github爆火仓库996.ICU大数据分析
github爆火仓库996.ICU大数据分析
一、选题的背景
996.ICU是是Github用户996icu发起的,有专门的网站: http://996.icu 。 广大对于996工作制不满的程序员们通过star这个Github repos来表达自己的立场。
截止目前该项目在github上已经有256000多个start,并且持续高涨。
作为一个数据猿,我们当然不能只观望呀。我们获取了大量该repos issues页面下的评论数据,以及star了该repos的程序员Github个人信息数据。看看这些程序员都来自哪里,是怎么样的存在?大家关于996,反应最多的问题是什么?
996工作制是指早上9点上班、晚上9点下班,中午和傍晚休息1小时(或不到),总计工作10小时以上,并且一周工作6天的工作制度。
“996”工作制的周工作时间为最低60小时
这一制度,反映了中国互联网企业盛行的加班文化
二、大数据分析设计方案
1.本数据集的数据内容与数据特征分析
本案例数据基于GIthub关注996.ICU的用户,数据共计40000条,其中996.ICU仓库的评论数据约10000条,关注仓库的用户信息约40000条。
User_data拥有的字段:用户简介、博客、所在单位、账号创建时间、email、关注者数、被关注者数、是否能雇用、ID、所在地址、名字、组织url、公开repos数、更新时间等
Issues_data拥有的字段:issue评论数、ID、issue题目、更新时间、提问者ID
2.数据分析的课程设计方案概述
对的数据进行数据清洗等处理,利用清洗后的数据分析关注996.ICU的github程序员的群体画像,充分了解程序员对996的看法。
三、数据分析步骤
导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pymongo import MongoClient
from pandas.io.json import json_normalize
plt.style.use('ggplot')
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
%matplotlib inline
链接mongodb数据库
client = MongoClient('mongodb://admin:admin888@127.0.0.1:27017')
db = client.get_database('Github996') # 连接到Github996数据库
取到用户表数据
users = db.get_collection('users')
data = users.find() # 查询这个集合下的所有记录
user_data = pd.json_normalize([record for record in data])
取到评论表数据
issues = db.get_collection('issues')
data = issues.find() # 查询这个集合下的所有记录
issues_data = pd.json_normalize([record for record in data])
用户表数据展示
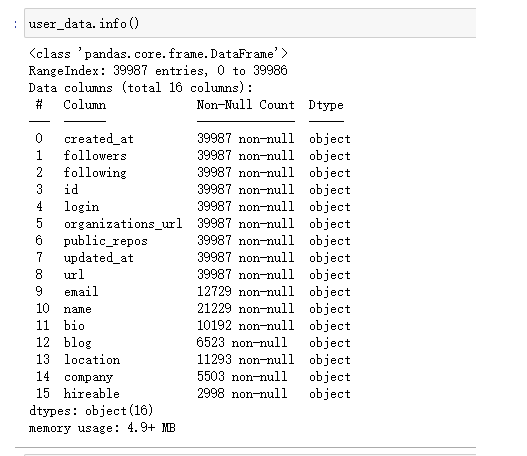
user_data.info()

User信息数据清洗
# 先去除对于分析无用的字段
user_data.drop(columns = ['_id', 'avatar_url', 'events_url', 'followers_url', 'following_url',
'gists_url', 'html_url', 'node_id', 'public_gists',
'received_events_url', 'repos_url', 'site_admin', 'starred_url',
'subscriptions_url', 'type'],
inplace = True)
user_data.info()
# 字段的类型转换
user_data['updated_at'] = pd.to_datetime(user_data['updated_at'])
user_data.followers = user_data.followers.astype('int64')
user_data.following = user_data.following.astype('int64')
user_data.public_repos = user_data.public_repos.astype('int64')
user_data['created_at'] = pd.to_datetime(user_data['created_at']).dt.tz_localize(None
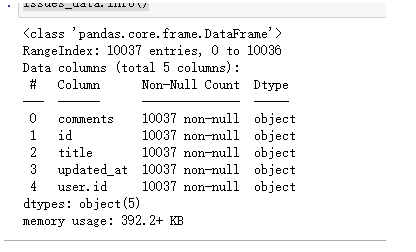
Issues数据清洗
# 由于字段太多,直接抽取想要的字段
issues_data = issues_data[['comments', 'id', 'title', 'updated_at', 'user.id']]
issues_data.info()
# 时间类型转换
issues_data['updated_at'] = pd.to_datetime(issues_data['updated_at'])
- 3.1 关注996的程序员,都来自于哪些单位?
