
MyCat&DBLE
一、什么是MyCat
1.1
MyCat是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户开源把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储。而在最终用户看来,无论是哪种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
1.2
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库
- 数据库中间件产品
1.3
MyCat是一个开源的分布式数据库系统,但是由于真正的数据库需要存储引擎,而Mycat并没有存储引擎,所以并不是完全意义的分布式数据库系统。
Mycat是一个数据库中间件,也可以理解为是数据库代理。在架构体系中是位于数据库和应用层之间的一个组件,并且对于应用层是透明的,即数据库感受不到mycat的存在,认为是直接连的mysql数据库(实际上是连接的mycat,mycat实现了mysql的原生协议)
mycat的三大功能:分表、读写分离、主从切换
二、为什么要使用MyCat
2.1
例如操作系统是对各类计算机硬件的抽象。那么我们什么时候需要抽象?假如只有一种硬件的时候,我们需要开发一个操作系统吗?再比如一个项目只需要一个人完成的时候不需要leader,但是当需要几十个人完成时,就应该由一个管理者,发挥沟通协调等作用,而这个管理者对于他的上层来说就是对项目组的抽象。
同样的,当我们的应用只需要一台数据库服务器的时候我们并不需要MyCat,而如果你需要分库甚至分表,这时候应用要面对很多个数据库的时候,这个时候就需要对数据库层做一个抽象,来管理这些数据库,而最上面的应用只需要面对一个数据库层的抽象或者说数据库中间件就好了,这就是MyCat的核心作用。
所以可以这样理解:数据库是对底层存储文件的抽象,而MyCat是对数据库的抽象。
2.2
客户端拆分:
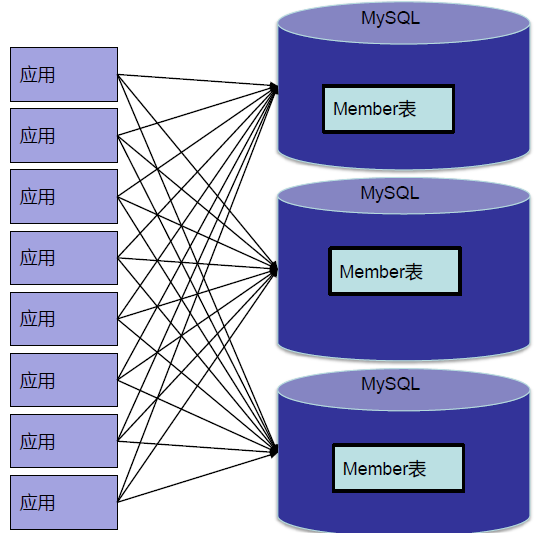
每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据库,在模块内完成数据的整合;
优点:相对简单,无性能损耗
缺点:不够通用,数据库连接的处理复杂,对业务不够透明,处理复杂
中间件模式:

通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明
优点:通用,对应用透明,改造少
缺点:实现难度大,有二次转发性能损失,单机损失30%左右
