
Fork/Join 框架-设计与实现(翻译自论文《A Java Fork/Join Framework》原作者 Doug Lea)
作者简介
Dong Lea任职于纽约州立大学奥斯威戈分校(State University of New York at Oswego),他发布了第一个广泛使用的java collections框架实现,他实现了java.concurrent.*(JDK5开始至今)。
论文译文开始:
论文摘要
本论文介绍一种支持并行编程方式的Java框架,主要包括设计、实现和性能分析三个部分。基于它,一个任务被(递归的)划分为并行执行的子任务,父任务等待子任务的执行完成,并组装最后结果。总体设计是Cilk语言采用的work-stealing框架的一个变体,主要技术性能关注点包括:构建和管理任务队列、工作线程。测试结果显示,对于大部分问题它有很大的并行速度提升,测试也预示了可能的性能改进。
1、介绍
Fork/Join并行是获得良好的并行性能的最简单高效的设计技术。他是分治(Divide-and-Conquer)算法的的并行实现,它的典型应用形式:
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
fork操作启动一个新的并行fork/join子任务,join操作则导致当前线程等待直到子任务执行完成。fork/join算法,就像其它分治算法一样,几乎经常是不断的递归,重复划分子任务——直到它们的规模小到能够使用简单、简短的串行方法完成。一些相关的编程技术和实例在《Java并发编程——设计原则与模式》第二版(Concurrent Programming in Java, second edition ) [7] 4.4章节中已经讨论过。本篇论文将讨论FJTask的设计(第2节)、实现(第3节)以及性能(第4节),它是一个支持并行编程的Java框架。FJTask 作为util.concurrent软件包的一部分,目前可以在http://gee.cs.oswego.edu.获取到。
2、设计
Fork/Join 程序可以在任何支持并行创建、执行子任务的框架上运行——只要它有一种等待子任务完成的同步机制。然而,java.lang.Thread类(当然也包括POSIX线程——它们常常是Java线程的基础)因为以下原因,它仅仅是支持fork/join编程的次优选择:
(1)fork/join任务只有简单和常规的同步和管理需求。fork/join任务处理的计算图显示,相对于普通线程它容许更加高效的调度策略。举个例子,fork/join任务除了在等待子任务返回结果时,其它情况下不需要同步。因此,普通线程所需要的状态记录和开销在这里是一种浪费。
(2)对于一个合理的基本任务粒度,构造和管理线程的时间将超越任务的计算时间本身。尽管粒度可以也应该随着特定平台调整,但极端的粗粒度加重了线程的开销,从而限制了获得高并行性的可能。
一句话,标准线程框架对于大部分fork/join程序来说是一种资源浪费。由于线程是许多其它并发和并行编程的基础,为了能够支持这种(fork/join)风格的程序,移除现有线程的“冗余”或者调整它的调度策略都是不合理的。尽管如此——问题的解决方案由来已久:第一个系统的解决方法来自于Cilk语言。Cilk和其它的轻量级框架在操作系统的基本线程之上,构建了一个支持fork/join程序的支撑层。提供一个支持Java的轻量级运行框架的意义在于:让fork/join程序具有更好的移植性,从而允许它在支持JVM的广泛平台上运行。
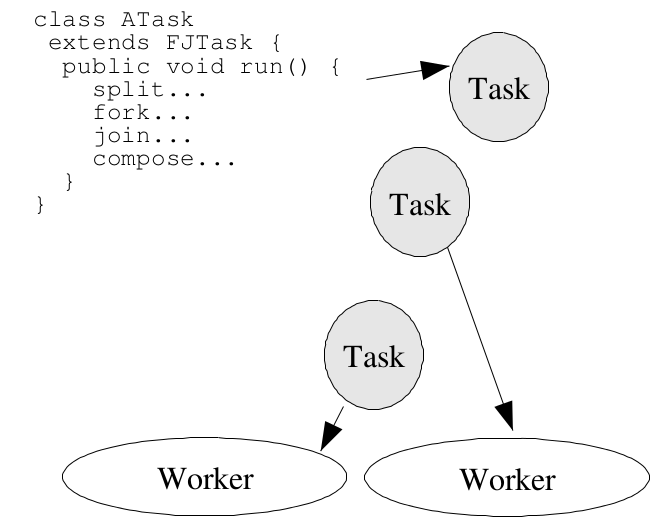
图一 FJTask的基本处理流程
FJTask框架是基于Cilk设计方案的一个变体,其它的变体出现在Hood, Filaments, stackthreads以及其它相关的基于轻量级的任务中。所有的这些框架将任务映射到线程的机制类似于操作系统将任务分配到处理器上的方式——同时,它们也兼顾了处理映射时fork/join程序的简洁性、常规性、局限性,它们都能容纳(延伸)不同风格的并行编程。fork/join设计的优化包括:
(1)创建了一个worker线程的线程池。每个工作线程(“重”线程,Java中是Thread的子类FJTaskRunner)处理队列中的任务,通常工作线程数和CPU核心一样多。在本地化的框架中(如Cilk),它们被映射为内核线程或者轻量级线程,依次提交给CPU。在Java中,JVM和操作系统相互协作将程序提交到CPU。因为这些任务是计算密集型的,任何合理的映射策略会将这些线程映射到不同CPU核心。
(2)所有的fork/join任务都是轻量级可执行类,它们不是Threads实例。在Java中,独立可执行类必须实现Runnable接口、重写run方法。FJTask框架中,所有这些任务都是FJTask的子类(不是Thread),它们都实现了Runnable。(两种情况:一个类可以选择实现Runnable并且将实例运行于任务或者线程,因为任务运行于FJTask方法的严格限制中,因此扩展FJTask子类更方便直接调用)
(3)一个特殊用途的队列和调度机制用来管理任务,并且通过Worker线程来执行它们(具体见章节2.1)。这些机制被任务类的少量方法触发:fork, join, isDone(是否完成状态指示器),以及一些便捷的方法,比如coInvoke创建并join两个或多个任务。
(4)一个简单的控制和管理基础设施(FJTaskRunnerGroup)设置worker线程池,并且初始化执行给定的fork/join任务,当它被一个常规线程调用时(比如某个Java程序的main方法)
作为让程序员了解这个框架的标准示例,这里有一个计算斐波拉契函数的类(注意:在Java 8 中,对应的是ForkJoinTask类):
package java.util;
class Fib extends FJTask {
static final int threshold = 13;
volatile int number; // arg/result
Fib(int n) {
number = n;
}
int getAnswer() {
if (!isDone())
throw new IllegalStateException();
return number;
}
public void run() {
int n = number;
if (n <= threshold) //
number = seqFib(n);
else {
Fib f1 = new Fib(n −
Fib f2 = new Fib(n −
