
ELK日志搜索之Elasticsearch 5.6版本安装教程
摘要
ELK Stack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELK Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
ELKStack简介
ELK Stack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELK Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
• 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
• 配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
• 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
• 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
• 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
ELK地址:https://www.elastic.co/
Logstash 最佳实践:http://udn.yyuap.com/doc/logstash-best-practice-cn/index.html
Elasticsearch 权威指南:http://www.learnes.net/index.html
ELKStack中文社区:https://kibana.logstash.es/content/
Elasticsearch部署
Elasticsearch首先需要Java环境,所以需要提前安装好JDK,可以直接使用yum安装。也可以从Oracle官网下载JDK进行安装。开始之前要确保JDK正常安装并且环境变量也配置正确:
[root@localhost ~]# df -h 文件系统 容量 已用 可用 已用% 挂载点 /dev/mapper/centos-root 17G 3.4G 14G 20% / devtmpfs 902M 0 902M 0% /dev tmpfs 912M 0 912M 0% /dev/shm tmpfs 912M 8.7M 904M 1% /run tmpfs 912M 0 912M 0% /sys/fs/cgroup /dev/sda1 1014M 189M 826M 19% /boot tmpfs 183M 0 183M 0% /run/user/0 [root@localhost ~]# free -m total used free shared buff/cache available Mem: 1823 407 1092 8 323 1224 Swap: 2047 0 2047 [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.4.1708 (Core)
安装JDK
[root@localhost ~]# yum install -y java [root@localhost ~]# java -version openjdk version "1.8.0_171" OpenJDK Runtime Environment (build 1.8.0_171-b10) OpenJDK 64-Bit Server VM (build 25.171-b10, mixed mode)
配置安装ElasticSearch
可以使用源码,或者yum
一、yum安装
1.下载并安装GPG key [root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch 2.添加yum仓库 [root@linux-node1 ~]# cat /etc/yum.repos.d/elasticsearch.repo [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 3.安装elasticsearch [root@hadoop-node1 ~]# yum install -y elasticsearch
二、源码安装
[root@localhost tmp]# wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.1/elasticsearch-2.3.1.tar.gz [root@localhost tmp]# tar xf elasticsearch-5.6.2.tar.gz -C /usr/local/ [root@localhost tmp]# cd /usr/local/
三、配置elasticsearch