三、MyCat的关键特性
- 支持SQL92标准
- 支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法
- 遵守Mysql原生协议,跨语言、跨平台、跨数据库的通用中间件代理
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群
- 支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
- 基于Nio实现,有效管理线程,解决高并发问题
- 支持数据的多片自动路由与聚合,支持sum、count、max等常用的聚合函数,支持跨库分页
- 支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询
- 支持多租户方案
- 支持分布式事务(弱xa)
- 支持XA分布式事务
- 支持全局序列号,解决分布式下的主键生成问题。
- 分片规则丰富,插件化开发,易于扩展
- 强大的web,命令行监控
- 支持前端作为MySQL通用代理,后端JDBC方式支持Oracle、DB2、SQL Server、mongodb
- 支持密码加密
- 支持服务降级
- 支持IP白名单
- 支持SQL黑名单、sql注入攻击拦截
- 支持prepare预编译指令
- 支持非堆内存(Direct Memory)聚合计算
- 支持PostgreSQL的native协议
- 支持mysql和oracle存储过程,out参数、多结果返回
- 支持zookeeper协调主从切换、zk序列、配置zk化
- 支持库内分表
- 集群基于zookeeper管理,在线升级、扩容、智能优化,大数据处理
四、MyCat原理
MyCat就是一个数据库中间件,数据库的代理,它屏蔽了物理数据库,应用连接MyCat,然后MyCat再连接物理数据库。
MyCat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
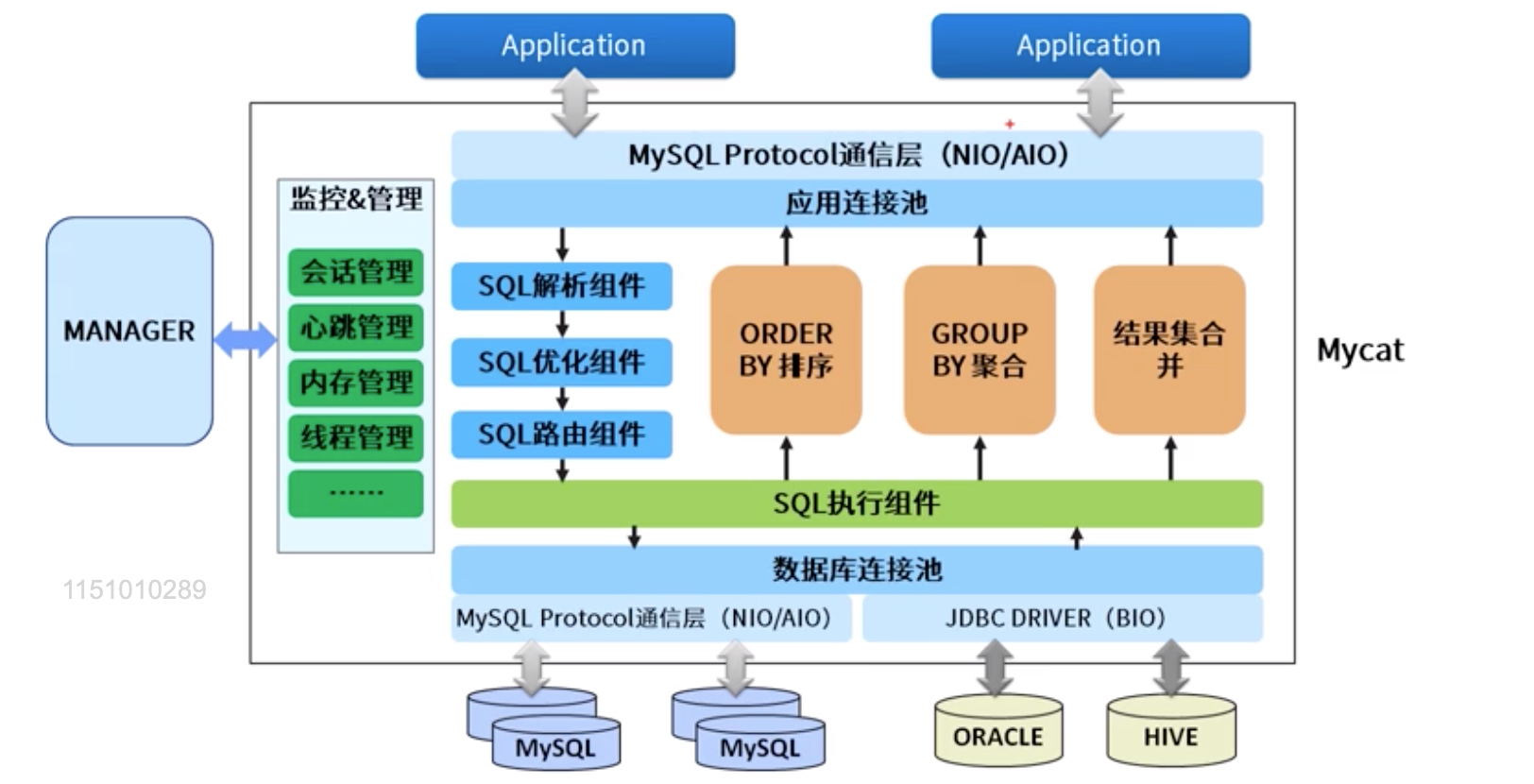
1.application提交sql后,经过sql解析,优化,路由,解析为对应的sql指令,交给具体的sql机器执行
2.各节点的计算结果进行结果集合并
3.manager负责master的集群管理,内存管理等
五、MyCat的核心技术
5.1
数据库分片指:通过某种特定的条件,将我们存放在一个数据库中的数据分散存放在不同的多个数据库(主机)中,这样来达到分散单台设备的负载,根据切片规则,可以分为以下两种切片模式

