


开启 Windows 系统中的 Beta 版 Unicode UTF-8 支持 会带来以下提升和潜在影响:通过修改注册表手动开启 Beta 版 Unicode UTF-8 支持,以下是具体步骤和注意事项:
Unicode Character Table - Full List of Unicode Symbols (◕‿◕) SYMBL
Unicode – The World Standard for Text and Emoji
ISO/IEC 10646:2020 - Information technology — Universal coded character set (UCS)
ISO/IEC 10646:2020 Universal coded character set (UCS)摘要
本文档:
- 指定了UCS的架构;
- 定义了UCS中使用的术语;
- 描述了UCS代码空间的一般结构;
- 指定了UCS的分配平面:UCS的基本多语言平面(BMP)、附加多语言平面(SMP)、附加表意平面(SIP)、第三表意平面(TIP)以及附加特殊用途平面(SSP);
- 定义了在全球范围内用于书写语言和文字形式的图形字符集;
- 指定了BMP、SMP、SIP、TIP、SSP中的图形字符和格式字符的名称及其在UCS代码空间中的编码表示;
- 指定了控制字符和私用字符的编码表示;
- 指定了UCS的三种编码形式:UTF-8、UTF-16和UTF-32;
- 指定了UCS的七种编码方案:UTF-8、UTF-16、UTF-16BE、UTF-16LE、UTF-32、UTF-32BE和UTF-32LE;
- 指定了对未来添加到此编码字符集的管理方式。
注:本文件未指定这些字符作为编程语言标识符的适用性,但相关信息可在外部参考资料中找到,见附录U。
UTF-8、UTF-16 和 UTF-32 三种编码形式的区别,以表格形式展示:
| 特性 | UTF-8 | UTF-16 | UTF-32 |
|---|---|---|---|
| 编码方式 | 可变长度编码 | 可变长度编码 | 固定长度编码 |
| 字符编码长度 | 1 到 4 字节 | 2 或 4 字节 | 4 字节 |
| 兼容性 | 向后兼容ASCII(0-127的字符与ASCII相同) | 不兼容ASCII(但兼容大多数Unicode字符) | 不兼容ASCII或任何其他编码 |
| 空间占用 | 最节省空间,ASCII字符仅占1字节 | 常用字符占用2字节,补充字符占用4字节 | 每个字符占用4字节,占用空间最大 |
| 字节顺序 | 无需考虑字节顺序(可以跨平台使用) | 有字节顺序(大端或小端) | 有字节顺序(大端或小端) |
| 优点 | 存储效率高,广泛使用,支持所有Unicode字符 | 支持所有Unicode字符,适用于大多数语言 | 字符定长,便于快速访问,适用于处理大规模文本 |
| 缺点 | 对非ASCII字符的编码较长 | 对非基本字符(补充字符)的编码较长 | 占用内存较多,空间效率差 |
| 常用场景 | 网络协议、网页、文件存储、操作系统 | 文字处理、操作系统(Windows等) | 数据库、内部处理需要快速访问字符的应用 |
主要区别:
- 编码长度:UTF-8是变长编码,使用1到4个字节;UTF-16通常使用2个字节(有些字符使用4字节);UTF-32每个字符使用4个字节。
- 空间效率:UTF-8对于ASCII字符非常高效(只占1字节),UTF-16和UTF-32则需要更多的存储空间。
- 兼容性:UTF-8与ASCII完全兼容,而UTF-16和UTF-32不兼容ASCII。
七种编码方案的区别,以表格形式展示:
| 编码方案 | 描述 | 字节顺序 | 编码长度 | 特点 |
|---|---|---|---|---|
| UTF-8 | 可变长度编码,兼容ASCII,广泛用于网络和文件存储 | 无(字节顺序无关) | 1 到 4 字节 | 最常用的UTF编码,节省空间,兼容现有的ASCII编码 |
| UTF-16 | 可变长度编码,使用16位为基本单元 | 无(字节顺序无关) | 2 或 4 字节 | 在大多数情况下使用2字节表示字符,4字节表示补充字符 |
| UTF-16BE | UTF-16的字节顺序大端模式(Big Endian) | 大端模式(High-Byte First) | 2 或 4 字节 | 字节顺序固定,适用于大端存储设备 |