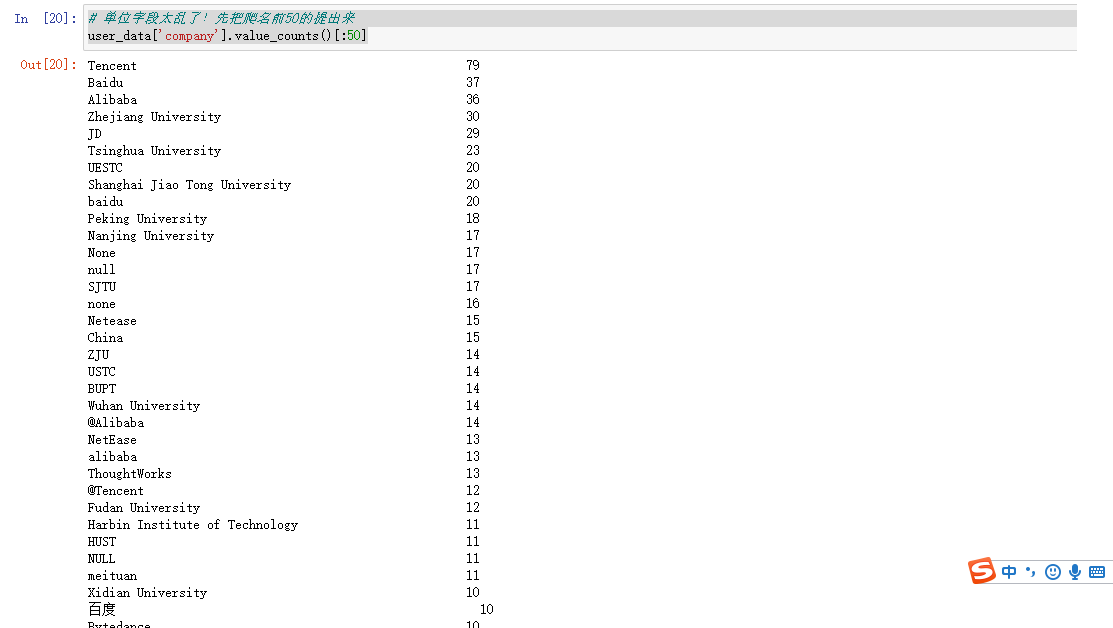
# 单位字段太乱了!先把爬名前50的提出来
user_data['company'].value_counts()[:50]
user_data['company'].value_counts()[:100].index
def get_company(data):
for com in ['encent', '腾讯']:
if com in data:
return '腾讯'
for com1 in ['aidu', '百度']:
if com1 in data:
return '百度'
for com2 in ['libaba', '淘宝', 'aobao', 'lipay', '阿里巴巴', 'liyun', '阿里云']:
if com2 in data:
return '阿里系'
for com3 in ['JD', 'jd', '京东']:
if com3 in data:
return '京东'
for com4 in ['etease', 'etEase', '网易']:
if com4 in data:
return '网易'
for com5 in ['eituan', '美团']:
if com5 in data:
return '美团'
for com6 in ['ytedance', '字节', '头条']:
if com6 in data:
return '头条'
for com7 in ['eleme', '饿了么']:
if com7 in data:
return '饿了么'
for com8 in ['uawei', '华为']:
if com8 in data:
return '华为'
for com9 in['didi', 'DiDi', '滴滴', '嘀嘀']:
if com9 in data:
return '滴滴'
user_data['company_top'] = user_data.loc[user_data['company'].notna(), 'company'].apply(get_company)
top10_com = user_data['company_top'].value_counts()
from pyecharts import Bar
bar = Bar("关注996工作制的程序员所在公司Top10", width = 700,height=500)
bar.add("", top10_com.index, top10_com.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True,
xaxis_rotate=30)
bar
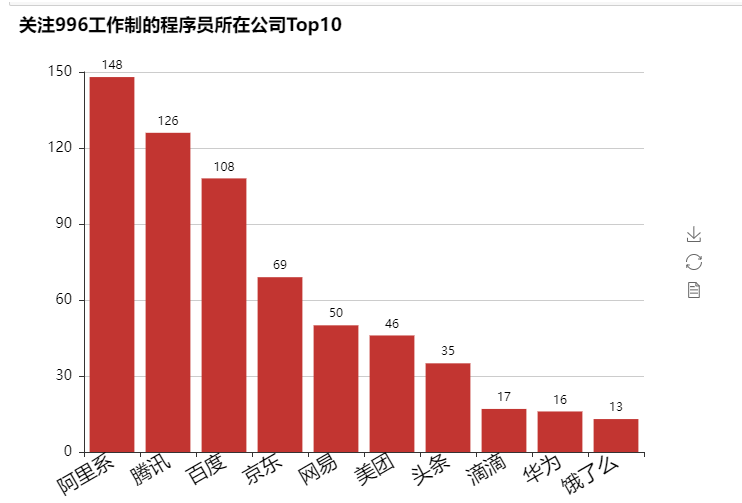