coInvoke(f1, f2);
number = f1.number +
}
}
public static void main(String[] args) {
try {
int groupSize = 2; // for example
FJTaskRunnerGroup group = new FJTaskRunnerGroup(groupSize);
Fib f = new Fib(35); // for example
group.invoke(f);
int result = f.getAnswer();
System.out.println("Answer: " + result);
} catch (InterruptedException ex) {
}
}
int seqFib(int n) {
if (n <= 1) return n;
else return seqFib(n−1) + seqFib(n−2);
}
}
这个版本比基于java.lang.Thread(每个子任务新建一个线程)的快30倍(第四节中的平台)。达到这样性能的同时,它还保持了Java多线程程序内在的可移植性。程序员通常只对两个可调的参数感兴趣:
(1)构造的工作线程数目——通常应当与对应平台CPU的核心数一致(为了给相关的工作保留CPU,可以少些;为了填补非计算型任务的CPU闲置,可以多些)。
(2)粒度参数——表示某一时刻,产生任务的开销与可能的并行计算效益的比例。这个参数常常与算法相关——而不是平台。通常在单CPU上设定一个阈值能够产生好的结果,移植到多CPU平台也能很好表示。作为一个附带的好处,这个机制与JVM的动态编译机制(相较于复杂方法,它更能优化短小的方法)很好的协调。以上特性以及数据的局部性特点,使得fork/join算法即便在单处理器上也能获得超越其它算法的性能。
2.1 工作窃取
fork/join框架的核心来自于它的轻量级调度机制。FJTask借鉴在Cilk中采用的工作窃取调度策略:
(1)每个worker线程利用它自己的调度队列维护可执行任务。
(2)队列是双端的,支持LIFO(last-in-first-out)的push和pop操作,通知也支持FIFO(first-in-first-out)的take操作。
(3)一个任务fork的子任务,只会push到它所在线程的队列。
(4)工作线程使用LIFO通过pop处理它自己队列中的线程。
(5)当线程自己本地队列中没有待处理任务时,它尝试去随机读取(窃取)一个worker线程的工作队列任务(使用FIFO)。
(6)当线程进入join操作,它开始处理其它线程的任务(自己的已经处理完了),直到目标任务完成(通过isDone方法)。因此,所有任务都无阻塞的完成了。
(7)当一个工作线程没有任务了,并且尝试从其它线程处窃取也失败了,它让出资源(通过使用yields, sleeps或者其它优先级调整)并且随后会再次激活,直到所有工作线程都空闲了——此时,它们都阻塞在等待另一个顶层线程的调用。
如同在第5节中详细讨论的,使用LIFO策略处理线程自己的任务,窃取其它工作线程任务时却使用FIFO策略——这是广泛使用的一类递归fork/join设计的优化机制。不太正式的总结下,这种模式有以下两个优点:它通过窃取工作线程队列反方向的任务减少了竞争。同时,它利用了递归的分治算法越早的产生大任务这一特点。因此,老的窃取线程会拿到更大的任务,这致使问题进一步的递归分解(窃取线程的子任务将进入它自己的本地队列)。这些规则的结果,拥有相对细粒度的基本任务,比那些仅仅使用粗粒度划分或没有使用递归分解的任务运行更快。虽然,对大部分fork/join框架来说,很少一部分任务被窃取,创建许多细粒度任务意味着当worker线程准备好事就能运行它们。
3. 实现
这个框架使用800行纯Java代码实现,主要在类FJTaskRunner中(它是java.lang.Thread的子类)。FJTasks主要持有一个布尔型的完成状态变量,它将所有其它操作交给当前的工作线程。FJTaskRunnerGroup类用来产生工作线程,维持一些共享状态(所有线程的身份,需要进行窃取操作等),帮助协调启动和关闭状态。
更详细的实现文档在util.concurrent包中,本节主要讨论实现这个框架面临的两种问题:支持高效的双端队列操作(push, pop, take),管理窃取协议(接下来哪个线程将获得一个新任务)。
3.1 双端队列
为保持高效和可伸缩的执行,任务管理必须越快越好。创建,push和随后的pop(或者是频率较低的take)任务类似于串行程序中的过程调用开销。小开销容许程序员保持线程的细粒度,从而获得更好的并行度。任务分配本身是JVM的职责,Java垃圾收集机制让我们不需要创建特殊用途的内存分配器来维持任务执行。这大大减少了实现FJTasks的代码量和复杂度——相比与其它语言实现的类似框架。
双端队列的结构利用了一种通用的模式,即每个队列都使用了一个大小可调数组,以及两个索引:top索引的职责如同一个基于数组的栈指针,它随着push和top操作而改变;base索引只能通过take操作修改。由于FJTaskRunner的操作都与双端队列的具体细节(比如,fork简单的调用push)紧密相关,这个数据结构直接嵌入到FJTaskRunner而不是单独定义一个组件。
因为双端队列的元素实际被多个线程访问,有时没有充分同步,并且单独的数组元素不能被声明为volatile,每个数组元素实际上是保持volatile引用的小转发对象的固定索引。这个决定一开始是为了与Java内存规则一致,但它引入的间接性在测试平台上恰恰提高了程序性能,原因可能是它减少了访问缓存相邻元素的竞争,间接性会使得元素在内存中更加分散。
实现双端队列的主要挑战来自于同步和减少竞争。即使时在同步设施优化的JVM中[2],每一个push和pop操作都需要获取锁成为一个性能瓶颈。然而,Cilk[5]中的改变策略基于以下观察提供了一种解决方案:
(1)push和pop操作仅仅被队列拥有者线程调用。
(2)访问take操作可以简单的每次局限于一个窃取线程(通过设置take进入锁——它也是必要时禁止take操作的锁)。由此,冲突控制转变为两部同步问题。
(3)pop和take操作只有在双端队列将要变为空时冲突,其它情况,它们被确保在不同的数组元素上操作。
将top和base索引定义位volatile确保pop和take操作在双端队列中大于一个元素时,不需要锁定。这是通过一种Dekker风格的算法,push操作会先递减top:
if(--top) >= base) ...
take操作会先递增base:
if(++base < top) ...
