

redis主从复制
主从复制
redis没有具体实现读写分离的软件,所以具体的读写分离功能需要开发自己写功能,我们只需要搭建主从节点即可
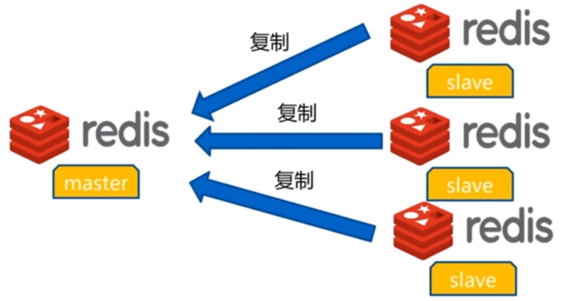
特点:
- 一个master可以有多个slave
- 一个slave只能对应一个master
- 数据流向是单方向的:master-->slave
- master可读写数据,slave只能读取数据
主从复制过程:
分全量复制和增量复制
原理:
全量和增量的原理:
- redis的主从同步是非阻塞的,master收到从服务器的sync(2.8版本之前是PSYNC)命令会fork一个子进程在后台执行bgsave命令,并将新写入的数据写入到一个缓冲区里面
- 子进程执行完bgsave之后将生成的RDB文件发送给slave,slave将收到后的RDB文件载入自己的内存,然后master再将缓冲区的内容在全部发送给slave
- 之后的同步slave会发送一个offset的位置(等同于MySQL的binlog的位置)给master,主检查后位置没有错误将此位置之后的数据包括写在缓冲区的积压数据发送给slave,slave将master发送的积压数据写入内存,这样一次完整的数据同步
- 以后再同步的时候slave只要发送当前的offset位置给master,然后master根据相应的位置将之后的数据发送给slave保存到其内存即可
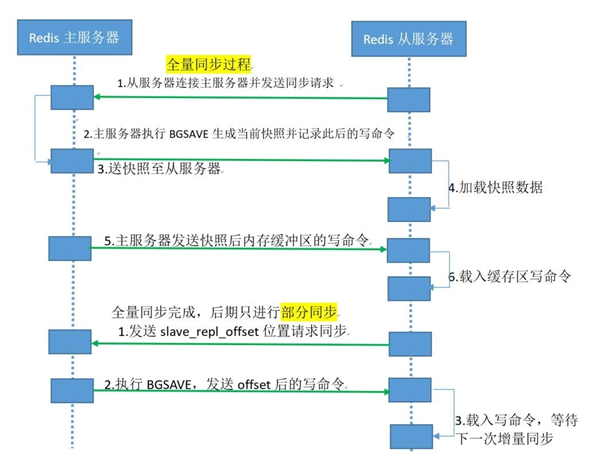
简略版就是:
- 从服务器连接主服务器,发送PSYNC命令
- 主服务器接收到PSYNC命令后,开始执行BGSAVE命令生成RDB快照文件并使用缓冲区记录此后执行的所有
写命令 - 主服务器BGSAVE执行完后,向所有从服务器发送RDB快照文件,并在发送期间继续记录被执行的写命令
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照至内存
- 主服务器快照发送完毕后,开始向从服务器发送缓冲区中的写命令
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令
- 后期同步会先发送自己slave_repl_offset位置,只同步新增加的数据,不再全量同步
注意点:
- 一旦做了从节点,所有的数据都会丢失,slave在同步rdb到内存的时候,会把所有的库都删除
- 当配置Redis复制功能时,强烈建议打开主服务器的持久化功能。否则的话,由于延迟等问题,部署的服务应该要避免自动启动
- 在关闭主服务器上的持久化,同时开启自动启动时下,即便使用Sentinel来实现Redis的高可用性,也是非常危险的。因为主服务器可能拉起得非常快,以至于Sentinel在配置的心跳时间间隔内没有检测到主服务器已被重启,然后还是会执行上面的数据丢失的流程。无论何时,数据安全都是极其重要的,所以应该禁止主服务器自动启动
考虑点:
- 主从同步时,新写入的数据,可能太多,而缓存区空间又太小,新写入的数据会覆盖旧的数据,等到rdb备份完成后再同步缓冲区时,slave的数据会丢失被覆盖的内容
案例: 导致主从服务器数据全部丢失
- 假设节点A为主服务器,并且关闭了持久化。并且节点B和节点c从节点A复制数据
- 节点A崩溃,然后由自动拉起服务重启了节点A.由于节点A的持久化被关闭了,所以重启之后没有任何数据
- 节点B和节点c将从节点A复制数据,但是A的数据是空的,于是就把自身保存的数据副本删除
主从同步命令:
replicaof 主节点ip 端口 绑定master节点
config set masterauth 密码 输入master节点的密码
主从同步配置:
2.8版本之前没有提供增量部分复制的功能,当网络闪断或者slave重启之后会导致主从之间的全量同步,即从2.8版本开始增加了部分复制的功能
repl-diskless-sync no rdb传输方式,yes为网络模式,数据直接用网络连接传;no为文件传输,在磁盘生成rdb文件在传
repl-diskless-sync-delay 5 网络传输时的网络等待时间