| UTF-16LE | UTF-16的字节顺序小端模式(Little Endian) | 小端模式(Low-Byte First) | 2 或 4 字节 | 字节顺序固定,适用于小端存储设备 |
| UTF-32 | 固定长度编码,每个字符占4个字节 | 无(字节顺序无关) | 4 字节 | 每个字符使用固定的4字节表示,适合快速访问,但空间消耗大 |
| UTF-32BE | UTF-32的字节顺序大端模式(Big Endian) | 大端模式(High-Byte First) | 4 字节 | 字节顺序固定,适用于大端存储设备 |
| UTF-32LE | UTF-32的字节顺序小端模式(Little Endian) | 小端模式(Low-Byte First) | 4 字节 | 字节顺序固定,适用于小端存储设备 |
解释:
- 字节顺序:对于UTF-16、UTF-32等编码,字节顺序(大端或小端)决定了多字节字符在内存中的存储顺序。大端模式(Big Endian)将高字节存放在低地址,小端模式(Little Endian)将低字节存放在低地址。
- 变长 vs 固长:UTF-8是变长编码,而UTF-16和UTF-32可以是变长(UTF-16)或固定长度(UTF-32)。UTF-8节省空间,UTF-32适合快速字符访问但会占用更多内存。
UTF-8(Unicode Transformation Format - 8 bit)是Unicode字符集的一种编码方式,广泛应用于计算机系统、网络协议和文件格式中。它的主要特点是兼容ASCII编码,并且能够表示全球范围内的所有字符。以下是UTF-8在Windows中发展的时间线:
1. 1991年:Unicode标准发布
- 背景:Unicode标准诞生于1991年,旨在解决早期字符编码标准(如ASCII、ISO-8859-1等)无法处理全球语言字符的问题。Unicode的目标是为每个字符分配一个唯一的编号。
- 影响:此时,UTF-8作为Unicode的一种编码方式开始被提出。UTF-8能够有效地支持多语言并节省存储空间,它兼容ASCII编码,并通过使用可变长度编码来表示Unicode字符集中的所有字符。
2. 1993年:Windows NT 3.1发布
- 背景:Windows NT 3.1是微软推出的首个Windows NT系列操作系统,它支持32位处理,并且引入了对Unicode字符集的初步支持。
- 影响:尽管Windows NT 3.1的Unicode支持并未完全普及,但它为后续Windows操作系统中的Unicode编码机制奠定了基础。此时UTF-8尚未成为Windows系统中的主要字符编码,但Unicode的引入标志着UTF-8等编码方式在Windows中发展的开端。
3. 1995年:Windows 95发布
- 背景:Windows 95发布时,虽然它增加了对Unicode的支持,但仍以Windows-1252等单字节字符集为主。Windows 95对于UTF-8的支持较为有限,更多的是针对双字节字符集(如GB2312和Shift-JIS)进行优化。
- 影响:Windows 95标志着Unicode逐步进入操作系统,但UTF-8的普及尚未到来。
4. 1999年:Windows 2000发布
- 背景:Windows 2000进一步增强了对Unicode的支持,特别是在系统内核和API接口中。
- 影响:Windows 2000对Unicode的支持较为完善,系统内部逐渐开始使用UTF-8作为字符编码的补充方案。特别是在应用程序中,UTF-8成为一种常用的字符编码方式,尤其是在网络和跨平台开发中。
5. 2001年:Windows XP发布
- 背景:Windows XP强化了对Unicode的支持,特别是在用户界面、文件系统和多语言支持方面。
- 影响:Windows XP开始全面支持UTF-8,尤其在处理多语言文本时,UTF-8开始成为系统中更重要的编码格式。此时,用户能够通过使用Unicode(包括UTF-8)来处理各种语言和符号,而不必担心字符集不兼容的问题。
6. 2007年:Windows Vista发布
- 背景:Windows Vista进一步增强了Unicode支持,尤其是对于多语言环境的优化。