MyCat通过定义表的分片规则来实现分片,每个表格可以捆绑一个分片规则,每个分片规则指定一个分片字段并绑定一个函数,来实现动态分片算法。
1.Schema:逻辑库,与MySQL中的Datebase(数据库)对应,一个逻辑库中定义了所包括的Table。
2.Table:逻辑表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode。在此可以指定表的分片规则。
3.DataNode:MyCat的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上。
4.DataSource:定义某个物理库的访问地址,用于捆绑到Datanode上。
5.分片规则:前面奖励数据切分,一个大表分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难
5.2
数据切分:简单来说,就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
切分模式:
垂直切分--单库性能瓶颈
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面
优点:拆分后业务清晰,拆分规则明确;
系统之间整合或扩展容易;
数据维护简单
缺点:部分业务表无法join,只能通过接口方式解决,提高了系统复杂度;
受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高;
事务处理复杂
水平切分:按照某个字段的某种规则来分散到多个库之中,每个表包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表、分库两种模式
优点:不存在单库大数据,高并发的性能瓶颈;
对应用透明,应用端改造较少;
按照合理拆分规则拆分;
join操作基本避免跨库,提高了系统的稳定性跟负载能力
缺点:拆分规则难以抽象;
分片事务一致性难以解决;
数据多次扩展难度跟维护量极大
跨库join性能较差
5.3
5.3.1分表
对于数据量很大的表(千万级以上),mysql性能会有很大下降,因此尽量控制在每张表的大小在百万级别。对于数据量很大的一张表,可以考虑将这些记录按照一定的规则放到不同的数据库里面。这样每个数据库的数据量不是太大,性能也不会有太大损失。
mycat分表的实现:首先在mycat的scheme.xml中配置逻辑表,并且在配置中说明此表在哪几个物理库上。此逻辑表的名字与真实数据库中的名字一致!然后需要配置分片规则,即按照什么逻辑分库!