所有公司中,关注996的程序员最多的是来自阿里系的公司,有148人,其次是腾讯、百度、京东等。当然,还有很多来自小米、微软、谷歌、中兴、联想等各个公司的程序员。
def get_uni(data):
for uni in ['hejiang', 'ZJU', 'zju', '浙江大学', '浙大']:
if uni in data:
return '浙大'
for uni2 in ['singhua', '清华大学']:
if uni2 in data:
return '清华'
for uni3 in ['Shanghai Jiao Tong', 'SJTU', '上海交大', '上海交通大学']:
if uni3 in data:
return '上海交大'
for uni4 in ['UESTC', '电子科大', '电子科技大学']:
if uni4 in data:
return '电子科大'
for uni5 in ['Wuhan', '武大', '武汉大学']:
if uni5 in data:
return '武大'
for uni6 in ['USTC', '中科大', '中国科学技术大学']:
if uni6 in data:
return '中科大'
for uni7 in ['Fudan', '复旦']:
if uni7 in data:
return '复旦'
for uni8 in ['arbin', '哈']:
if uni8 in data:
return '哈工大'
for uni9 in ['BUPT', '北邮', '北京邮电']:
if uni9 in data:
return '北邮'
user_data['uni_top'] = user_data.loc[user_data['company'].notna(), 'company'].apply(get_uni)
top10_uni = user_data['uni_top'].value_counts()
bar = Bar("关注996工作制的程序员所在大学Top10", width = 700,height=500)
bar.add("", top10_uni.index, top10_uni.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True,
xaxis_rotate=30)
bar
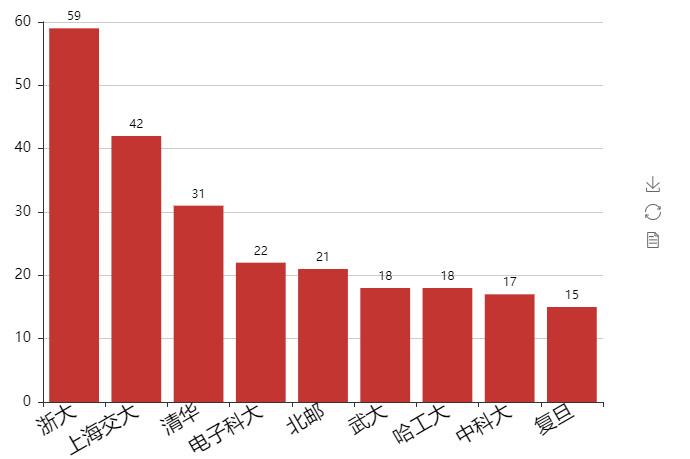
可以看到,浙大以59人star了该repos排名榜首,其次是上海交大、清华、电子科大、北邮、武大、哈工大、中科大、复旦大学。还有很多人来自于华中科大、卡耐基梅隆大学、北航、北理工、中山大学等学校的学生。
- 3.2 关注996的程序员,都来自于哪些城市?