- 影响:UTF-8逐渐成为现代Windows操作系统中的标准字符编码之一。Windows Vista中加强了对国际字符集的支持,UTF-8成为开发者在处理网络通信、文本文件和多语言输入时的首选编码方式。
7. 2012年:Windows 8发布
- 背景:Windows 8继续增强对Unicode字符集的支持,特别是在系统API、应用商店以及跨平台开发方面。
- 影响:Windows 8和随后的版本进一步简化了多语言支持,推动了UTF-8的普及。应用程序和操作系统内部在多语言和跨平台开发中越来越倾向于使用UTF-8作为默认字符编码。
8. 2015年:Windows 10发布
- 背景:Windows 10对Unicode的支持已经达到全面兼容,包括UTF-8作为默认编码方式之一。
- 影响:Windows 10进一步提升了跨语言、跨区域的兼容性。UTF-8成为许多开发环境和工具的默认字符编码。在系统内部,Windows 10充分支持UTF-8,无论是文件系统、命令行界面,还是多语言环境下的文本输入,UTF-8都能够顺畅应用。
9. 2020年及以后的发展
- 背景:随着全球范围内的数字化和互联网发展,UTF-8已成为最流行的字符编码方式。
- 影响:Windows系统继续支持UTF-8,并且为开发者提供了广泛的工具和API,进一步加强了对UTF-8的支持。尤其在云计算、网络应用、数据库等领域,UTF-8已成为事实上的标准编码方式。
- 1991年:Unicode标准发布,UTF-8作为一种编码方式开始出现。
- 1993年:Windows NT 3.1引入Unicode支持,但UTF-8并未成为主要编码方式。
- 1999年:Windows 2000开始对UTF-8进行初步支持。
- 2001年:Windows XP全面支持Unicode,UTF-8逐渐得到广泛应用。
- 2007年:Windows Vista继续强化UTF-8的支持。
- 2012年:Windows 8进一步推动UTF-8的普及,尤其在多语言环境中。
- 2015年:Windows 10将UTF-8作为核心编码格式之一,全面支持UTF-8。
- 2020年及以后:UTF-8成为Windows及其他平台中的事实标准,广泛应用于开发和跨平台解决方案中。
UTF-8的广泛支持使得全球用户在使用Windows操作系统时能够处理各种语言和字符,从而促进了国际化和本地化的开发进程。
Unicode 字符集是什么?
Unicode 是一种全球统一的字符编码标准,旨在为计算机系统中的所有字符(包括语言字符、符号、表情符号等)提供唯一的数字表示。它为每个字符分配一个唯一的编码点(code point),通常以十六进制表示。例如,字母 "A" 的 Unicode 编码点是 U+0041。
Unicode 的目标是消除字符编码的局限性,使不同的计算机系统能够使用统一的编码来处理各种语言和符号。它不仅支持现代语言的字符,还包括历史语言、数学符号、音标、表情符号等。
Unicode 字符集是如何定义的?
Unicode 字符集通过将字符映射到一个 编码点 来定义每个字符。这些编码点按照不同的 编码方式(如 UTF-8、UTF-16、UTF-32)被存储和传输。
- 编码点(Code Point):每个字符在 Unicode 中都有一个唯一的编码点,表示该字符的数字值。例如,字母 "A" 对应的编码点是
U+0041,而汉字 "中" 的编码点是U+4E2D。 - Unicode 版本:Unicode 标准每隔一段时间发布新版本,扩展和更新字符集,增加新的字符、符号或语言的支持。
Unicode 是怎么样的?
Unicode 是一个极其庞大的字符集,包含了全球几乎所有的文字和符号。它不仅包括当前活跃的语言字符,还包含历史上使用过的字符。例如,古埃及象形文字、古希腊文等也都包含在其中。
Unicode 的编码方式有多种常见形式,包括:
- UTF-8:变长编码方式,兼容 ASCII。它使用 1 到 4 个字节来表示字符,效率较高,广泛用于网页和文件存储。
- UTF-16:变长编码方式,通常使用 2 或 4 个字节来表示字符。适合处理大量的多语言文本,尤其在 Windows 系统中应用广泛。
- UTF-32:固定长度编码,每个字符占 4 个字节。它的好处是能够直接访问字符,但由于其较高的存储成本,通常不用于存储大量文本。
Unicode 为什么需要存在?