在每种情况下,它们必须比较这两个索引来检查是否会导致双端队列为空。一个非对称的规则被用来检查潜在的冲突:pop再次检查状态,并且在获得双端队列锁(与take持有的是同一个)时再继续,当双端队列确实为空时回退。take操作不同,它仅仅只是迅速回退,典型的,它接下来会试图窃取另外一个线程的任务。这种非对称表示是Java与Cilk语言THE协议实现的重要不同。
使用volatile型的索引使得push操作只有在双端队列数组要溢出时需要同步,此时,它必须首先要获取双端队列锁来重设数组大小。其他情况,需确保在数组元素填充时不受任何take操作影响,并且top被更新。
继初始实现之后,作者发现有些JVM实现没有遵守Java内存模型[6],即需确保volatile在写之后能够读取实时值。
作为一种变通方案,要求pop获得锁后,如果只有不多于两个元素时再次尝试,同时take操作增加另一个锁来保证内存边界。这保证了至多一个索引的改变会被队列拥有者略过(这样,对特定平台也保证了volatile域读取的及时性),并且只是导致微略的性能损失。
3.2 窃取与空闲
工作窃取框架中的worker线程并不知道它们执行程序的同步要求。它们只是简单的产生、push、pop、take、管理状态、执行任务。这些模式的简单性,确保即使所有线程有很多的任务也能高效的执行。然而,这种流线型化的任务在没有足够的任务时的代价依赖于启发:在启动一个主任务时,在它完成时,还有在全部停止点时,引入某些fork/join算法。
这里的主要问题是,当一个工作线程没有足够的任务并且又不能从其它线程窃取一个时,它该怎么办。当这个程序运行在一个专门化的多核平台时,它可以通过依赖于硬件平台的busy-wait自旋循环来窃取一个。然而,即使是这种情况,尝试去窃取一个也增加了冲突,这会导致即便是非空闲线程的执行效率(由于第3.1节描述的锁协议)。另外,在这种框架应用的更加典型场景,操作系统会被建议去运行其它不相关任务或线程。
在Java中,确保能够达到这样的工具是一种弱要求,但是它在实际工作中情况还是可以接受的(类似的技术说明见Hood[3])。一个线程不能从其它线程处窃取任务时,在再次窃取之前会降低它自己的优先级、调用Thread.yield、将它自己在FJTaskRunnerGroup组注册为不活跃(inactive)。当所有的worker线程变得不活跃时,它们会阻塞等待主线程的同步。其它情况,经过给定轮次的自旋,它们会进行睡眠,在再次窃取前,它们会睡眠最多100ms而不是调用yeild方法。这些引入的睡眠会导致那些需要较长的时间来划分子任务的线程产生人工时延,然而这是最好的通用目的折中。将来版本的框架可能增加附加的控制方法,允许程序员覆盖默认方法来提高性能。
4. 性能
随着时间推移,编译器和JVM不断被优化,这里的性能测度数据仅适用于当前。然而,这一节讨论的测量情况揭示了这一框架的基本属性。
下面表格是七种fork/join测试程序及其简介的集合。这些程序均修改自util.concurrent包中的示例程序。它们被选取来展示这个框架中能够运行程序的多样性,同时也为一些通用的并行测试程序提供测试数据。
| 程序 | 介绍 |
| Fib | 斐波拉契数列,第二节中展示的斐波拉契程序,运行参数47,粒度阈值13 |
