rtthread的spinlock源码分析
spinlock
spinlock是死等的锁机制,自旋锁有以下几个特点:
-
在获取不到锁的时候会自旋等待锁释放,只能有一个进程或者线程能持有自旋锁。
-
可以在没有获得锁的时候,进入低功耗模式,等待锁释放后被唤醒。
-
由于spinlock不会睡眠让出CPU控制权,因此可以在中断上下文中使用。
进程上下文
当打开 premptive 选项后,事情变得复杂了,我们考虑下面的场景:
- 进程 A 在某个系统调用过程中访问了共享资源 R
- 进程 B 在某个系统调用过程中也访问了共享资源 R
1. 会不会造成冲突呢?
假设在 A 访问共享资源 R 的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的 B,在中断返回现场的时候,发生进程切换,B 启动执行,并通过系统调用访问了 R,如果没有锁保护,则会出现两个 thread 进入临界区,导致程序执行不正确。
2. 使用 spin lock:
A 在进入临界区之前获取了 spin lock,同样的,在 A 访问共享资源 R 的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的 B,B 在访问临界区之前仍然会试图获取 spin lock,这时候由于 A 进程持有 spin lock 而导致 B 进程进入了永久的 spin…… 怎么破?linux 的 kernel 很简单,在 A 进程获取 spin lock 的时候,禁止本 CPU 上的抢占(上面的永久 spin 的场合仅仅在本 CPU 的进程抢占本 CPU 的当前进程这样的场景中发生)。
如果是多核 CPU,A 和 B 运行在不同的 CPU 上,那么情况会简单一些:A 进程虽然持有 spin lock 而导致 B 进程进入 spin 状态,不过由于运行在不同的 CPU 上,A 进程会持续执行并会很快释放 spin lock,解除 B 进程的 spin 状态。
中断上下文
- 运行在 CPU0 上的进程 A 在某个系统调用过程中访问了共享资源 R
- 运行在 CPU1 上的进程 B 在某个系统调用过程中也访问了共享资源 R
- 外设 P 的中断 handler 中也会访问共享资源 R
在这样的场景下,使用 spin lock 可以保护访问共享资源 R 的临界区吗?我们假设 CPU0 上的进程 A 持有 spin lock 进入临界区,这时候,外设 P 发生了中断事件,并且调度到了 CPU1 上执行,看起来没有什么问题,执行在 CPU1 上的 handler 会稍微等待一会 CPU0 上的进程 A,等它立刻临界区就会释放 spin lock 的.
但是,如果外设 P 的中断事件被调度到了 CPU0 上执行会怎么样?CPU0 上的进程 A 在持有 spin lock 的状态下被中断上下文抢占,而抢占它的 CPU0 上的 handler 在进入临界区之前仍然会试图获取 spin lock,悲剧发生了,CPU0 上的 P 外设的中断 handler 永远的进入 spin 状态,这时候,CPU1 上的进程 B 也不可避免在试图持有 spin lock 的时候失败而导致进入 spin 状态。
为了解决这样的问题,linux kernel 采用了这样的办法:如果涉及到中断上下文的访问,spin lock 需要和禁止本 CPU 上的中断联合使用。
所以自旋锁禁止抢占以及关闭本地中断。禁止抢占优先级高的无法抢占,所以要等待临界区代码执行完成打开抢占。如果在中断上下文则需要关闭本地中断是为不让本核响应中断,因为可能中断中可能会去抢自旋锁,导致死锁。
具体参考Linux内核同步机制【spin lock】 | Winddoing's Notes
二、spinlock的实现
本文记录的是基于ticket的自旋锁的实现。基于ticket的自旋锁就是为了能更加不同的线程或进程能够更加公平地获取到锁。举个例子,当我们去银行办理业务的时候,总是会需要先取个号,然后叫到号之后才能去柜台办理业务。基于ticket的自旋锁也是同样的原理。
typedef struct {
union {
u32 slock;
struct __raw_tickets {
u16 owner; // 当前处理的票号
u16 next; // 下一个处理的票号
} tickets;
};
} arch_spinlock_t
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->sloc); //预取指令,向将lock->slock取到cash缓存,以提高读写速度