Unicode 的诞生是为了解决计算机编码中存在的种种问题,尤其是不同字符集之间的不兼容性。在 Unicode 出现之前,不同国家和地区的字符编码标准彼此独立,导致了大量的兼容性问题。
-
字符集不兼容:早期的字符编码(如 ASCII、GB2312、ISO-8859)只支持特定的语言或字符集。不同语言的字符编码标准不兼容,导致同一个字符在不同系统中有不同的编码,造成乱码。
-
语言支持有限:许多早期的编码标准只支持少数语言。例如,ASCII 只支持英语,而 GB2312 只支持中文。要支持多语言系统,必须使用不同的编码集,这导致了开发和维护的复杂性。
-
全球化需求:随着全球化和国际化的发展,计算机系统需要支持多种语言的混合输入和输出。Unicode 提供了一个统一的标准,能够支持世界上几乎所有的语言和符号,从而解决了跨语言和跨地区的字符编码问题。
-
跨平台兼容性:Unicode 为不同操作系统、编程语言和应用程序之间的数据交换提供了标准,使得跨平台的软件开发变得更加容易。
Unicode 的优势
-
全球语言支持:Unicode 可以表示几乎所有语言的字符,包括现代语言、历史语言和符号系统。
-
跨平台兼容性:Unicode 使得不同操作系统、不同语言和不同文化背景下的计算机系统能够互相理解和处理字符数据。
-
节省存储空间:特别是 UTF-8 编码,能够在表示 ASCII 字符时只用 1 个字节,在存储其他字符时通过可变字节长度来节省存储空间。
-
支持符号和表情符号:Unicode 还支持图形符号(如数学符号、货币符号、表情符号等),使得文本不仅仅局限于文字。
-
标准化:Unicode 提供了一个统一的编码标准,避免了字符集冲突和编码不一致的问题。所有的字符都有唯一的 Unicode 编码点,消除了以前由于编码冲突导致的乱码问题。
总结
- Unicode 是一种全球统一的字符编码标准,旨在支持世界上几乎所有的语言、符号、表情符号等。
- 为什么需要 Unicode:为了解决早期不同字符集不兼容的问题,促进全球化、多语言系统的开发和跨平台的数据交换。
- 如何工作:Unicode 通过分配唯一的编码点给每个字符,并通过不同的编码方式(如 UTF-8、UTF-16、UTF-32)来表示这些字符。
Unicode 的出现使得计算机能够处理多种语言和符号,避免了字符集不兼容和乱码问题,推动了全球化信息交换的进步。
Unicode的发展经历了多个重要的阶段,逐步克服了早期字符编码的局限性,成为全球信息交换的标准。以下是Unicode的关键发展时间线:
1. 1988年:Unicode的构思
- 背景:早期的字符编码标准(如ASCII、ISO-8859系列)只能支持少数语言,无法处理全球多样化的字符。这导致了不同地区和语言之间的兼容性问题。
- 开始:美国国家标准化组织(ANSI)和计算机业界的专家们开始讨论创建一个可以支持全球所有字符的统一标准。
2. 1991年:Unicode 1.0发布
- 发布:Unicode 1.0版本首次发布,旨在为世界上所有的字符分配唯一的编码。它包含了大约 7,000 个字符,包括拉丁字母、希腊字母、阿拉伯字母等。
- 编码点范围:Unicode 1.0 定义了一个范围从
U+0000到U+FFFF的编码点,使用16位编码,可以表示约65,536个字符。
3. 1992年:Unicode 1.1发布
- 改进:Unicode 1.1扩展了字符集,新增了对更多语言和符号的支持。字符集扩展了对不同语言、符号、数字和表情符号的支持。
4. 1993年:Unicode 2.0发布
- 关键变化:Unicode 2.0引入了对更多语言的支持,包括对汉字、日文假名和韩文的支持,扩展了字符集至
U+0000到U+10FFFF。 - 编码点扩展:Unicode 2.0扩展了编码范围,支持了更多字符,尤其是亚洲语言的字符。现在Unicode可以支持超过一百万个字符,进一步解决了多语言环境下的编码冲突问题。
5. 1996年:UTF-8编码方案的广泛采用
- UTF-8:UTF-8编码方案得到广泛采纳,成为网络应用和互联网标准的主要编码格式。其特点是与ASCII兼容,且可以通过1到4个字节表示任何Unicode字符,因此非常适合网络传输。
6. 2000年:Unicode 3.0发布
- 更大扩展:Unicode 3.0对字符集进行了大规模扩展,加入了大量的符号、表情符号、古代文字等。该版本对数学符号、音标符号等进行了更加详细的补充。
- 版本增补:Unicode 3.0的发布标志着全球各大操作系统和编程语言开始更广泛地支持Unicode字符集。