| Integrate | 高斯正交卷积, (2*i-1)*x(2*i-1)求和,i为1到5的奇数,积分限-47到48 |
| Micro | 一种棋盘最佳移动方式查询游戏,查询后续四步的最佳移动 |
| Sort | 快速/归并排序,(基于Cilk中的一种排序方法),100 000 000个数字 |
| MM | 矩阵相乘,2048*2048的double型矩阵 |
| LU | LU矩阵分解,4096*4096的double型矩阵 |
| Jacobi | 雅可比迭代,4096*4096的double型矩阵,使用网状调和、最近邻域平均,迭代上限100 |
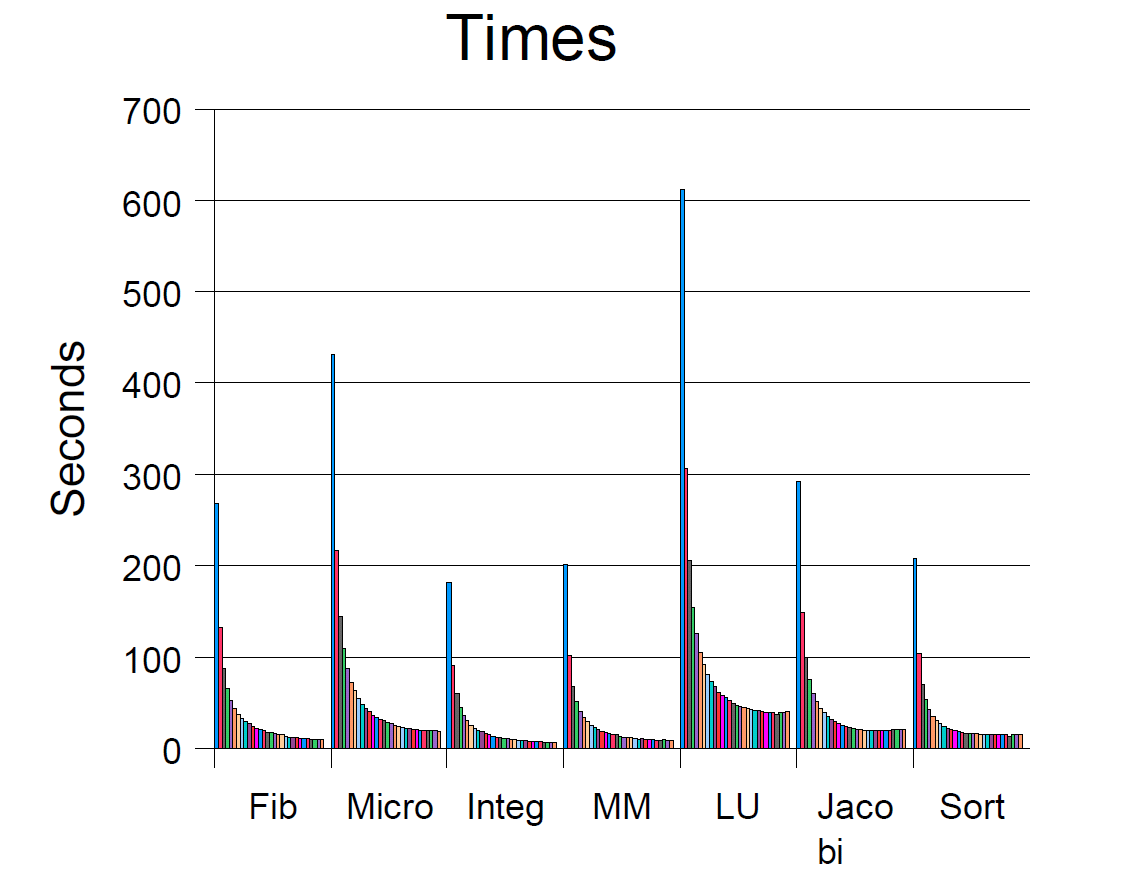
主要的测试,在一台30个CPU的Sun企业版10000路机器,运行着Solaris 7的1.2版本JVM(1.2.2_05版的一个早期版本)。JVM被配置环境变量对每一个线程映射“绑定线程”以及在4.2节中讨论的内存参数。一些附加的测量报告在4-CPUSun企业版450机器上完成。
为了最小化计时器和JVM启动的影响,测试程序运行时的输入参数很大。其它的一些预加载现象通过在计时器开始前运行一个初始问题集进行避免。大部分数据取了三次运行的中间数,但是有些(接下来4.2~4.4节的大部分测试数据)仅仅取了单次运行数据,因此会有些噪音。
4.1 加速比
可伸缩性测量通过将同一个问题在工作线程数1 ... 30的池中获得。没办法获得是否JVM每次都将线程映射到了不同的CPU核心,同样我们也没办法证明这一点。也许将新线程映射到不同的CPU随着线程的增加延迟增加,或者随着平台的不同在不同的的测试程序中不一样。然而,常规的,我们的测试结果显示,增加线程数可靠的增加了CPU的忙碌程度。
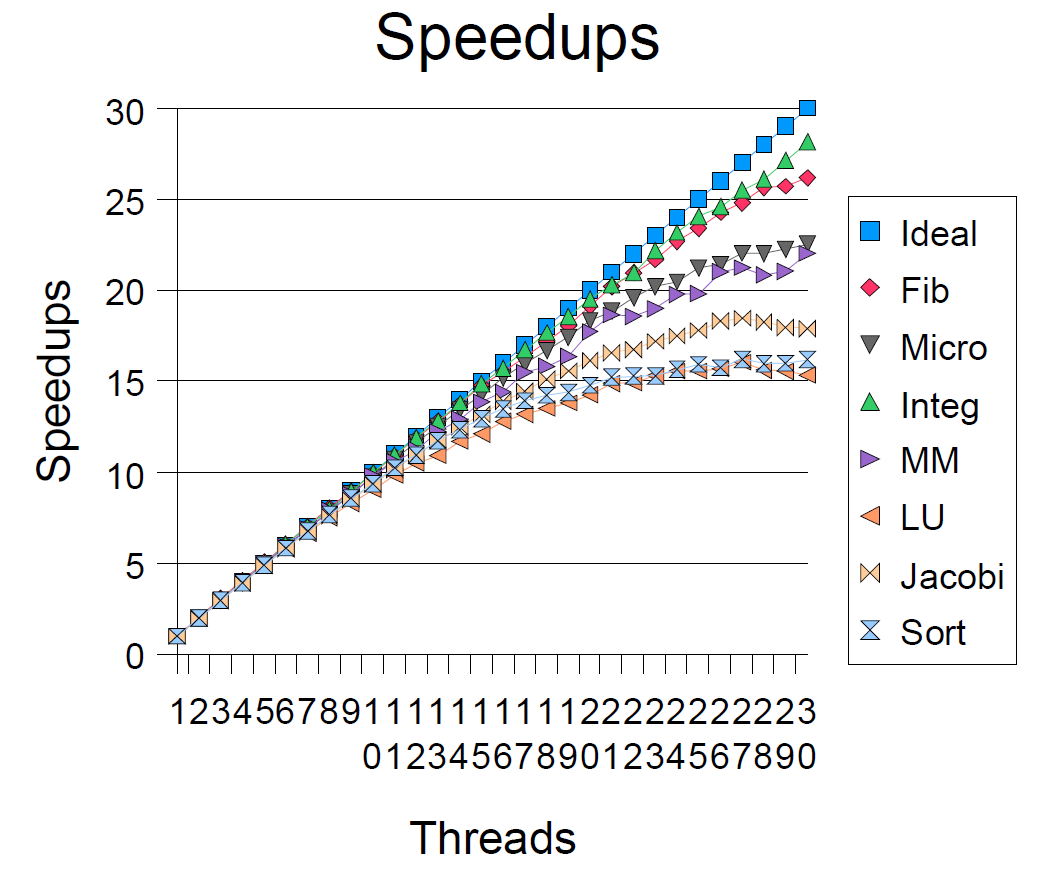
加速比通过Timen/Time1表示。所有程序中,加速比效果最好的是积分程序(30个线程时是28.2),最差的是LU分解程序(30个线程时是15.35)。
另一种测量可伸缩性指标的依据是任务率,即每个单一任务执行所需要的平均时间(可能是递归节点或叶节点)。下面的图表是采集自同一仪表监测的任务率。明显的,每单元每线程处理的任务应该是恒定的。事实上,随着线程数增加,它们略微的降低预示着可伸缩度的限制。需要指出,线程率的广泛差异与各自任务的粒度有关。最小的任务是斐波拉契数列计算,即使阈值设置为13,在30个线程时每秒可以执行280万个任务。
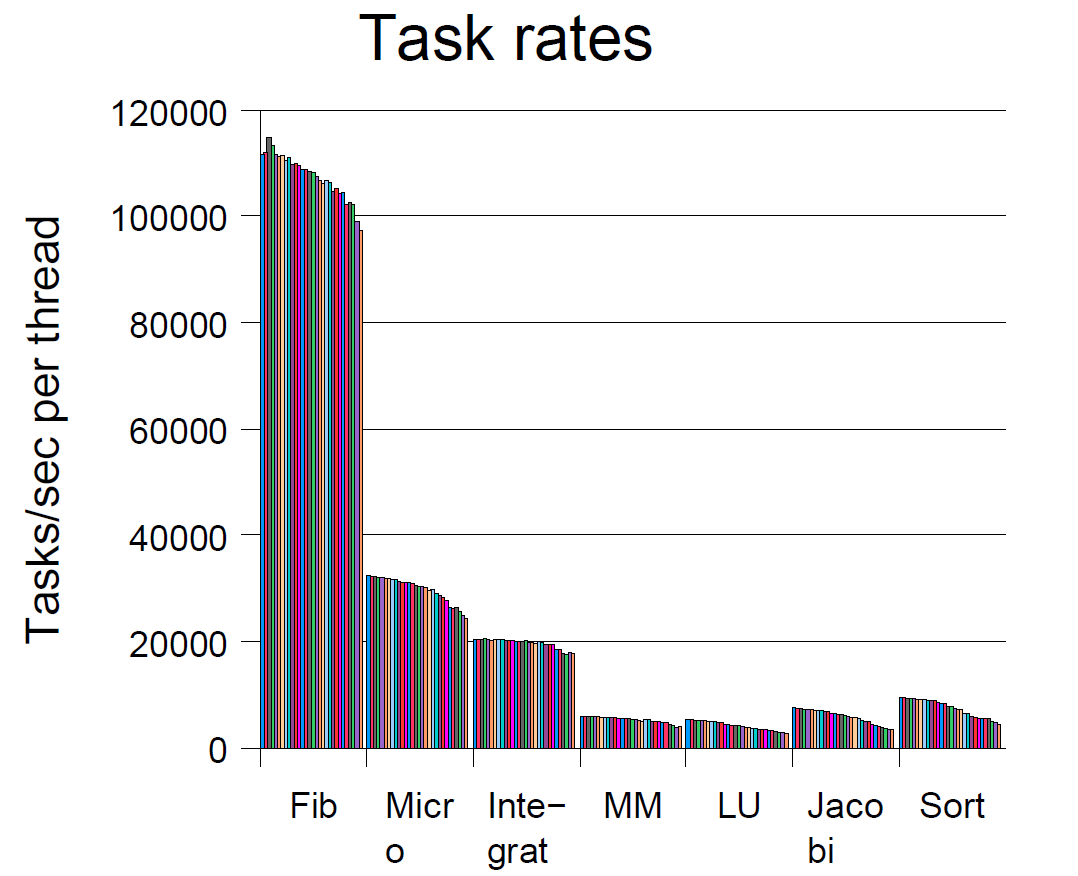
四个因素似乎可以解释在加速曲线的末端出现的下降不是线性的(不是一条直线)。它们中的三个对所有的并行框架都是适用的,但是,有一个对于FJTask是特殊的,即GC影响。
4.2 垃圾回收器
在很多情况下,现代GC设施能很好的满足fork/join框架:这些程序产生了大量的任务,同时,几乎它们中的所有任务在执行后迅速的被回收。在任何一个时刻,确定的fork/join程序需要最多p倍登记内存消耗——相比于这些程序的串行版本。分代的半空间拷贝回收器(包括JVM在[1]中使用的措施,译者注:Eden代的from和to区是相等的,因此叫“半空间”)能够很好的应对这种情况,因为它们仅仅遍历和拷贝没有被回收的区域。通过这样做,它屏蔽了在手动并行内存管理中需要处理的一个棘手问题:追踪那些被一个线程分配,但是被其它线程使用的线程空间。垃圾回收器明显的不需要知道内存分配的源头,因此它不需要处理这些问题。
