
数据库索引原理
参考:http://www.ituring.com.cn/article/986
为什么需要索引
打个比方来说,索引的功能相当于字典前面的拼音目录一样。
假如一本词典3000页,我们要找到‘索’字,如果没有拼音目录我们会从头开始查找,有了拼音目录我们可以现在拼音目录找到‘suo’,然后掀到‘suo’的前后页来找到‘索’字。
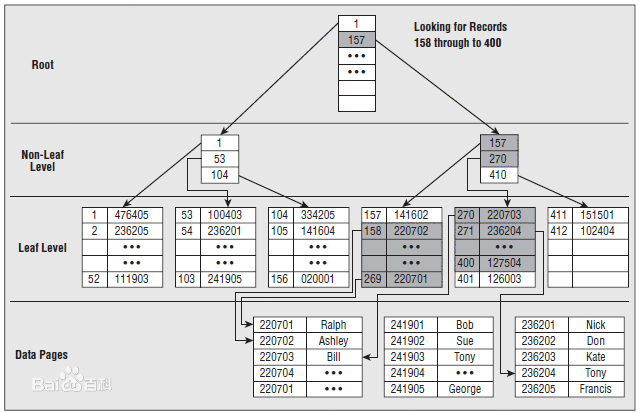
数据库也一样。数据在磁盘上是以块的形式存储的,这个块相当于字典的页。磁盘上的这些数据块与链表类似,即它们都包含一个数据段和一个指针,指针指向下一个节点(数据块)的内存地址,而且它们都不需要连续存储(即逻辑上相邻的数据块在物理上可以相隔很远)。
如图所示
我们建立一个表
| 字段 | 数据类型 | 字节大小 |
| ID | int | 4个字节 |
| Name | char(4) | 4个字节 |
假设次数据库只有一个表,数据库初始大小是1MB,那么此数据库被分成N=1024/8=128;假设有256条记录那么每个数据库有R=256/128=2条记录。
如果没有索引我们要从头至尾遍历所有的数据块。按照ID查找,我们需要128次才能找到我们需要的某个Name。也就是N次。
如果对这个“ID”建立了索引,即从小到大进行了排序之后我们就可以采用二叉树的形式进行查找。那么我们只需要8次,也就是log2 256=8次。也就是log2N
如下图所示
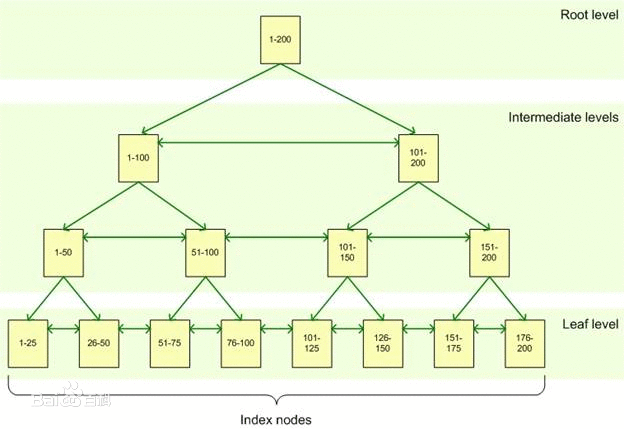
所以有无索引的本质区别在于查找的方式不一样。无索引是线性查找,有索引的查找是二叉树查找。
如果本文引用了你的文章而未注明,请及时联系我。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号