user_data['location'].value_counts()[:50].index
def get_city(data):
for city in ['eijing', '北京']:
if city in data:
return '北京'
for city1 in ['hanghai', '上海']:
if city1 in data:
return '上海'
for city2 in ['Hangzhou', 'hangzhou', '杭州']:
if city2 in data:
return '杭州'
for city3 in ['henzhen', '深圳']:
if city3 in data:
return '深圳'
for city4 in ['Guangzhou', 'guangzhou', '广州']:
if city4 in data:
return '广州'
for city5 in ['hengdu', '成都']:
if city5 in data:
return '成都'
for city6 in ['anjing', '南京']:
if city6 in data:
return '南京'
for city7 in ['ingapore', '新加坡']:
if city7 in data:
return '新加坡'
for city8 in ['Hong Kong', 'hong kong', '香港']:
if city8 in data:
return '香港'
for city9 in ['uhan', '武汉']:
if city9 in data:
return '武汉'
user_data['city_top'] = user_data.loc[user_data['location'].notna(), 'location'].apply(get_city)
top10_city = user_data['city_top'].value_counts()
bar = Bar("关注996工作制的程序员所在城市Top10", width = 700,height=500)
bar.add("", top10_city.index, top10_city.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True,
xaxis_rotate=30)
bar
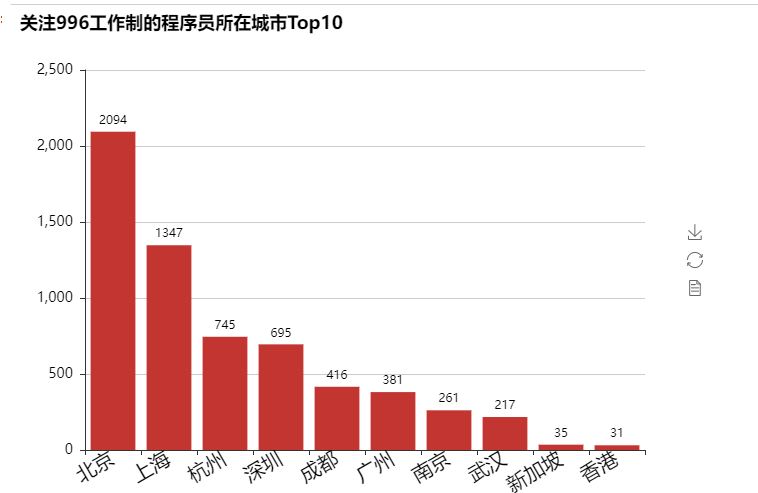
北京以2094人位居榜首!其次是上海、杭州、深圳等等。这些城市,恰恰是国内互联网行业发展得最好的城市。看来这个repos确实在全国程序员界都引起了巨大的反响。
- 3.3 关注996的程序员的画像
# 关注996工作制的程序员Github平均粉丝数、关注数、仓库数
user_mean = user_data[['followers', 'following', 'public_repos']].mean()
bar = Bar("关注996工作制的程序员Github平均粉丝数、关注数、仓库数", width = 500,height=500)