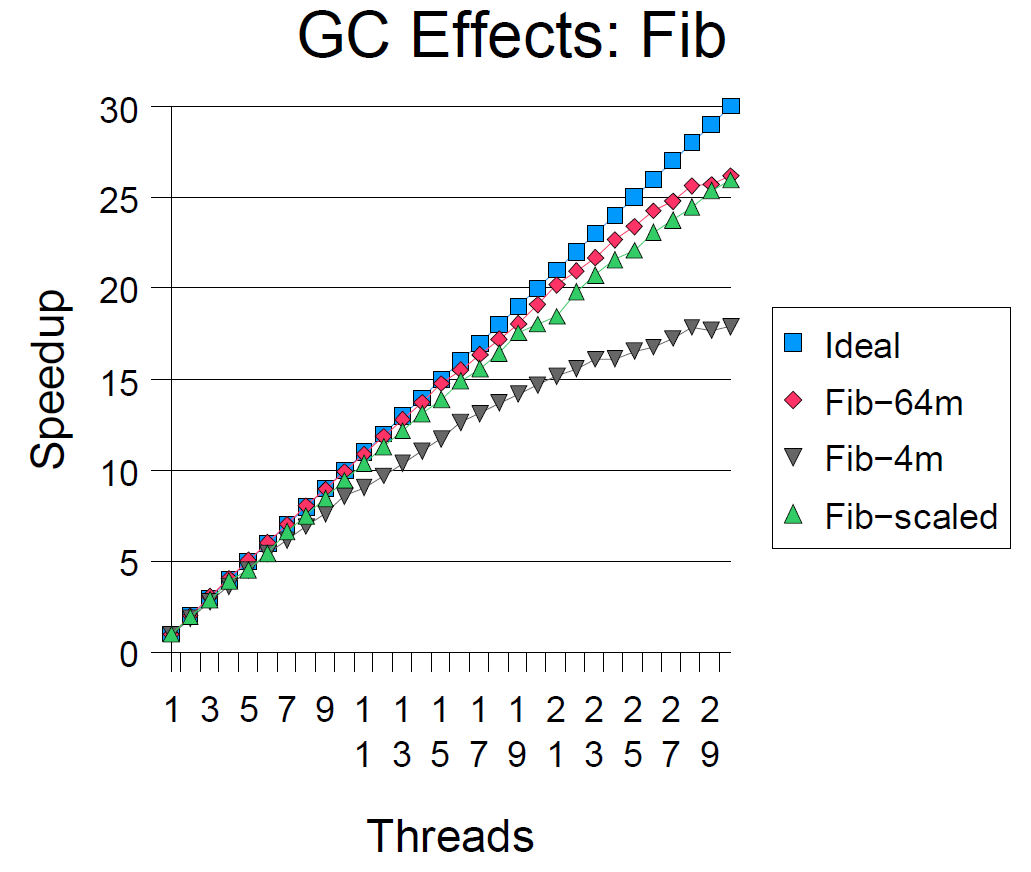
作为分代拷贝垃圾回收器优势的指示,一个四线程的Fib程序使用了5.1秒。但是,当使用主任务中的内存设置——即禁止内存拷贝时消耗了9.1秒(此时JVM的垃圾回收完全依赖mark-sweep过程)。然而,当内存分配率过高,线程必须停止来进行回收时这些GC机制会导致可伸缩性问题。上图显示了三种内存设置时的加速比(这个JVM支持可选的内存参数设置):默认4M的内存(可以理解为eden代的from区)、64M、 2*p+2M内存空间(p为线程数)。更小的内存时,随着线程增多,停止线程变得过多,垃圾回收代率上升,垃圾回收器开始影响伸缩性。
为减少这种影响,所有的测试程序都使用64M内存空间(译者注:这是足够大的空间)。一个更好的策略是,在每一个测试中,根据线程数进行动态调整(就像图表中示意的,它让所有的加速比更趋于线性)。此外,程序的任务粒度阈值可以随着线程数的增加而增加。
4.3 内存的局部性与带宽
四个程序在非常大的数组或矩阵上进行创建和计算测试:数字排序,矩阵相乘、分解、松弛迭代。在这些操作里面,排序可能是受这些因素影响最大的,因为它需要在处理器之间移动数据,它受到整个系统内存的聚合带宽的影响。为帮助弄清这些影响的实质,排序程序被分成四个版本:即byte,short,int,long数组。为确保其它因素一致,每个版本排序的数据值都在0到255之间。数据位越宽,需要越大的内存流量。测试结果显示,增加内存流量导致了很差的加速比。虽然,没有确定的证据证实,这是导致加速比减小的唯一因素。
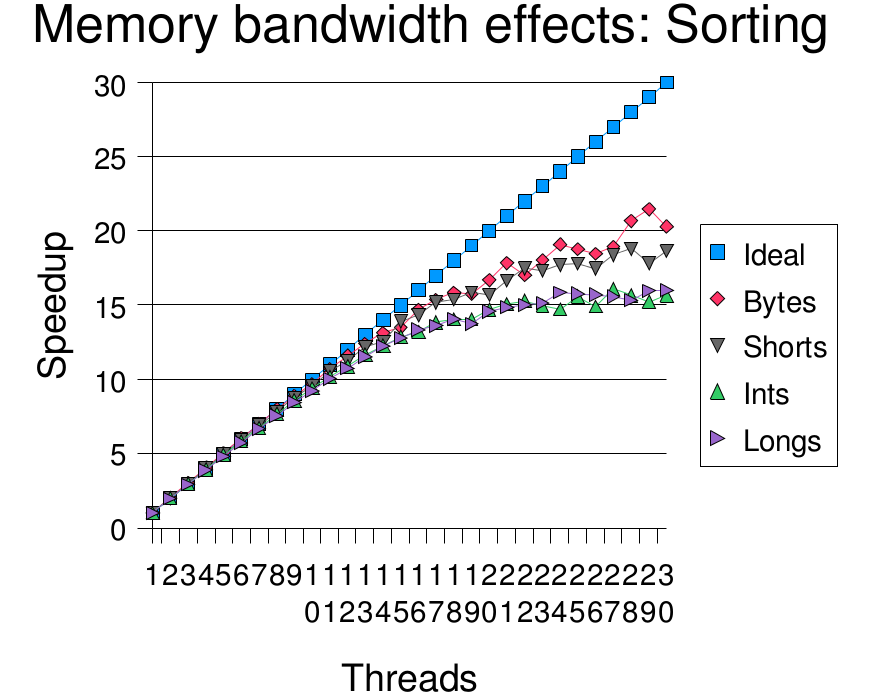
元素位长同时也影响绝对性能。比如,单个线程,排序byte数组花费122.5秒,排序long素组花费242.4秒。
4.4 任务同步
如同在3.2节讨论的,工作窃取框架有些时候,会遭遇线程间频繁的全局同步问题。工作线程持续的从队列中poll任务,虽然此时队列中没有。这是就产生了竞争,在FJTask中有时会强制线程空闲睡眠。
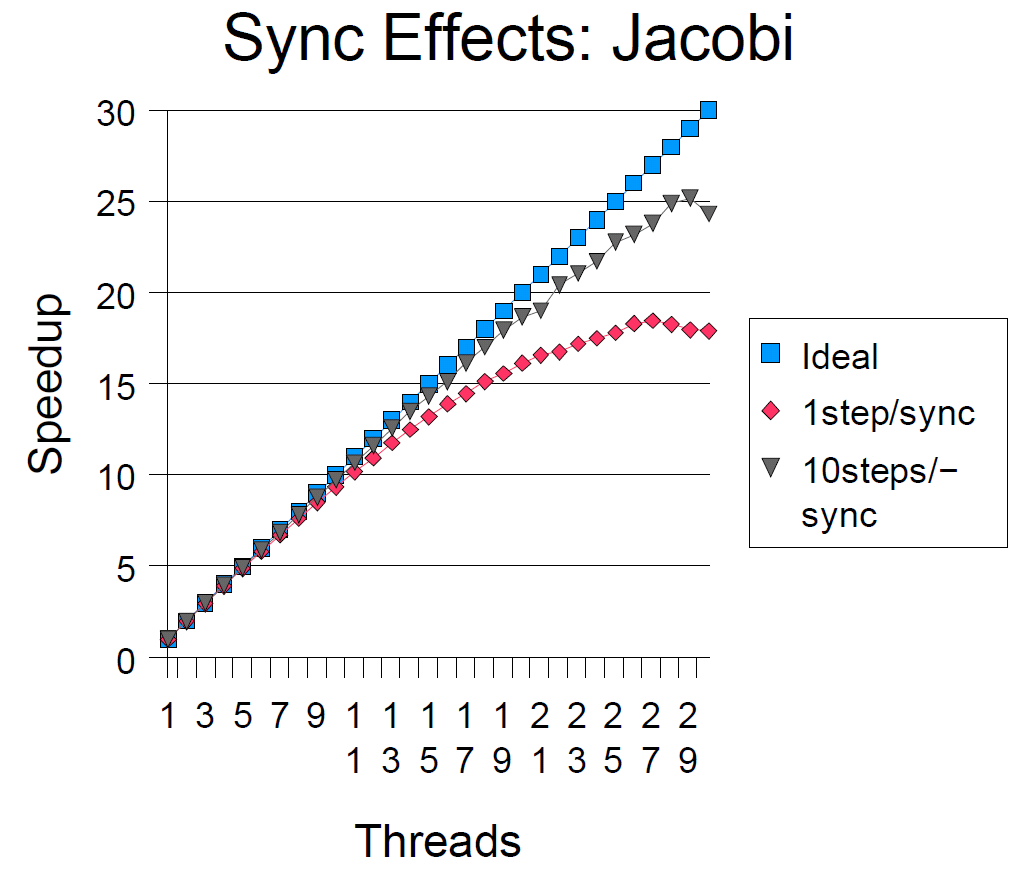
Jacobi程序说明了发生的问题。这个程序计算了100步,每一步,所有的单元都依据邻域平均规则更新。每一步间通过使用全局的栅栏隔离。为了确定同步影响的程度,这一程序的一个修改版本每10步才同步一次。尺度的不一样显示了对当前策略的影响,同时指示了这个框架将来需要包含附加的方法以允许程序员覆盖默认的参数和策略(然而,这张图也许稍稍聚集了纯同步的影响,因为10步同步版本似乎也保持较大的任务局部性)。
4.5 任务局部性
FJTask与其它的fork/join框架一样,为了worker线程消费它们自己创建的大部分线程而优化。当这一点没有满足时,由于以下两个原因它的性能会受到影响:
(1)窃取任务比从自己的队列取任务代价更大。