__asm__ __volatile__(
"1: ldrex %0, [%3]\n" // 将lock->slock的值赋值给lockval
" add %1, %0, %4\n" // newval = lockval + (1 << TICKET_SHIFT)
" strex %2, %1, [%3]\n" // 将newval存储回lock->slock,并将存储结果存储在tmp中
" teq %2, #0\n" // 检查strex的存储结果是否为0
" bne 1b" // 如果不为0,则跳转到标签1处,重新执行ldrex和strex指令
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) { //如果不相等表示锁还未解开,
wfe(); //WFE指令,让cpu进入休眠,解锁的线程会用sev指令唤醒cpu
lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner); //其它线程已经用完临界资源解锁,调用sev指令唤醒该cpu,还要需要重新去加载lock的owner值
}
smp_mb(); //设置内存屏障
}
arch_spin_lock的汇编代码相当于取号,然后在while循环中等待下一个号是不是自己,如果不是会进入while循环等待。wfe()是arm的低功耗指令,处理器会进入休眠状态,并且无法进行线程和进程调度,等待被唤醒。
三、ldrex和strex底层实现
这里使用的是arm的ldrex和strex实现原子指令。对于这两个指令的底层原理如下:
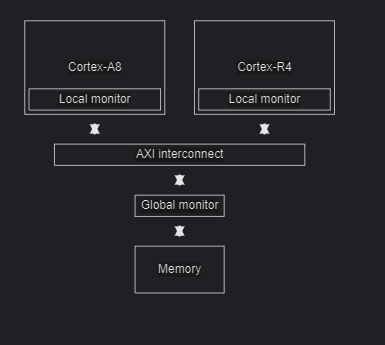
在物理硬件上每个核上会有个local monitor,然后会有个global monitor。通过这两个monitor可以实现原子指令。local monitor监控的是非共享的内存,而global monitor监控的共享的内存。对于非共享内存只需要检查local monitor,访问共享内存不仅需要检查local monitor还会检查global monitor。
对于本地监视器来说,它只标记了本处理器对某段内存的独占访问,在调用LDREX指令时设置独占访问标志,在调用STREX指令时清除独占访问标志。
而对于全局监视器来说,它可以标记每个处理器对某段内存的独占访问。也就是说,当一个处理器调用LDREX访问某段共享内存时,全局监视器只会设置针对该处理器的独占访问标记,不会影响到其它的处理器。当在以下两种情况下,会清除某个处理器的独占访问标记:
1)当该处理器调用LDREX指令,申请独占访问另一段内存时;
2)当别的处理器成功更新了该段独占访问内存值时。
对于第二种情况,也就是说,当独占内存访问内存的值在任何情况下,被任何一个处理器更改过之后,所有申请独占该段内存的处理器的独占标记都会被清空。

大致经历的步骤如下:
1)CPU2上的线程3最早执行LDREX,锁定某段共享内存区域。它会相应更新本地监视器和全局监视器。
2)然后,CPU1上的线程1执行LDREX,它也会更新本地监视器和全局监视器。这时在全局监视器上,CPU1和CPU2都对该段内存做了独占标记。
3)接着,CPU1上的线程2执行LDREX指令,它会发现本处理器的本地监视器对该段内存有了独占标记,同时全局监视器上CPU1也对该段内存做了独占标记,但这并不会影响这条指令的操作。
4)再下来,CPU1上的线程1最先执行了STREX指令,尝试更新该段内存的值。它会发现本地监视器对该段内存是有独占标记的,而全局监视器上CPU1也有该段内存的独占标记,则更新内存值成功。同时,清除本地监视器对该段内存的独占标记,还有全局监视器所有处理器对该段内存的独占标记。
5)下面,CPU2上的线程3执行STREX指令,也想更新该段内存值。它会发现本地监视器拥有对该段内存的独占标记,但是在全局监视器上CPU1没有了该段内存的独占标记(前面一步清空了),则更新不成功。
6)最后,CPU1上的线程2执行STREX指令,试着更新该段内存值。它会发现本地监视器已经没有了对该段内存的独占标记(第4步清除了),则直接更新失败,不需要再查全局监视器了
具体参考该ARM平台下独占访问指令LDREX和STREX的原理与使用详解-CSDN博客。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号