搜索引擎ElasticSearch系列(一): ElasticSearch2.4.4环境搭建
一:ElasticSearch简介
Elasticsearch is a distributed, RESTful search and analytics engine capable of solving a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data so you can discover the expected and uncover the unexpected.
elasticsearch 是一个可伸缩,开源的全文搜索引擎。你可以使用它接近实时地储存,搜索,快速分析大规模的数据。它通常被用作底层的引擎或技术,加强一些具有复杂的搜索特性和需求的应用程序。
下面列举一些简单的elasticsearch的使用案列:
- 你运行一个网店,并允许顾客搜索你售卖的产品。对于这种情况,你可以elasticsearch储存你所有的产品目录和库存,并提供搜索和自动补全关键字的功能。
- 你想收集日志或者事务数据,然后对其进行趋势分析,数据发掘,统计,汇总和异常分析。对于这种情况,你可以使用Logstash(es 栈的一部分)去收集,聚合,解析你的数据。然后使用Logstatsh把这些数据填充到elasticsearch中。一旦数据同步到elasticsearch,你就可以进行查询和聚合操作,以发掘你感兴趣的信息。
- 你运行一个价格警报平台,它允许顾客指定一条规则:我对某个电子产品感兴趣,如果下个月内,有摊贩报价低于x元,就希望平台可以通知我。这种情况,你可以收集摊贩的售卖价格,然后把这些数据推送到elasticsearch,并利用它的反向搜索能力(过滤器,即词=》文档,而不是文档=》词,Percolator,过滤器),针对顾客的查询,匹配价格的变动,一旦满足顾客的要求,就通知客户。
- 你有一些商业情报需要快速研究,分析,可视化和在大量(百万或十亿个记录)的数据中查找一个特定的问题。在这个例子,你可以使用elasticsearch去储存你的数据,然后使用 Kibana(es栈的一部分,一个可视化的用于分析数据的web程序)去定制报表,把那些你觉得很重要的数据以可视化的方式展现出来。另外,你还可以使用elasticsearch的聚合函数去执行复杂的商业情报查询。
在本教程的剩余部分,我会通过elasticsearch的启动和运行过程指导你初步认识它,并执行一些基本的操作,例如:索引,搜索,和修改你的数据。在教程的结束后,你将会对:1.elasticsearch是什么,2.它是如何工作的,有一个很清晰的概念。希望你能受到启发,并知道如何使用它去建立一个复杂的搜索程序或者从你的数据中发掘一些情报。
基本概念(Basic Concepts)
下面介绍一些elasticsearch的核心概念。从一开始就理解这些概念对你的学习过程十分有帮助。