(2)在大部分访问共享数据的程序中,运行你自己的划分子任务意味着维持比较好的局部数据访问性。

从图表中可以看出,对于大部分的程序中,窃取任务所占的比例最多只是一小部分。然而,随着工作线程的增加,LU和MM程序产生了大的不平衡工作负载(因此有更多的窃取)。有可能通过算法的调整减小这种影响,从而产生更快的加速比。
4.6 与其它框架的比较
可能进行确定的意义非凡的不同测量,比较不通语言、不同框架。然而,相关的指标至少能够显示FJTask相对与其它语言实现的类似框架的优势和劣势。下面的表格比较了用Cilk,Hood,Stackthreads,Filaments实现的程序和FJTask框架的性能对比。所有这些程序都运行在4-CPU的Sun企业版450机器(前面已经介绍过)上。为了不需要重新配置其它的框架或测试程序,所有的测试运行在相较于上文中更小的问题集。通过编译器和运行时设置使得程序运行更快,并且所有的结果选择三次运行中最好的。Fib程序运行时没有设定粒度阈值,即使用默认的阈值1(在Filaments Fib程序中被设置为1024,这时它的表现与其它版本的一致).
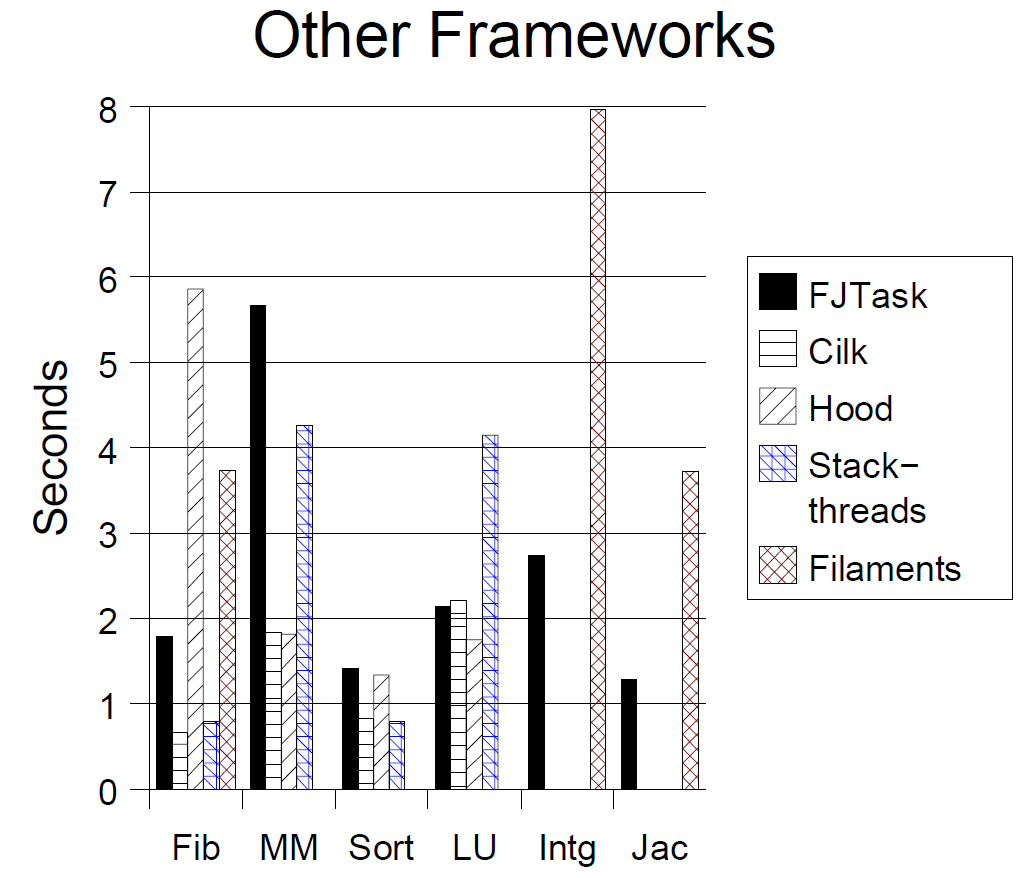
在一个线程和四个线程的版本中,不同框架测试程序的加速比非常接近(在3.0到4.0之间)。然而,对所有这些语言多线程版本的程序更快,因此不同点在于不同编译器指定的应用程序属性、优化开关、可配置参数。实际上,有很多与这里所用不同的选择,在许多高性能应用中能够产生类似的性能排名。
FJTask在主要进行数组、矩阵浮点计算的程序中通常表现更糟糕(在测试的JVM上)。虽然JVM在不断的改进,它依然比不过那些有着强大后台性能优化器的C/C++程序。虽然在这张表中没有画出,当编译优化禁用时,所有这些程序的FJTask版本比其它框架的程序要快。一些非正式的测试显示,大部分剩下的差异来自于数组边界检查和相关的编译器义务工作。它们显然时JVM和编译器开发者应当关心和努力解决的问题。当进行计算密集任务时,代码质量的不同会减少。
5.结论
这篇论文论述了,纯粹的Java语言也能够实现可移植、高效可伸缩的处理,并且能够为程序员提供便捷的API,程序员通过遵循简单的设计原则和设计模式能够利用这种便利。这里观察到的测试结果,不但为框架的使用者提供了思路,也为框架本身可能的改进提供了指导。
虽然,可伸缩的测试结果在这里只是在单JVM上测试,通用的经验观察数据值得注意:
分代GC算法通常能够很好适用于并行计算,但是频繁的GC会影响程序的可伸缩性。在这些JVM上,性能问题的底层原因是:GC暂停时间几乎正比于运行线程数。因为更多的运行线程会在单位时间内产生更多的GC,性能开销甚至攀升到接近线程数目二次方增长。尽管如此,这个明显的性能影响仅仅在GC率相对较高时才会出现。这个结果是将来研究和开发并行和并发GC算法的原因。这里呈现的结果也附加的说明了,在多处理器JVM上,提供调优选项和自适应机制是可取的。
大部分的可伸缩性测试仅仅只是在更多的CPU上进行,而不是在常规的多处理器上。FJTask(其它的fork/join框架也是)对于2路、4路、8路对称处理机都提供了一种理想的加速比。这篇论文似乎是第一篇在多于16处理器上进行的系统的常规多处理机fork/join框架报告。这里的结果在其它平台是否依然有效需要后续的测量。