[root@localhost local]# vim elasticsearch-5.6.2/config/elasticsearch.yml cluster.name: my-es #ES集群名称 node.name: node-1 #节点名称 path.data: /data/es-date #数据存储的目录(多个目录使用逗号分隔) path.logs: /var/log/elasticsearch #日志格式 bootstrap.memory_lock: true #锁住es内存,保证内存不分配至交换分区 network.host: 192.168.5.8 #设置本机IP地址 http.port: 9200 #端口默认9200 # 以下是防止脑裂配置部分 discovery.zen.ping.multicast.enabled: false discovery.zen.ping_timeout: 120s client.transport.ping_timeout: 60s discovery.zen.ping.unicast.hosts: ["192.168.5.8","192.168.5.12","192.168.5.20"]
四、设置目录权限
[root@localhost local]# useradd essh [root@localhost local]# chown -R essh.essh elasticsearch-5.6.2
五、启动异常情况解决
max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536] #vim /etc/security/limits.conf * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#vi /etc/sysctl.conf
vm.max_map_count=655360 #添加此节点
#sysctl -p
或者执行以下命令
[root@localhost elasticsearch-5.6.2]# sysctl -w vm.max_map_count=655360
本地无法连接,或建立集群失败
[root@localhost elasticsearch-5.6.2]# firewall-cmd --zone=public --add-port=9200/tcp --permanent
[root@localhost elasticsearch-5.6.2]# firewall-cmd --zone=public --add-port=9300/tcp --permanent
[root@localhost elasticsearch-5.6.2]# firewall-cmd --reload
本次环境我们使用3台服务器,这3台服务器的服务搭建可以跟上面的步骤相同即可
[2018-05-12T11:56:44,053][INFO ][o.e.c.s.ClusterService ] [node-3] new_master {node-3}{6VQyU09JRSWdmsZwzoE4VA}{vcb8KHoqTqe44MjOMjkCNQ}{192.168.5.12}{192.168.5.12:9300}, added {{node-1}{KPOE3xR6R-yLaiAtZCStjA}{dp_ZF58RSFCLequPipcgHg}{192.168.5.8}{192.168.5.8:9300},{node-2}{jLXhIqaDTima7Gs0Hu9ZQw}{Ks38BUuCQH2QrXf6w82eUA}{192.168.5.20}{192.168.5.20:9300},}, reason: zen-disco-elected-as-master ([2] nodes joined)[{node-1}{KPOE3xR6R-yLaiAtZCStjA}{dp_ZF58RSFCLequPipcgHg}{192.168.5.8}{192.168.5.8:9300}, {node-2}{jLXhIqaDTima7Gs0Hu9ZQw}{Ks38BUuCQH2QrXf6w82eUA}{192.168.5.20}{192.168.5.20:9300}]
[2018-05-12T11:56:44,794][INFO ][o.e.h.n.Netty4HttpServerTransport] [node-3] publish_address {192.168.5.12:9200}, bound_addresses {192.168.5.12:9200}
[2018-05-12T11:56:44,344][INFO ][o.e.c.s.ClusterService ] [node-2] detected_master {node-3}{6VQyU09JRSWdmsZwzoE4VA}{vcb8KHoqTqe44MjOMjkCNQ}{192.168.5.12}{192.168.5.12:9300}, added {{node-1}{KPOE3xR6R-yLaiAtZCStjA}{dp_ZF58RSFCLequPipcgHg}{192.168.5.8}{192.168.5.8:9300},{node-3}{6VQyU09JRSWdmsZwzoE4VA}{vcb8KHoqTqe44MjOMjkCNQ}{192.168.5.12}{192.168.5.12:9300},}, reason: zen-disco-receive(from master [master {node-3}{6VQyU09JRSWdmsZwzoE4VA}{vcb8KHoqTqe44MjOMjkCNQ}{192.168.5.12}{192.168.5.12:9300} committed version [1]])