接近实时(Near Realtime ,NRT)
elasticsearch 是一个接近实时的搜索平台。这意味着从索引一个文档到这个文档可以被搜索的过程,仅有轻微的延迟(正常情况是一秒)
集群(cluster)
集群是一个或多个节点(服务器)的集合,它们联合起来保存所有的数据(索引以分片为单位分散到多个节点上保存)并且可以在所有的节点上进行索引和搜索操作。集群通过一个唯一的名字区分,默认的名字是“elasticsearch”。这个名字十分重要,因为一个节点仅仅可以属于一个集群,并根据集群名称加入集群。
确保你不要在不同的环境中使用一样的集群名字,否则你最终有可能加入了错误的集群(例如生产环境的节点错误加入了开发环境的集群)。例如,你可以分别在开发,过渡,生产环境中使用集群名称 logging-dev,logging-stage和logging-prod。
注意,集群也可以仅拥有一个节点。此外,你也可以开启多个独立的集群,他们都有自己唯一的集群名称。
节点(node)
节点是一个服务器,也是集群的一部分,它存储你的数据,并参与集群的索引和搜索。和集群一样,节点也是通过唯一的名字去区分,默认名字是一个随机的UUID,当服务器启动的时候就会设置到节点。你也可以自定义节点的名称。名称对管理员来说十分重要,它可以帮助你辨认出集群中的各个服务器和哪个节点相对应。
节点通过配置集群的名称,就可以加入到集群中。默认,节点都加入一个叫elasticsearch的集群,这意味着如果你在网络中启动了大量的节点并且假如他们都能互相通讯的话,那么他们将会被自动的加入一个名字叫elasticsearch的集群。
索引(index)
索引是很多文档的集合,这些文档都具备一些相似的特征。例如,你可以分别创建客户,产品目录和其他数据的索引。索引是通过名字(必须是小写的)区分的,当执行索引,搜索,更新和删除操作时,这个名字将会被用来引用实际的索引。
类型(Type)
你可以在索引中定义一个或多个类型。类型是索引的一个逻辑分类或划分,它的概念完全取决于你自己如何去理解。通常,类型是为一些具备公共字段的文档定义的。例如,假想你在运行一个博客平台,并且把其全部的数据都存储索引中。你可以在索引中定义一个用于保存用户数据的类型,另一个用于保存博客数据的类型,还有一个用于保存评论数据的类型。
文档(document)
文档是可以被索引的基本单位。例如,你可以用一个文档保存单个客户的数据,另一个文档保存单个产品的数据,还有一个文档保存单个订单的数据。文档使用一种互联网广泛存在的数据交换格式保存-JSON。
你可以在索引/类型中存储大量你想存储的数据。值得注意的是,尽管文档本质上是存放在索引中,但实际上是被索引到索引中的一个类型中。
分片和复制(shards & replicas)
一个索引存储的数据有可能超过单个节点硬盘容量。例如,索引10亿个的文档可能占用1TB的硬盘空间,单个节点的硬盘有可能不足以存储那么大的数据量,或者在单个节点保存大量的索引会降低服务器处理搜索请求的速度。