7. 2003年:Unicode 4.0发布
- 重大更新:Unicode 4.0进一步扩展了字符集,新增了成千上万的字符,包括更多的历史语言字符(如古埃及象形文字)、手势符号等。
- 编码点增加:字符集的编码点范围从原来的
U+0000到U+10FFFF扩展到 32 位的编码系统。
8. 2010年:Unicode 6.0发布
- 表情符号支持:Unicode 6.0版本首次增加了表情符号(emoji)的支持,这是移动互联网和社交网络文化发展的一个标志。
- 新增字符:这一版本添加了大量的表情符号、音标、拉丁文字符、亚洲语言符号等。
9. 2015年:Unicode 8.0发布
- 表情符号扩展:Unicode 8.0对表情符号进行了进一步扩展,加入了更多的表情符号(如手势、人物、交通工具等),这些表情符号逐渐成为社交媒体交流的重要部分。
- 支持的字符增加:字符集继续扩展,支持更多语言和区域的特殊字符。
10. 2020年:Unicode 13.0发布
- 更多表情符号:Unicode 13.0进一步扩展了表情符号库,增加了新的表情符号和符号,同时进一步完善了对语言的支持,尤其是一些原本不那么普及的语言(如某些非洲语言)的字符支持。
- 字符集扩展:新增了大量的历史字符、符号和新的脚本。
11. 2023年:Unicode 15.0发布
- 最新版本:Unicode 15.0加入了更多字符,并扩展了对各种语言(尤其是少数民族语言)和历史文字的支持。特别是在全球文化的多样性上,Unicode不断进行扩展。
Unicode发展趋势
- 跨平台支持:Unicode继续推动跨平台和跨设备的兼容性,逐渐消除了不同系统之间字符显示不一致的问题。
- 表情符号的普及:随着社交媒体和即时通讯应用的普及,Unicode对表情符号和其他图形符号的支持越来越重要。
- 多语言支持:Unicode不断增加对少数民族语言、历史语言和各类符号系统的支持,促进全球文化的多样性表达。
总结
Unicode的发展历程显示了全球信息交流中对多语言、多符号支持的需求。它从最初的几千个字符逐步扩展到支持全球所有语言字符和符号,解决了跨平台、跨语言、跨文化的编码问题,成为全球计算机系统和互联网通信的基础标准。
UTF-8(Unicode Transformation Format - 8 bit)是一种广泛使用的字符编码方式,它具有以下几个主要优势:
1. 兼容性
- 向后兼容 ASCII:UTF-8 与 ASCII 完全兼容。对于任何 ASCII 字符(如英文字母、数字、标点符号等),其在 UTF-8 编码中的表示与 ASCII 编码相同,这意味着 UTF-8 可以无缝地处理和显示 ASCII 内容。
- 支持多种语言:UTF-8 是一种多字节编码,它能够表示全球所有语言的字符,包括各种符号、表情符号、汉字等。与其它编码方式相比,它提供了更强的跨语言支持。
2. 节省存储空间
- 对于英语等以拉丁字母为主的语言,UTF-8 使用 1 字节来表示每个字符,这样就可以节省存储空间。
- 对于需要表示其他字符集(例如汉字、阿拉伯字母等)的语言,UTF-8 则会根据需要使用 2、3 或 4 个字节。虽然对于这些字符需要更多的字节,但相较于一些其它编码(如 UTF-16),UTF-8 通常在存储空间上更为高效。
3. 可扩展性
- UTF-8 支持最大 4 字节的编码,这意味着它可以表示所有 Unicode 字符集中的字符。随着字符集的不断扩展,UTF-8 依然能够无缝支持新的字符。
- UTF-8 的可变长度设计意味着它能根据字符的复杂性动态调整字节长度,从而提高了对各种文本的处理灵活性。
4. 无 BOM(字节顺序标记)
- UTF-8 编码的一个优点是,它不需要在文件开头添加 BOM(字节顺序标记)。这使得 UTF-8 更加简洁,并且在文件传输或不同平台之间的互操作性方面更加稳定。相比之下,UTF-16 和 UTF-32 编码通常需要 BOM 来指示字节顺序。
5. 广泛支持与普及
- UTF-8 是全球范围内使用最广泛的字符编码,几乎所有现代编程语言、操作系统、数据库和 Web 技术都广泛支持 UTF-8。这意味着无论你在哪个平台上工作,UTF-8 都能确保高度的兼容性和跨平台支持。
6. Web 标准
- UTF-8 被 W3C 作为 Web 内容的标准编码方式。HTML 和 XML 等 Web 技术的规范都推荐使用 UTF-8。这使得开发人员在创建 Web 页面时,可以方便地处理多语言文本,避免了多种编码的兼容性问题。
为什么微软要使用 UTF-8?