5.3.2读写分离
经过统计发现,对数据库的大量操作是读操作,一般占到所有操作70%以上。所以做读写分离还是很有必要的,如果不做读写分离,那么从库也是一种很大的浪费。
5.3.3 MyCat基本元素
1.逻辑库:MyCat中存在,对应用来说相当于mysql数据库,后端困难对应了多个物理数据库,逻辑库中不保存数据
2.逻辑表:逻辑库中的表,对应用来说相当于mysql的数据表,后端困难对应多个物流数据库中的表,也不保存数据
逻辑表分类
1)分片表:进行了水平切分的表,具有相同表结构但存储在不同数据库中的表,所有分片表的集合才是一张完整的表
分片表,是指那些有很大数据,需要切分到多个数据库的表,这样每个分片都有一部分数据,所有分片构成了完整的数据。
<table name="t_goods" primaryKey="vid" autolncrement="true" dataNode="dn1,dn2" rule="rule1" />
2)非分片表:垂直切分的表,一个数据库中就保存了一张完整的表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
<table name="t_node" primaryKey="vid" autolncrement="true" dataNode="dn1" />
3)全局表:所有分片数据库中都存在的表,如字典表,数据量少,由MyCat来进行维护更新
意义:例如国家列表,存量小(100w以下的数据表),需要经常和其他表进行join,所以可以用空间换取时间,防止跨库访问,则所有分片上面都放入全局表。
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动。
问题:业务表往往需要和字典表join查询,当业务表因为规模而进行分片以后,业务表与字典表之间的关联跨库了。
解决:MyCat中通过表冗余来解决这类表的join,即它的定义中指定的dataNode上都有一份该表的拷贝(将字典表或者符合字典表特性的表定义为全局表)
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3">
4)ER关系表:MyCat独有,子表依赖父表,保证在同一个数据库中
MyCat中的ER表是基于E-R关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,保证数据join不会跨库操作。
ER分片是解决跨分片数据join的一种很好的思路,也是数据切分规划的一条重要规则。
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile"> <childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id"> <childTable name="order_items" joinKey="order_id" parentKey="id"/> </childTable> </table>
六、什么是dble
dble是基于mysql的高可扩展性的分布式中间件,存在以下几个优势特性:
- 数据水平拆分:随着业务的发展,您可以使用dble来替换原始的单个MySQL实例。
- 兼容Mysql:与MySQL协议兼容,在大多数情况下,您可以用它替换MySQL来为你的应用程序提供新的存储,而无需更改任何代码。
- 高可用性:dble服务器可以用作集群,业务不会受到单节点故障的影响。
- SQL支持:支持SQL 92标准和MySQL方言。我们支持复杂的SQL查询,如group by,order by,distinct,join,union,sub-query等等。
- 复杂查询优化:优化复杂查询,包括但不限于全局表连接分片表,ER关系表,子查询,简化选择项等。
- 分布式事务支持:使用两阶段提交的分布式事务。您可以为了性能选择普通模式或者为了数据安全采用XA模式。当然,XA模式依赖于MySQL-5.7的XA Transcation,MySQL节点的高可用性和数据的可靠性。