应用程序的特点(包括内存局部性,任务局部性,使用全部同步)通常更需要权衡可伸缩度、绝对性能而不是框架特点、JVM或者底层OS。比如,非正式的测试显示,在双端队列中小心的避免全局同步在低任务产生率的程序中(比如LU)对性能几乎没有影响。然而,专注于保持任务小开销让它有更广泛的适用度,利用框架和相关的设计是一项编程技术。
除了持续的改进,将来在这个框架上的努力包括:构建有用的应用程序(与演示程序的对照和测试),在生产环境压力下的评估,在不同的JVM实现上的测试,为群集多处理器进行扩展开发等。
6. 致谢(译者:论文翻译至此告一段落,为确保完整性,后续部分将直接附上原文)
This work was supported in part by a collaborative research grant from Sun Labs. Thanks to Ole Agesen, Dave Detlefs, Christine Flood, Alex Garthwaite, and Steve Heller of the Sun Labs Java Topics Group for advice, help, and comments. David Holmes, Ole Agesen, Keith Randall, Kenjiro Taura, and the anonymous referees provided useful comments on drafts of this paper. Bill Pugh pointed out the read−after−write limitations of JVMs discussed in section 3.1. Very special thanks to Dave Dice for reserving time and performing test runs on the 30−way Enterprise.
7. 参考文献
[1] Agesen, Ole, David Detlefs, and J. Eliot B. Moss. Garbage Collection and Local Variable Type−Precision and
Liveness in Java Virtual Machines. In Proceedings of 1998 ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 1998.
[2] Agesen, Ole, David Detlefs, Alex Garthwaite, Ross Knippel, Y.S. Ramakrishna, and Derek White. An Efficient Meta−lock for Implementing Ubiquitous Synchronization. In Proceedings of OOPSLA ’99, ACM, 1999.