微软决定广泛支持 UTF-8,原因包括:
-
全球化和多语言支持:微软希望其操作系统和应用程序能够在全球范围内处理不同语言的字符。通过采用 UTF-8,微软的产品可以轻松地支持多种语言和字符集,避免了使用特定字符集时的局限性。
-
跨平台兼容性:随着云计算和跨平台开发的兴起,微软的产品(如 Windows、Office 和 Azure 等)需要在不同平台和设备之间无缝工作。UTF-8 提供了良好的跨平台兼容性,使得 Windows 设备和非 Windows 设备之间的数据交换更加顺畅。
-
统一的编码标准:通过统一使用 UTF-8,微软可以减少不同编码之间的转换和不兼容问题,简化软件开发、数据存储和传输的复杂性,提升开发效率。
-
Web 和互联网应用的要求:UTF-8 是 Web 的标准字符编码,微软的浏览器(如 Edge)和开发平台(如 ASP.NET)支持 UTF-8,以确保 Web 应用程序的兼容性和性能。
-
现代开发需求:随着程序开发的多样化,UTF-8 提供了对所有字符的支持,无论是表情符号、特殊符号,还是其他语言的字符,都是 UTF-8 能够轻松处理的。因此,微软选择 UTF-8 可以帮助开发者处理更广泛的文本数据。
UTF-8 的优势在于它兼容性强、空间效率高、支持全球字符集、便于跨平台交换数据,且是 Web 开发的标准。考虑到这些优点,微软采纳并推行 UTF-8 作为其主流字符编码方式。
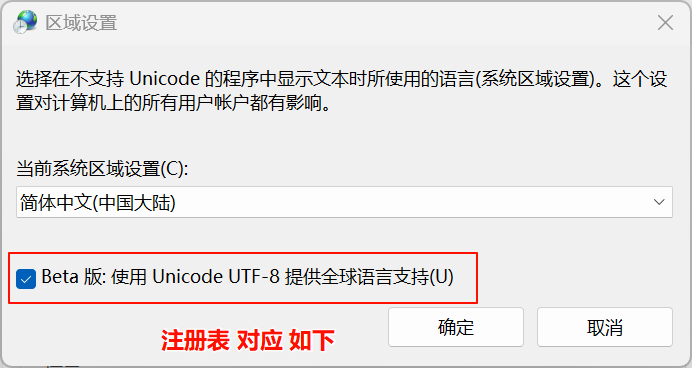
开启 Windows 系统中的 Beta 版 Unicode UTF-8 支持 会带来以下提升和潜在影响:
提升与优势
-
全球语言兼容性
-
UTF-8 是 Unicode 的通用编码标准,支持全球所有语言的字符(包括中文、日文、阿拉伯文、Emoji 等)。
-
解决了旧版程序在多语言混合文本中可能出现的乱码问题(例如同时显示中文和日文时)。
-
-
减少编码冲突
-
传统系统区域设置(如 GBK 代码页)可能导致非 Unicode 程序在处理特殊字符时出错(例如文件路径含日文或西欧字符)。
-
UTF-8 统一了编码规则,降低因编码不一致导致的文本损坏风险。
-
-
现代化开发支持
-
开发者无需为不同语言单独适配代码页,简化多语言软件和国际化(i18n)开发流程。
-
文件、数据库、网络传输等场景默认使用 UTF-8,符合现代技术标准。
-
-
命令行工具改进
-
在 CMD 或 PowerShell 中直接显示多语言字符(无需修改注册表或调整代码页)。
-
提升脚本和工具在跨语言环境下的稳定性。
-
潜在影响与风险
-
旧版软件兼容性问题
-
依赖特定代码页(如 GBK)的旧程序可能出现乱码或崩溃(例如某些早期游戏、企业级遗留系统)。
-
部分程序可能无法正确处理 UTF-8 字符长度(如某些加密或文本处理工具)。
-
-
系统级副作用
-
修改后会影响所有用户账户(需管理员权限),某些系统组件或服务可能异常。
-
需要重启生效,且无法与其他区域设置混合使用。
-
-
Beta 版稳定性
-
作为测试功能,可能存在未修复的 Bug(如字体渲染异常、输入法兼容性问题)。
-
微软可能在未来版本中调整或移除此功能。
-
建议操作
-
备份与测试
-
开启前备份重要数据,并测试常用软件(尤其是老旧程序)是否正常。
-
若发现问题,可通过相同设置界面关闭此功能并重启。
-
-
适用场景