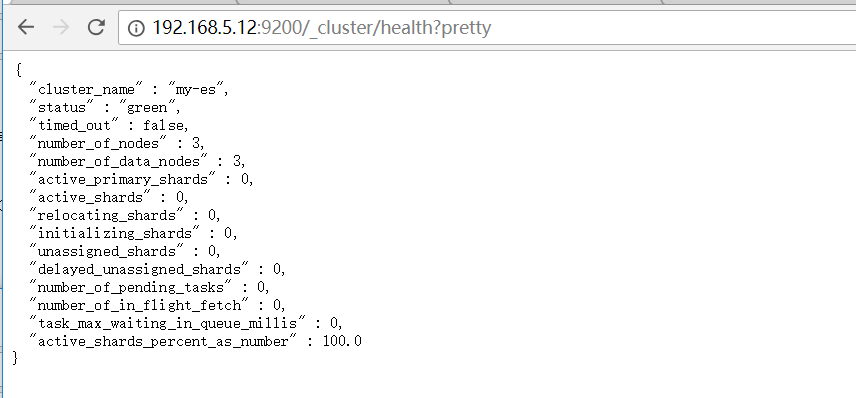
此时我们可以在浏览器查看集群状态
http://192.168.5.8:9200/_cluster/health?pretty
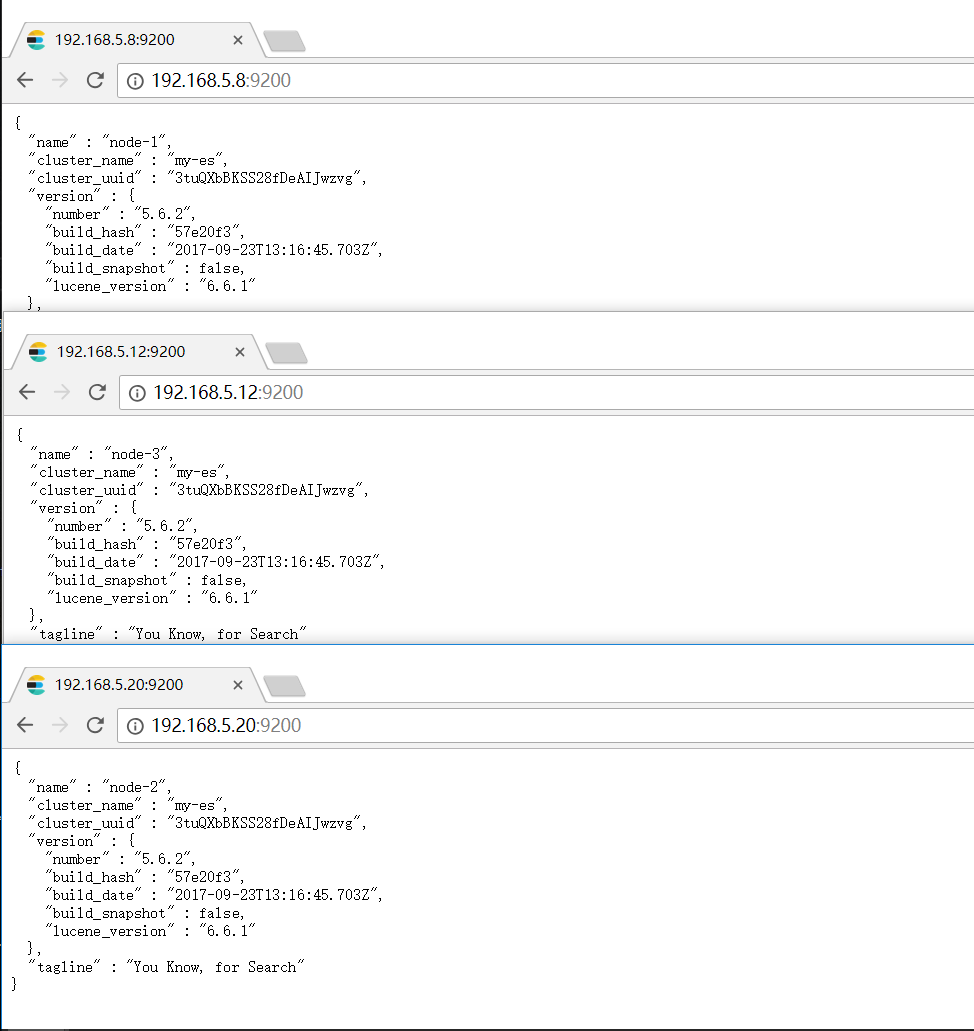
以下是各个节点信息
使用curl进行通讯
[root@localhost ~]# curl -i -XGET 'http://192.168.5.8:9200/_count?' HTTP/1.1 200 OK content-type: application/json; charset=UTF-8 content-length: 71 {"count":0,"_shards":{"total":0,"successful":0,"skipped":0,"failed":0}}[root@localhost ~]#
常用命令
[root@localhost ~]# ps aux | grep java [root@localhost ~]# netstat -nlpt [root@localhost ~]# scp elasticsearch-5.6.2.tar.gz root@192.168.5.20:/tmp/
Elasticsearch插件介绍
一、Haed插件
插件作用:主要是做es集群管理的插件
Github下载地址:https://github.com/mobz/elasticsearch-head
Elasticsearch高版本安装head相当方法,以下安装过程仅供参考 [root@localhost tmp]# yum -y install git [root@localhost tmp]# git clone https://github.com/mobz/elasticsearch-head.git #下载head插件 [root@localhost tmp]# wget https://nodejs.org/dist/v4.6.1/node-v4.6.1-linux-x64.tar.gz #下载nodejs [root@localhost tmp]# tar zxvf node-v4.6.1-linux-x64.tar.gz #解压 [root@localhost tmp]# vim /etc/profile #添加环境变量 export PATH=/tmp/node-v4.6.1-linux-x64/bin:$PATH [root@localhost tmp]# source /etc/profile #使环境变量生效 查看当前head插件目录下有无node_modules/grunt目录: [root@localhost elasticsearch-head]# npm install grunt --sava #没有的情况下执行 [root@localhost elasticsearch-head]# npm install #安装 执行失败或者 [root@localhost elasticsearch-head]# npm install -g cnpm --registry=https://registry.npm.taobao.org #或者安装 [root@localhost elasticsearch-head]# npm install -g grunt-cli #安装grunt [root@localhost elasticsearch-head]# vim Gruntfile.js #编辑 Gruntfile.js 文件93行options下添加hostname:'0.0.0.0' 检测head根目录下是否存在base文件夹,没有:将_site下的base文件夹及内容复制到head根目录下 [root@localhost elasticsearch-head]# cd _site/ [root@localhost _site]# cp -r base/ ../ #拷贝到上层目录 [root@localhost elasticsearch-head]# grunt server -d #启动grunt