bar.add("", ['粉丝数', '关注数', '仓库数'], np.round(user_mean.values, 1), is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar
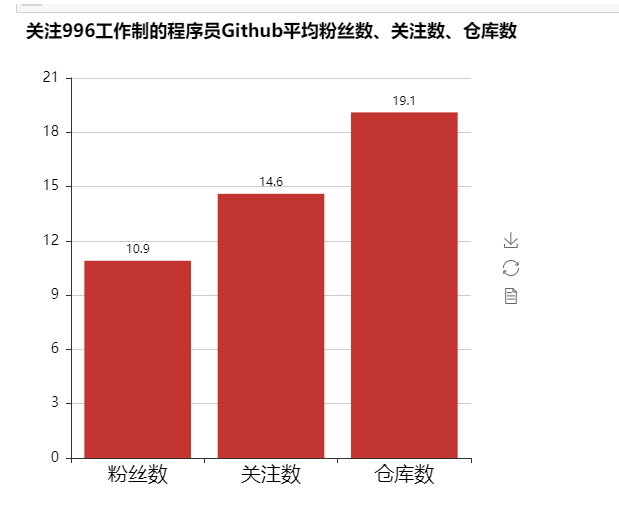
这群程序员的平均粉丝数为10.9,关注数为14.6,repos数为19.1。
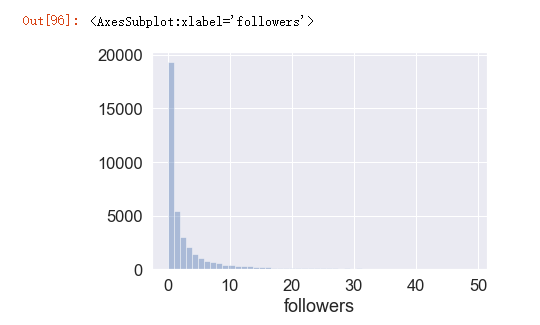
由于数据是严重的右偏分布,所以我们把粉丝数大于50的都过滤掉了。可见,大部分程序员的粉丝都在10人以内。
# 关注996工作制的程序员注册Github时长
user_data['time'] = pd.to_datetime('2019-03-28')- user_data['created_at']
user_data['time'].mean()
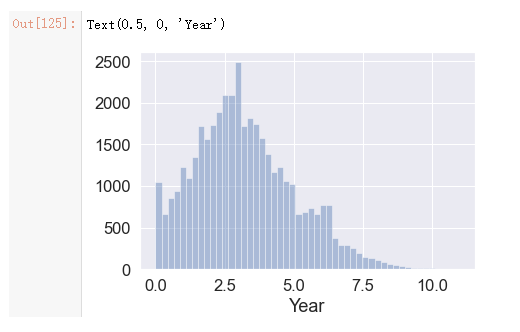
# 平均注册市场3.2年
1180/365 = 3.232876712328767
def get_days(data):
return data.days
user_data['time_days'] = user_data['time'].apply(get_days)/365
# 关注996工作制的程序员注册Github时长分布图
sns.set(font_scale=1.5)
ax = sns.distplot(user_data['time_days'], kde=False)python
ax.set_xlabel('Year')
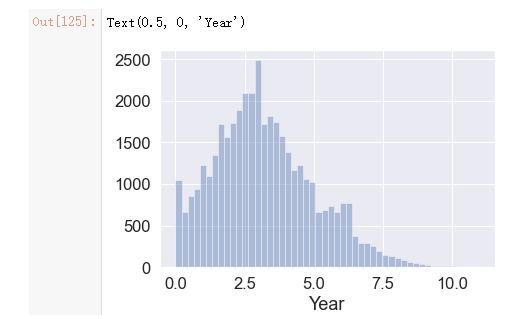
数据显示,这群程序员平均Github时长为3.2年,其中大部分Github时长在5年以内,5年以上的老程序员相对较少。
# 关注996工作制的程序员大牛
user_data.loc[user_data['followers'] > 3000, ['login', 'followers','url', 'bio']]

我们把粉丝数排名前10的程序员筛了出来。
排名第一的是一个熟悉的面孔,轮子哥!另外有来自腾讯的Coco,来自滴滴的singwhatiwanna,技术博主颜海镜等,这些人都在关注996。在39987个star了该repos的程序员中,粉丝数大于1000的有47人,大于500的有110,大于100的有598人。说明还是有很多有影响力的程序员在关注996工作制。
user_data[user_data['followers'] > 1000].shape[0]
#47
user_data[user_data['followers'] > 500].shape[0]
#110
user_data[user_data['followers'] > 100].shape[0]
#598
- 3.4 大家所关注的问题都有哪些?
issues_data.comments = issues_data.comments.astype('int64')
issues_data.iloc[issues_data['comments'].nlargest(10).index][['title', 'comments']]