[3] Arora, Nimar, Robert D. Blumofe, and C. Greg Plaxton. Thread Scheduling for Multiprogrammed Multiprocessors. In Proceedings of the Tenth Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA), Puerto Vallarta, Mexico, June 28 − July 2, 1998.
[4] Blumofe, Robert D. and Dionisios Papadopoulos. Hood: A User−Level Threads Library for Multiprogrammed Multiprocessors. Technical Report, University of Texas at Austin, 1999.
[5] Frigo, Matteo, Charles Leiserson, and Keith Randall. The Implementation of the Cilk−5 Multithreaded Language. In Proceedings of 1998 ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), 1998.
[6] Gosling, James, Bill Joy, and Guy Steele. The Java Language Specification, Addison−Wesley, 1996.
[7] Lea, Doug. Concurrent Programming in Java, second edition, Addison−Wesley, 1999.
[8] Lowenthal, David K., Vincent W. Freeh, and Gregory R. Andrews. Efficient Fine−Grain Parallelism on Shared−Memory Machines. Concurrency−Practice and Experience, 10,3:157−173, 1998.
[9] Simpson, David, and F. Warren Burton. Space efficient execution of deterministic parallel programs. IEEE Transactions on Software Engineering, December, 1999.
[10] Taura, Kenjiro, Kunio Tabata, and Akinori Yonezawa. "Stackthreads/MP: Integrating Futures into Calling Standards." In Proceedings of ACM SIGPLAN Symposium on Principles & Practice of Parallel Programming (PPoPP), 1999.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号