1.访问Elastic 官网 ,https://www.elastic.co/cn/ 2.痛点:线上程序出错,日志没法及时拿到,总是找运维去帮我拿日志,分布式程序日志又分散到不同机器,拿日志也是比较麻烦,而且开发找日志,也是不易检索到自己想要的日志,不能及时定位报错日志的关键位置,导致开发解决问题不及时。 3.运维不能把权限给到开发,Log4Net只能把日志写到本地。之前有做过,Log4Net To Mongodb ,但是不是特别好用。 5 运维/开发人员问运维经常要日志, 6 为什么要使用ELK, 标准化,有管理模式,日志量大,难以查询 4.elasticsearch 是基于Lucene 的搜索服务器 任务1:es2.0 介绍与安装 ———————————————————————————————————————————————————————— 下载 elasticsearch-2.3.1.tar.gz [root@localhost tmp]# wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.1/elasticsearch-2.3.1.tar.gz #Java -version 安装前要看下是否安装Java Jdk #yum -y install Java 安装Java Jdk #tar zxvf elasticsearch-2.3.1.tar.gz #cd elasticsearch-2.3.1 #vim config/elasticsearch.yml cluster.name:scapx node.name:node-1 network.host:192.168.5.20 # es 不运行在root下运行,创建useradd eser 用户 drwxr-xr-x. 6 root root 116 5月 11 21:25 elasticsearch-2.3.1 -rw-r--r--. 1 root root 27540442 4月 4 2016 elasticsearch-2.3.1.tar.gz [root@localhost tmp]# chown -R eser.eser elasticsearch-2.3.1 赋予权限 任务2:es2.0 插件安装 ————————————————————————————————————————————————————————— #su eser 切换用户 # ./elasticsearch -d 后台方式启动 #$ history | grep stop 关闭防火墙 #ps aux | grep java # netstat -anlpt 查看端口 [root@localhost bin]# ./plugin install lmenezes/elasticsearch-kopf #安装kopf插件 访问地址:http://192.168.5.8:9200/_plugin/kopf/ 安装head插件 https://github.com/mobz/elasticsearch-head [root@localhost bin]# ./plugin install mobz/elasticsearch-head #安装head插件 安装完毕head插件,可以访问地址:http://192.168.5.8:9200/_plugin/head/ 相关文档地址:https://www.abcdocker.com/abcdocker/2234 任务3:es5.0安装配置 free -g free -m 查看内存 # mkdir /data/server/ -p 创建文件夹 # ls # pwd [root@localhost tmp]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.2.tar.gz 下载elasticsearch-5.6.2.tar.gz版本 #java -version 查看本地是否有Java jdk #yum -y install java 安装Java jdk Elasticsearch高版本安装head相当方法,以下安装过程仅供参考 [root@localhost tmp]# yum -y install git [root@localhost tmp]# git clone https://github.com/mobz/elasticsearch-head.git #下载head插件 [root@localhost tmp]# wget https://nodejs.org/dist/v4.6.1/node-v4.6.1-linux-x64.tar.gz #下载nodejs [root@localhost tmp]# tar zxvf node-v4.6.1-linux-x64.tar.gz #解压 [root@localhost tmp]# vim /etc/profile #添加环境变量 export PATH=/tmp/node-v4.6.1-linux-x64/bin:$PATH [root@localhost tmp]# source /etc/profile #使环境变量生效 查看当前head插件目录下有无node_modules/grunt目录: [root@localhost elasticsearch-head]# npm install grunt --sava #没有的情况下执行 [root@localhost elasticsearch-head]# npm install #安装 执行失败或者 [root@localhost elasticsearch-head]# npm install -g cnpm --registry=https://registry.npm.taobao.org #或者安装 [root@localhost elasticsearch-head]# npm install -g