为了解决这个问题,elasticsearch 可以让你把索引数据划分到多个分片上。当你创建一个索引,你可以简单的定义你想要的分片数量。每个分片本身就具备索引的全部功能,可以存放在集群中的任何一个节点。
分片的主要是为了以下两个目的:
- 它允许你水平划分/扩展你的内容
- 它允许你并行地分发操作到多个节点的分片上,从而可以提升性能或吞吐量。
分片如何分发以及各分片上的文档如何被收集到单个搜索请求中的机制是由elasticsearh完全管理的,这个过程对用户是透明的(用户不需要关心这个机制的过程)
在网络或云环境中,任何时候都可能发生错误。推荐建立容错机制,处理分片或节点宕机或因为某种原因消失在网络上的情况。这样可以非常有效地降低风险。为此,elasticsearch允许你创建一个或者多个分片的副本,我们把这个副本叫做复制分片,简称复制。
复制分片主要是为了以下两个目的:
- 它提供了高可用性,以防节点/分片不可以用。因此,注意不要把复制分片和主分片放在同一个节点上。
- 它允许你扩大搜索量和吞吐量,因为不同的搜索请求可以在所有的复制分片中并发执行。
总的来说,索引可以划分在多个分片上。索引也可以被复制0次(也就是说没有复制)或多次。一旦索引被复制,会有一个主分片(被复制的原始分片)和复制分片(主分片的副本)。复制分片的数量可以在创建索引的时候定义。索引被创建后,你可以动态地改变复制分片的数量,但你不能改变原始分片的数量。
默认情况下,每个索引都会被分配5个主分片和1一个复制分片,这意味着如果你的集群中有两个节点,你的索引将会有5个主分片和5个复制分片,总共有10个分片。
每个elasticsaerch分片都是一个Lucene 索引。在单个索引中你最多可以存储2,147,483,519 (= Integer.MAX_VALUE - 128) 个文档。你可以使用 _cat/shards api去监控分片的的大小。
二:ElasticSearch下载安装
下载地址:https://www.elastic.co/downloads/past-releases 如下图所示,下载2.4.4版本
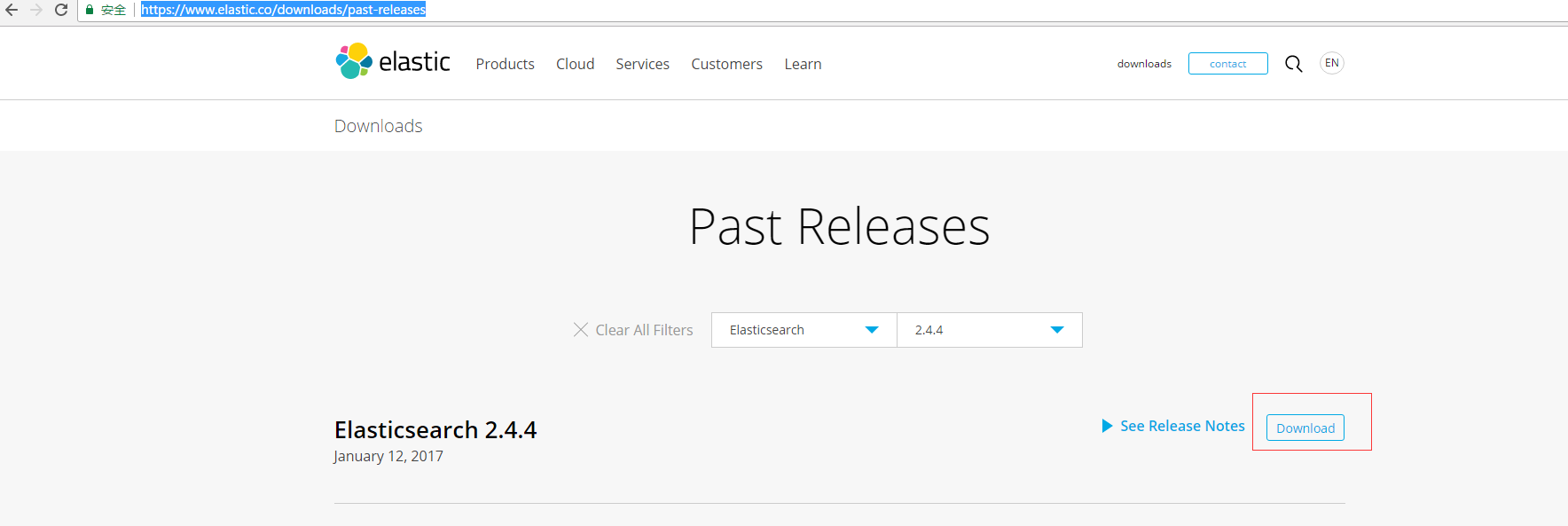
点击Download按钮进入下载链接下载。
三:ElasticSearch运行
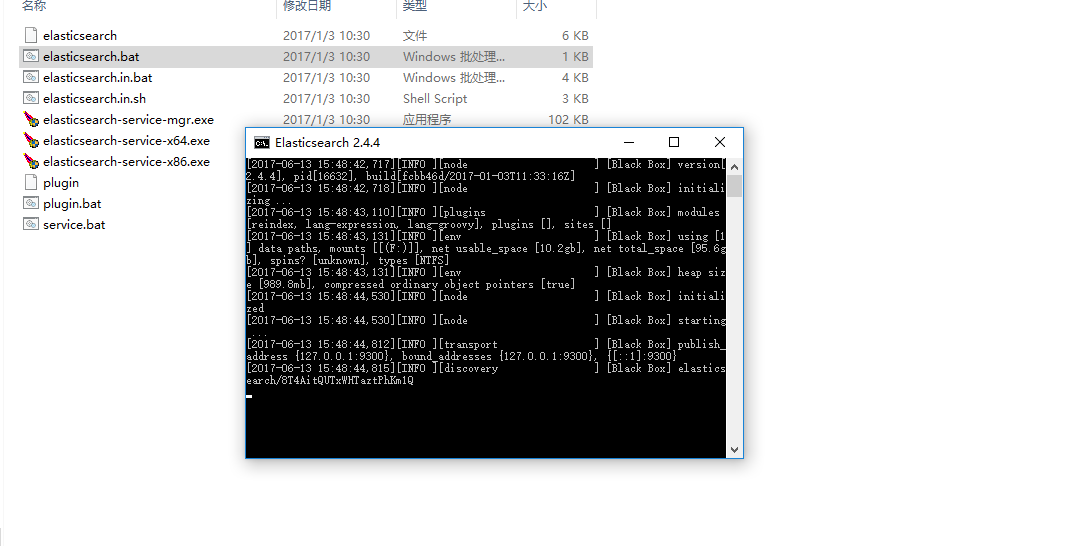
解压elasticsearch-2.4.4.zip,运行bin下面的elasticsearch.bat,如下如所示:

点击运行elasticsearch.bat,会出现一下控制台窗口:
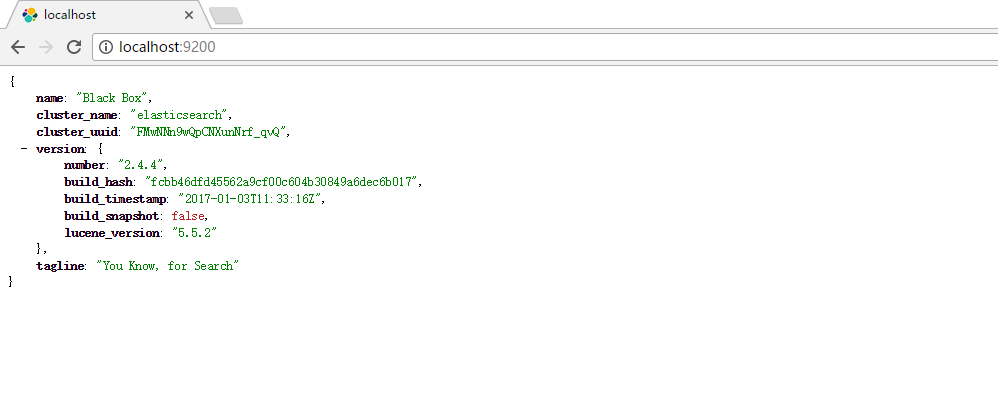
此时我们在浏览器中输入: http://localhost:9200/ 会出现一下界面说明ElasticSearch启动成功:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号