repl-ping-slave-period 10 slave向master的ping间隔时间(健康检测)
repl-timeout 60 传输超时时间
repl-disable-tcp-nodelay no 数据积攒模式,小数据攒着,等量够大了一次传输yes开启,no关闭
repl-backlog-size 512mb 缓冲区大小,计算公式:
repl-backlog-size=允许从节点最大中断时长*主每秒数据写入大小
64mb/s * 60/s断开连接 = 3840MB
repl-backlog-ttl 3600 没有slave连接master,缓冲区多久清空,0为不清空,秒单位
slave-priority 100 slave上任master的优先级,值越小越大
min-slaves-to-write 1 最少slave数,少于此数master无法写入数据
min-slaves-max-lag 20 主从复制的数据时间差,slave少于master20秒的数据,mastert无法写入数据
主从复制优化思路:
- 第一次全量复制不可避免,后续的全量复制可以利用内存小的节点、业务地缝期进行全量
- 节点run_id不匹配,由于redis每次启动时随机生成,master重启生成新的run_id,可能会触发全量复制,可利用故障转移: 哨兵、集群
- 复制时积压缓冲区不足: repl-backlog-size 调大。slave掉线时,master缓存区小了会不断覆盖原记录,slave再次连接时会全量复制,只有缓存区保证没有数据被覆盖过,才会增量复制
主从复制排错:
- 主从的配置要是一样的,比如别名、maxmemory(主的16G,从8G,导致从的数据丢失,因为只能存一半)
- 配置的master密码不对,导致验证不通过而无法建立主从同步
- 不同的redis版本之间存在兼容性问题,因此各master和slave之间必须保持版本一致
避免复制风暴:
单节点复制风暴:
主节点重启,从节点全部全量复制
解决方法:
更换复制结构
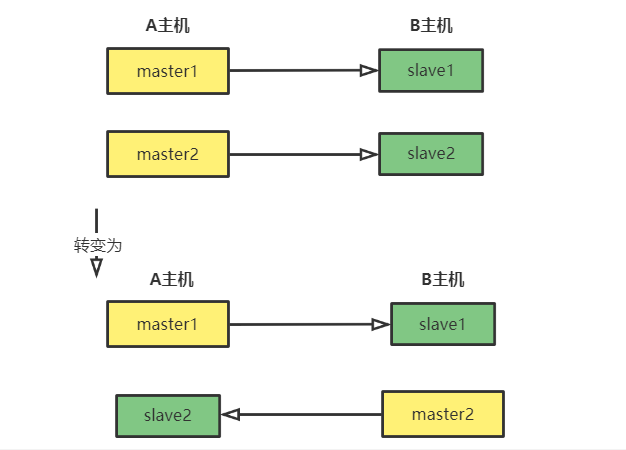
单主机复制风暴:
主节点重启,多个master实例全部重启
解决方法:
主节点分散出去
主从复制案例
主从复制配置:
1)只用在slave节点配置
redis-cli replicaof 2.2.2.12 6379
#如果master有密码,则:
redis-cli config set masterauth 密码
vim /etc/redis.conf
replicaof 2.2.2.12 6379
#masterauth 123456 master没有密码则不需要
replica-priority 100 #根据需要设优先级
systemctl restart redis
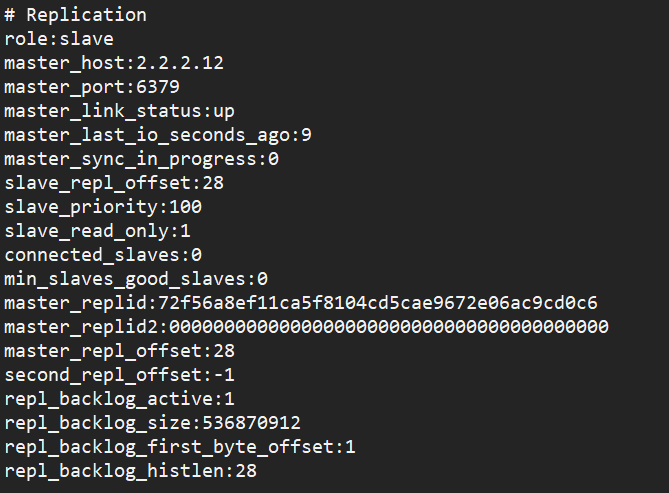
redis-cli info
role:slave
master_host:2.2.2.12
master_port:6379
master_link_status:up 重启服务后此项必须是up
master_last_io_seconds_ago:9 连接超时时间,60会down
master_sync_in_progress:0 同步状态,0为完成
master_replid 当前master的复制id
级联主从复制配置:
| 2.2.2.12 | master |
| 2.2.2.22 | slave1 |
| 2.2.2.32 | slave2 |
1)在slave1上配置
#指向2.2.2.12
vim /etc/redis.conf
bind *
replicaof 2.2.2.12 6379
systemctl restart redis
2)在slave2上配置
#指向2.2.2.22
vim /etc/redis.conf
replicaof 2.2.2.22 6379
systemctl restart redis
slave上任master:
1)在slave1上配置
#清空slave的所有信息即可
replicaof no one

 浙公网安备 33010602011771号
浙公网安备 33010602011771号