这是排名前10的讨论。可见,该项目火到已经开始要出电脑壁纸周边了。
# 大家都在讨论什么东西呢?
import jieba
from collections import Counter
from pyecharts import WordCloud
jieba.add_word('996')
jieba.add_word('996制度')
jieba.add_word('ICU')
swords = [x.strip() for x in open ('stopwords.txt',encoding="UTF-8")]
def plot_word_cloud(data, swords):
text = ''.join(data['title'])
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in swords):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[20, 100])
return wordcloud
plot_word_cloud(issues_data, swords=swords)
我们把这些评论做成了词云图

可见,996赫然以最大字号出现在图中,来自全国各地的程序员,有些专场来支持,有些只是围观,有些在火钳刘明。但是大家都有一个共识:抵制996,别让自己进了ICU。
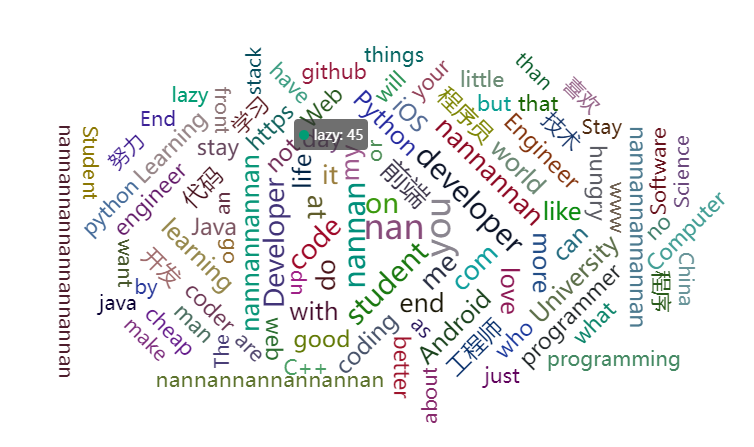
- 3.5 关注996的程序员的简介词云图
def plot_word_cloud(data, swords):
text = ''.join(data['bio'].astype('str'))
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in swords):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[20, 100])
return wordcloud
swords.extend(['the', 'is', 'and', 'of', 'be', 'to', 'in', 'for', 'from', 'am'])
plot_word_cloud(user_data, swords=swords)
最后,我们把这些程序员的Github简介做成了词云图,看看这些程序员都是何方神圣。
四、完整代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pymongo import MongoClient
from pandas.io.json import json_normalize
plt.style.use('ggplot')
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题
plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点
plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
%matplotlib inline
conn = MongoClient(host='127.0.0.1', port=27017) # 实例化MongoClient
db = conn.get_database('Github996') # 连接到Github996数据库
users = db.get_collection('users')
data = users.find() # 查询这个集合下的所有记录
user_data = json_normalize([record for record in data])
issues = db.get_collection('issues')
data = issues.find() # 查询这个集合下的所有记录
issues_data = json_normalize([record for record in data])
user_data.info()
user_data.to_csv('users_data.csv', index=False)
issues_data.to_csv('issues_data.csv', index=False)
### 1. User数据清洗
user_data.sample(5)
user_data.iloc[666]
user_data.columns
# 先去除对于分析无用的字段
user_data.drop(columns = ['_id', 'avatar_url', 'events_url', 'followers_url', 'following_url',
'gists_url', 'gravatar_id', 'html_url', 'node_id', 'public_gists',
'received_events_url', 'repos_url', 'site_admin', 'starred_url',
'subscriptions_url', 'type'],
inplace = True)
user_data.info()
# 时间类型转换
user_data['created_at'] = pd.to_datetime(user_data['created_at'])
user_data['updated_at'] = pd.to_datetime(user_data['updated_at'])
### 2. Issues数据清洗
issues_data.info()
issues_data.sample(5)
issues_data.iloc[888]
# 由于字段太多,直接抽取想要的字段
issues_data = issues_data[['comments', 'id', 'title', 'updated_at', 'user.id']]
issues_data.info()
# 时间类型转换
issues_data['updated_at'] = pd.to_datetime(issues_data['updated_at'])
### 3. 问题
User_data拥有的字段:用户简介、博客、所在单位、账号创建时间、email、关注者数、被关注者数、是否能雇用、ID、所在地址、名字、组织url、公开repos数、更新时间等
Issues_data拥有的字段:issue评论数、ID、issue题目、更新时间、提问者ID
- 3.1 关注996的程序员,都来自于哪些单位?
- 3.2 关注996的程序员,都来自于哪些城市?
- 3.3 关注996的程序员的画像
- 3.4 大家所关注的问题都有哪些?