-
推荐开发者、多语言用户或需要处理国际化文本的场景开启。
-
若仅需中文环境且无特殊需求,保持默认设置更稳妥。
-
-
替代方案
-
对单个程序,可通过修改其快捷方式的属性,单独设置兼容性模式(如强制使用 UTF-8 或指定代码页)。
-
开启 UTF-8 Beta 支持是迈向现代化多语言兼容的重要一步,但需权衡旧软件依赖性和系统稳定性。若日常使用场景涉及多语言或开发需求,值得尝试;反之则建议暂缓,等待微软正式发布此功能。
通过修改注册表手动开启 Beta 版 Unicode UTF-8 支持,以下是具体步骤和注意事项:
方法一:通过注册表编辑器手动修改
-
备份注册表
-
按下
Win + R,输入regedit打开注册表编辑器。 -
导航到以下路径:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage -
右键点击
CodePage项,选择导出,保存备份(如CodePage_Backup.reg)。
-
-
修改代码页为 UTF-8
-
在右侧窗口找到以下三个键值:
-
ACP(系统默认 ANSI 代码页) -
OEMCP(命令行和旧程序代码页) -
MACCP(Mac 兼容代码页)
-
-
将它们的值数据从原本的
936(简体中文 GBK)或其他数值,统一改为65001(UTF-8 的代码页编号)。 (示意图,非真实路径)
(示意图,非真实路径)
-
-
重启系统
-
修改后需重启才能生效。
-
方法二:使用注册表脚本(.reg 文件)
-
新建一个文本文件,输入以下内容:
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage] "ACP"="65001" "OEMCP"="65001" "MACCP"="65001" -
保存文件为
Enable_UTF8_Support.reg(注意扩展名为.reg)。 -
双击运行此文件,同意导入注册表。
-
重启系统。
验证是否生效
-
检查命令行
-
打开 CMD 或 PowerShell,输入
chcp,若显示Active code page: 65001表示成功。 -
尝试显示多语言文本(如中文 + 日文),观察是否乱码。
-
-
测试文件命名
-
创建包含特殊字符(如
测试_日本語_테스트.txt)的文件,确认资源管理器正常显示。
-
注意事项
-
系统版本要求
-
仅支持 Windows 10 1803 及以上版本或 Windows 11,旧系统可能无效。
-
-
恢复默认设置
-
若出现兼容性问题,双击之前导出的
CodePage_Backup.reg文件恢复原值,并重启。
-
-
潜在风险
-
修改注册表可能影响系统稳定性,建议提前创建系统还原点。
-
部分老旧程序(如某些游戏、财务软件)可能无法正确处理 UTF-8,需谨慎测试。
-
替代方案(推荐新手)
如果不想修改注册表,可通过系统设置直接开启:
-
按下
Win + S,搜索 “区域设置” → 进入 “管理语言设置” → “更改系统区域设置”。 -
勾选 “Beta 版: 使用 Unicode UTF-8 提供全球语言支持” → 确定并重启。
通过注册表修改更底层,但需谨慎操作。建议优先通过系统设置开启,若失败再用注册表方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号