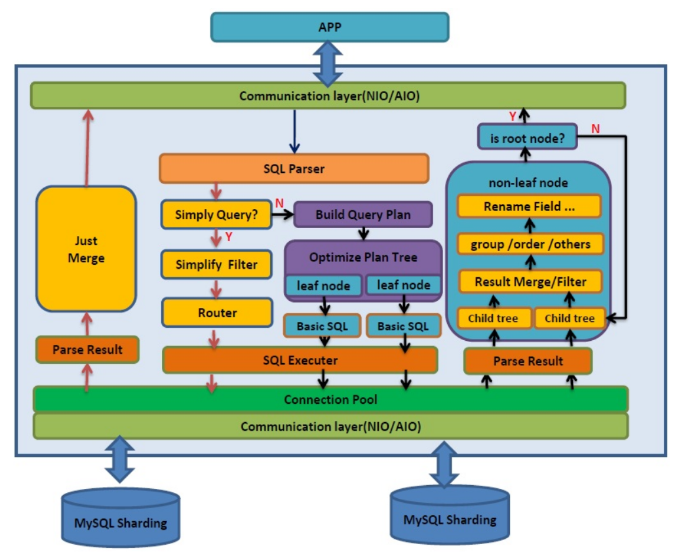
dble是基于开源项目MyCat的,但取消了多其他数据库的支持,专注于MySQL,对兼容性、复杂查询和分布式事务的行为进行了深入的改进/优化。修复了MyCat的一些bug。
dble内部架构:
七、dble的优势
7.1缺陷修复
目前MyCat社区不活跃,不再追钟MyCat的bug
- 由于堆外内存的使用不当,导致高并发操作时堆同一片内存可能发生“double free”,从而造成JVM异常,服务崩溃。#4
- XA事务漏洞:包乱序导致客户端崩溃。#21
- where关键字写错时,会忽视后面的where条件,会得到错误的结果,比如select * from customer wher id=1;#126
- 对于一些隐式分布式事务,例如insert into table values(节点1),(节点2):原生MyCat直接下发,这样当某个节点错误时,会造成该SQL执行了一部分
- 权限黑名单针对同一条sql只在第一次生效。#92
- 聚合/排序的支持度非常有限,而且在很多场景下还存在结果不正确、执行异常等问题。#43,#31,#44
- 针对between A and B语法,hash拆分算法计算出来的范围有误。#23
- 开启全局表一致性检查时,对全局表处理存在诸多问题,例如不能alert table、insert……on duplicate……时不更新时间戳、update……in()报错等。#24,#25,#26,#5
- 多值插入时,全局序列生成重复值。#1
- ER表在一个事务内被隔离,不能正确插入子表数据。#13
- sharding-join结果集不正确。#17
详情及其他修正:修复列表
7.2实现改进
- 对某些标准SQL语法支持不够好的方面做了改进,例如对create table if not exists..、alter table add/drop [primary] key...等语法的支持。
- 对整体内部IO结构进行了大幅的改造和调优。
- 禁止普通用户连接管理端口进行管理操作,增强安全性。#56
- 对全局序列做了如下改进:
· 删去无工程意义的本地文件方式。
· 改进数据库方式、ZK方式,使获取的序列号更加准确。
· 修复了数据库方式全局序列中线程安全的问题。#489
· 移除自定义语法限制:全局序列值不能显式指定
@ 原来:insert into table(id,name) values(next value for MYCATSEQ_GLOBAL,'test');
@ 现在1:insert into table(name) values('test');
@ 现在2:insert into talbe values('test');
@ 注意时间戳方式需要该字段是bigint。
- 改进对ER表的支持,智能处理连接隔离,解决同一事物内不可以同时写入父子表的问题,并优化ER表的执行计划。
- 系统通过智能判断,对于一些没有显示配置但实际符合ER条件的表视作ER表同样处理。
- 在中间件内进行智能解析与判断,使用正确的schema,替换有缺陷的checkSQLschema参数。
- conf/index_to_charset.properties的内容固化到代码。
- 对于前端按照用户限制连接数、限制总连接数。
- 改进原本的SQL统计,增加UPDATE/DELETE/INSERT
7.3功能增强
- 提供了更强大的查询解析树,取代ShareJoin,使跨节点的语法支持度更广(join,union,subquery),执行效率更高,同时聚合/排序也有了较大改进。
- 提供科学的元数据管理机制,更好的支持show、desc等管理命令,支持部指定columns的insert语句。#7
- 元数据自动检查:
· 启动时对元数据进行一致性检查。
· 配置定时任务,对元数据进行一致性检查。
- 提供更详实的执行计划,更准确的反映SQL语句的执行过程。