- 3.5 关注996的程序员的简介词云图
#### 3.1 关注996的程序员,都来自于哪些单位?
user_data.info()
# 单位字段太乱了!先把爬名前50的提出来
user_data['company'].value_counts()[:50]
user_data['company'].value_counts()[:100].index
def get_company(data):
for com in ['encent', '腾讯']:
if com in data:
return '腾讯'
for com1 in ['aidu', '百度']:
if com1 in data:
return '百度'
for com2 in ['libaba', '淘宝', 'aobao', 'lipay', '阿里巴巴', 'liyun', '阿里云']:
if com2 in data:
return '阿里系'
for com3 in ['JD', 'jd', '京东']:
if com3 in data:
return '京东'
for com4 in ['etease', 'etEase', '网易']:
if com4 in data:
return '网易'
for com5 in ['eituan', '美团']:
if com5 in data:
return '美团'
for com6 in ['ytedance', '字节', '头条']:
if com6 in data:
return '头条'
for com7 in ['eleme', '饿了么']:
if com7 in data:
return '饿了么'
for com8 in ['uawei', '华为']:
if com8 in data:
return '华为'
for com9 in['didi', 'DiDi', '滴滴', '嘀嘀']:
if com9 in data:
return '滴滴'
user_data['company_top'] = user_data.loc[user_data['company'].notna(), 'company'].apply(get_company)
top10_com = user_data['company_top'].value_counts()
from pyecharts import Bar
bar = Bar("关注996工作制的程序员所在公司Top10", width = 700,height=500)
bar.add("", top10_com.index, top10_com.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True,
xaxis_rotate=30)
bar
def get_uni(data):
for uni in ['hejiang', 'ZJU', 'zju', '浙江大学', '浙大']:
if uni in data:
return '浙大'
for uni2 in ['singhua', '清华大学']:
if uni2 in data:
return '清华'
for uni3 in ['Shanghai Jiao Tong', 'SJTU', '上海交大', '上海交通大学']:
if uni3 in data:
return '上海交大'
for uni4 in ['UESTC', '电子科大', '电子科技大学']:
if uni4 in data:
return '电子科大'
for uni5 in ['Wuhan', '武大', '武汉大学']:
if uni5 in data:
return '武大'
for uni6 in ['USTC', '中科大', '中国科学技术大学']:
if uni6 in data:
return '中科大'
for uni7 in ['Fudan', '复旦']:
if uni7 in data:
return '复旦'
for uni8 in ['arbin', '哈']:
if uni8 in data:
return '哈工大'
for uni9 in ['BUPT', '北邮', '北京邮电']:
if uni9 in data:
return '北邮'
user_data['uni_top'] = user_data.loc[user_data['company'].notna(), 'company'].apply(get_uni)
top10_uni = user_data['uni_top'].value_counts()
bar = Bar("关注996工作制的程序员所在大学Top10", width = 700,height=500)
bar.add("", top10_uni.index, top10_uni.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True,
xaxis_rotate=30)
bar
#### 3.2 关注996的程序员,都来自于哪些城市?
user_data['location'].value_counts()[:50]
user_data['location'].value_counts()[:50].index
def get_city(data):
for city in ['eijing', '北京']:
if city in data:
return '北京'
for city1 in ['hanghai', '上海']:
if city1 in data:
return '上海'
for city2 in ['Hangzhou', 'hangzhou', '杭州']:
if city2 in data:
return '杭州'
for city3 in ['henzhen', '深圳']:
if city3 in data:
return '深圳'
for city4 in ['Guangzhou', 'guangzhou', '广州']:
if city4 in data:
return '广州'
for city5 in ['hengdu', '成都']:
if city5 in data:
return '成都'
for city6 in ['anjing', '南京']:
if city6 in data:
return '南京'
for city7 in ['ingapore', '新加坡']:
if city7 in data:
return '新加坡'
for city8 in ['Hong Kong', 'hong kong', '香港']:
if city8 in data:
return '香港'
for city9 in ['uhan', '武汉']:
if city9 in data:
return '武汉'
user_data['city_top'] = user_data.loc[user_data['location'].notna(), 'location'].apply(get_city)
top10_city = user_data['city_top'].value_counts()