grunt-cli #安装grunt [root@localhost elasticsearch-head]# vim Gruntfile.js #编辑 Gruntfile.js 文件93行options下添加hostname:'0.0.0.0' 检测head根目录下是否存在base文件夹,没有:将_site下的base文件夹及内容复制到head根目录下 [root@localhost elasticsearch-head]# cd _site/ [root@localhost _site]# cp -r base/ ../ #拷贝到上层目录 [root@localhost elasticsearch-head]# grunt server -d #启动grunt 任务6:logstash详细使用方式 简介 Logstash 可以传输和处理你的日志/事务或其他数据 功能 Logstash 是Elasticsearch的最佳数据管道。 Logstash 是插件式管理模式,在输入/过滤/输出以及编程过程中都可以使用插件进行定制,Logstash社区有超过200种可用插件 工作原理 Logstash 有两个必要元素,input和output ,一个可选元素:filter 这个三个元素,分别代表Logstash事件处理的三个阶段,输入>过滤器>输出 设置 设置文件 logstash.yml: logstash 的默认启动配置文件 jvm.options: logstash 的JVM 配置文件 startup.options(Linux)包含系统安装脚本在/usr/share/logstash/bin 中使用的选项为您的系统构建适当的启动脚本,安装Logstash软件包时,系统安装脚本将在安装过程结束时执行,并使用startup.options中指定的设置来设置用户/组,服务名称和服务描述等选项。 logstash.yml 设置项 参数 描述 默认值 node.name 节点名 机器的主机名 path.data Logstash及其插件用于任何持久性需求的目录 LOGSTASH_HOME/data pipeline.workers 同时执行管道的过滤器和输出阶段的工作任务数量,如果发现事件正在备份,或CPU未饱和,请考虑增加此数字以更好地利用机器处理能力 pipeline.batch.size 尝试执行过滤器和输出之前,单个工作线程从输入收集的最大事件数量,较大的批量处理大小一般来说效率更高,但是以增加的内存开销为代价,您可能必须通过设置LS_HEAP_SIZE 变量来有效使用该选项来增加JVM堆大小。 pipeline.batch.delay 创建管道事件批处理时,在将一个尺寸过小的批次发送给管道工作任务之前,等待每个事件需要多长时间(毫秒) log.level 日志级别,有效选项:fatal>error>warn>info>debug>trace log.format 日志格式,json或plain path.logs logstash 自身日志的存储路径 path.plugins 在哪里可以找到自定义的插件,您可以多次指定此设置以包含多个路径 启动 bin/logshash -f logstash.conf 其中[options]您可以指定用于控制logstsh执行的命令行标志 在命令行上设置的任何标志都会覆盖Logshash设置文件(logstash.yml)中的相应设置,但设置文件本身不会更改。 创建一个Log文件 mkdir /data/log touch ng_log.conf 值类型 一个插件可以要求设置的值是一个特定的类型,比如布尔值,列表或哈希值,以下值类型受支持 Array user=> [{id=> 1 ,name => bob},{id=>2,name=>jene}] Lists path=>{"var/log/messages","/var/log/*.log"] uris=>["http://elastic.co","http://example.net"] Boolean ssl_enable=>true Bytes my_bytes=>"1123" my_bytes=>"10MiB" my_bytes=>"100kib" my_bytes=>"180 mb" Codec codes=>"json" Hash match=>{ "field1"=>"value1" "field2"=>"value2" } Number port=>22 Password my_password=>"password" URI my_uri=>"http://foo:bar@example.net" Path my_path=>"/tmp/logshash" TCP应用 logstash配置 创建logstash-input-tcp.conf input{ tcp{ port=> 9231 codec=> json_lines mode=>server } } output{ elasticsearch{ hosts=>["localhost:9200"]} stdout{codec=>rubydebug} } 传输文件 logstash 配置 创建logstash-input-file.conf input{ file{ path=>["/val/log/nginx/access.log"] type=>"nginx-access-log" start_position=>"beginning" } } output{ if[type]=="nginx-access-log"{ elasticsearch{ hosts=>["localhost:9200"] index=>"nginx-access-log" } } } 启动/终止应用 如果你的logstash每次都是通过指定配置文件方式启动,不妨建立一个启动脚本 创建starup.sh nohup ./logstash -f logstash.conf >> nohup.out 2>&1 & 创建shutdown.sh PID=`ps -ef| grep logstash | awk '{print $2}'|head -n 1` kill -9 ${PID} 任务7:kibana具体安装及后续使用 安装Kibana 5.6.2 下载解压安装包,一定要装与ES相同的版本 配置 编辑文件config/kibana.yml 配置属性 cd kibana/config/ vim kibana.yml 添加 server.host:"192.168.80.32" elasticsearch.url:"http://192.168.80.32:9200" 任务8:kiban结合x-pack视图 server.port:5601 server.host:"192.168.5.10" elasticsearch.url:"http://192.168.5.10:9200" http://192.168.5.10:5601/status #可以查看状态 账号:elastic和changeme 想要在Kibana 中监控ES则需要安装X-pack插件 X-pack监控组件使您可以通过Kibana轻松地监控Elasticsearch,您可以实时查看集群的健康和性能,以及分析过去的集群,索引和节点度量,此外,您可以监视Kibana本身性能,当你安装X-pack在群集上,监控代理运行在每个检点上收集和指数指标从ElasticSearch,安装在X-pack在Kibana上 Elasticsearch下载X-pack 在Es的根目录(每个几点)运行bin/elasticsearch-plugin进行安装,先进入elasticsearch安装的目录,然后在输入命令 bin/elasticsearch-plugin install x-pack ES图形化Kibana安装与使用 如果你在Elasticsearch已禁用自动索引的创建,在elasticsearch.yml配置action.auto_create_index允许X-pack创造以下指标 action.auto_create_index:.security,.monnitoring*,.watches,.triggered_watches,.watcher-history* Kibana下载X-pack 在Kibana根目录运行bin/kibana-plugin进行 先进入kibana的安装目录,然后键入以下命令:bin/kibana-plugin install x-pack 离线安装方法 bin/elasticsearch-plugin install file:////usr/local/x-pack-5.3.2.zip 任务10:收集http 传输文件Logstash配置 创建logstash-input-file.conf input{ file { path=>["/val/log/nginx/access.log"] type=>"nginx-access-log" start_position=>"beginning" } } filter{ #日志格式拆分 } output{ if [type]=="nginx-access-log" { elasticsearch{ hosts=>["localhost:9200"] #地址,可以是多个 index=>"nginx-access-log" #索引 或者 "system-%{+YYYY.MM.dd}" user=> "elastic" #账号 password=>"changeme" #密码 } stdout{ codec=> rubydebug } } } cat acc.log |wc -l 查看日志有多少行 启动Logstash命令 ./bin/logstash -f access.conf [root@localhost tmp]# wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.3.tar.gz [root@localhost tmp]# wget https://artifacts.elastic.co/downloads/kibana/kibana-5.6.3-linux-x86_64.tar.gz grep '^[z-z]' elasticsearch.yml #查看修改了那些ie几点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号