- set系统变量语句的改进。
- set charset/names语句的支持。
- 分布式事务:XA实现方式的异常处理的改进。
- 大小写敏感支持。
- 支持DUAL。
- 支持单词请求多语句(部分客户端有使用,C和C++常见)。
- 不断丰富的路由规则优化和条件优化。
- 升级Druid,跟进最新的解析器。
- 升级fastjson,避免安全问题。
- 智能判断reload连接变更,热更新连接池。
- 对MySQL协议及GUI工具/Driver更友好的支持。
- 增加更多的管理端命令,满足更多运维需要。
- 缓存支持使用RocksDB。
- 增加慢查询日志功能,兼容mysqldumpslow和pt-query-digest。
- Trace功能,用于分析单条查询的性能瓶颈。
- 大小写明哥依赖于后端MySQL。
- 支持Prepared SQL Statement Syntax。
- 支持以下子查询:
· The Subquery as Scalar Operand.#子查询作为标量操作数
` Comparisons Using Subqueries.#比较使用子查询
· Subqueries with ANY,IN or SOME
` Subqueries with ALL
` Subqueries with EXISTS or NOT EXISTS
` Derived Tables(Subqueries in the FROM Clause)#派生表(FROM子句中的子查询)
- 支持dble层面的View。
- 支持MySQL8.0默认登录验证插件。
- 提供自定义告警接口。
- 支持自定义拆分算法。
- 支持自增列可以设置为非主键列。
- 可以观察执行中的DDL。
- 提供配置预检查功能。
- 流量暂停和恢复功能。
7.4功能裁减
- 仅保留枚举、范围、HASH、日期等分片算法,对这几个算法进行了可用性的改进,使之更加贴合实际应用,项目需要时可以按需提供。
- 移除异构数据库支持。
- 禁止某些不支持的功能,这些功能客户端调用时不会报错,但结果并非用户想要的结果,例如无效的set语句。
- 移除目前实现由问题的第一结点库内分表模式。
- 移除writeType参数,等效于原来writeType=1。
- 移除handleDistributedTransactions选项,直接支持分布式事务。
八、MyCat与DBLE比较
8.1Nio线程处理
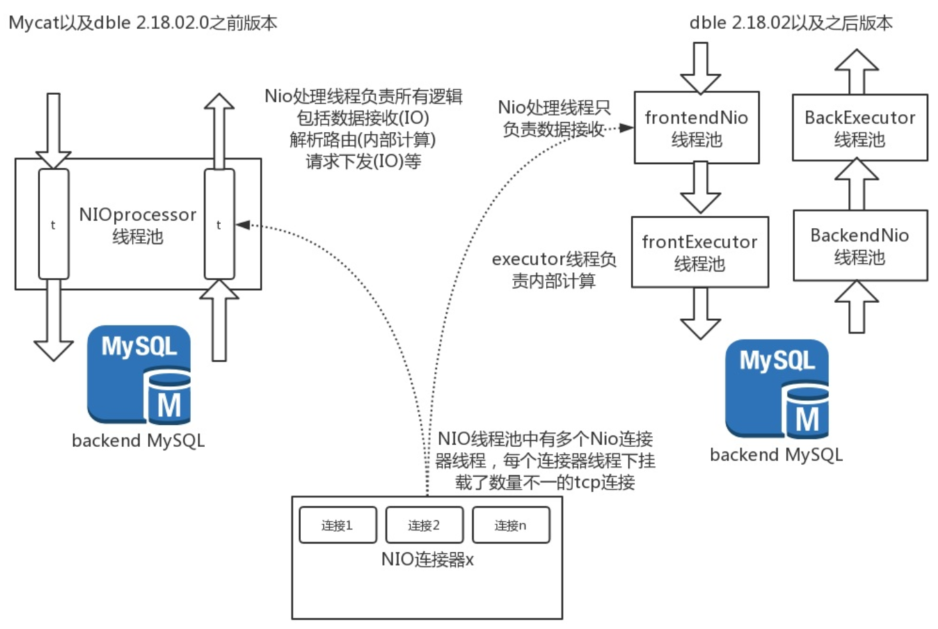
Nio处理器(处理线程)内部为挂载不定数量个连接,并且循环响应每个连接的请求。
在数据处理和数据接收进行线程分割之后(dble 2.18.02),使得dble可以并发响应挂载在同一个NIO连接器(同一个processor线程)上的请求。
eg:恰好我们存在场景连接1,2同时有请求过来,旧版本需要循环处理连接1,2的任务,在连接1的任务处理完成之前,连接2的任务无法进行处理。
在新的IO结构中,连接1的数据被接收完毕周,NIO线程旧可以接收连接2的数据,并且此时连接1的数据以及在executor线程池进行处理中,连接1,2之间的任务执行变成并行。
九、参考资料
https://blog.csdn.net/nxw_tsp/article/details/56277430
https://blog.csdn.net/sinat_27933301/article/details/81292276
https://www.jianshu.com/p/c6e29d724fca
https://www.cnblogs.com/wenbronk/p/7819224.html
https://www.jianshu.com/p/f02a48226222
https://www.jianshu.com/p/87c7a5abd74a
《dble-manual.pdf》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号