bar = Bar("关注996工作制的程序员所在城市Top10", width = 700,height=500)
bar.add("", top10_city.index, top10_city.values, is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True,
xaxis_rotate=30)
bar
#### 3.3 关注996的程序员的画像
user_data.info()
# 关注996工作制的程序员Github平均粉丝数、关注数、仓库数
user_mean = user_data[['followers', 'following', 'public_repos']].mean()
bar = Bar("关注996工作制的程序员Github平均粉丝数、关注数、仓库数", width = 500,height=500)
bar.add("", ['粉丝数', '关注数', '仓库数'], np.round(user_mean.values, 1), is_stack=True,
xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True)
bar
# 关注996工作制的程序员Github粉丝数分布图
sns.set(font_scale=1.5)
sns.distplot(user_data.loc[user_data['followers'] < 50, 'followers'], kde=False)
# 关注996工作制的程序员注册Github时长
user_data['time'] = pd.to_datetime('2019-03-28')- user_data['created_at']
user_data['time'].mean()
# 平均注册市场3.2年
1180/365
def get_days(data):
return data.days
user_data['time_days'] = user_data['time'].apply(get_days)/365
# 关注996工作制的程序员注册Github时长分布图
sns.set(font_scale=1.5)
ax = sns.distplot(user_data['time_days'], kde=False)
ax.set_xlabel('Year')
# 关注996工作制的程序员大牛
user_data.loc[user_data['followers'] > 3000, ['login', 'followers','url', 'bio']]
user_data[user_data['followers'] > 1000].shape[0]
user_data[user_data['followers'] > 500].shape[0]
user_data[user_data['followers'] > 100].shape[0]
#### 3.4 大家所关注的问题都有哪些?
issues_data.info()
issues_data.iloc[issues_data['comments'].nlargest(10).index][['title', 'comments']]
# 大家都在讨论什么东西呢?
import jieba
from collections import Counter
from pyecharts import WordCloud
jieba.add_word('996')
jieba.add_word('996制度')
jieba.add_word('ICU')
swords = [x.strip() for x in open ('stopwords.txt')]
def plot_word_cloud(data, swords):
text = ''.join(data['title'])
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in swords):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[20, 100])
return wordcloud
plot_word_cloud(issues_data, swords=swords)
#### 3.5 关注996的程序员简介词云图
def plot_word_cloud(data, swords):
text = ''.join(data['bio'].astype('str'))
words = list(jieba.cut(text))
ex_sw_words = []
for word in words:
if len(word)>1 and (word not in swords):
ex_sw_words.append(word)
c = Counter()
c = Counter(ex_sw_words)
wc_data = pd.DataFrame({'word':list(c.keys()), 'counts':list(c.values())}).sort_values(by='counts', ascending=False).head(100)
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", wc_data['word'], wc_data['counts'], word_size_range=[20, 100])
return wordcloud
swords.extend(['the', 'is', 'and', 'of', 'be', 'to', 'in', 'for', 'from', 'am'])
plot_word_cloud(user_data, swords=swords)
总结
1.通过数据的分析,可以更客观的看待996这件事。当前,996工作制度在社会具有一定的认可度,这是由一些客观原因造成的:首先,我们是发展中国家,追赶超确实需要我们更加勤奋,更加奋斗。尤其是在高科技行业996工作制蔚然成风。但从另一个角度来说,如果把996工作制赋上文化道德色彩,认为不加班就是不奋斗,就是给996披上了道德的外衣。它的本质是违法与不违法的问题。
因此,我不支持996工作制:从法律层面来说,《劳动法》明确规定,劳动者一周工作40小时,最多不超过44小时。而且企业需要劳动者加班,必须事先通知或沟通。996大行其道,一定程度说明《劳动法》在社会的执行上存在着漏洞;同时,劳动者虽然知道《劳动法》规定了自己的权利,但不敢用法律维护自己的权益。这是因为劳动者担心如果维护了权益,就丢失了工作。当然,政府在执法监管中也是薄弱环节,无法给劳动者提供切实有效的保护。
我认为,企业要快速发展,不一定建立在拼命加班的基础上,而可以通过各种技术手段,提高工作效率。
2.项目完善过程中,我掌握了pandas对数据分析的操作,如何优雅的处理各种数据,利用一些可视化库进行呈现并得到我们想要知道的结论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号