
一、 问题:在使用Splunk做可视化面板【关系图】和【桑基图】的时候,想要过滤掉与某个节点不相关的数据,比如:
查看与src=110.68.0.178相关的数据的关系图:
测试数据:src-dest.csv
| src | dest | count |
| 107.159.0.32 | 157.28.151.20 | 81 |
| 110.68.0.178 | 157.28.19.184 | 69 |
| 110.68.0.178 | 157.28.151.50 | 172 |
| 152.115.104.104 | 121.138.108.76 | 234 |
| 152.115.104.104 | 28.185.93.35 | 120 |
| 112.72.128.231 | 157.28.151.50 | 175 |
| 118.234.0.179 | 157.28.19.184 | 85 |
| 118.234.0.179 | 157.28.151.50 | 171 |
| 119.10.184.222 | 157.28.12.66 | 175 |
| 28.0.64.67 | 157.28.12.66 | 173 |
| 125.38.92.28 | 11.19.51.10 | 197 |
| 125.38.92.28 | 116.195.40.100 | 115 |
| 138.214.0.44 | 157.28.151.20 | 346 |
| 14.194.0.151 | 157.28.12.5 | 430 |
| 155.35.233.233 | 157.28.151.60 | 171 |
| 160.243.0.39 | 157.28.12.66 | 246 |
| 183.91.192.126 | 157.28.14.50 | 411 |
| 183.91.192.126 | 157.28.151.50 | 510 |
| 195.163.79.25 | 121.138.108.81 | 36 |
关系图:
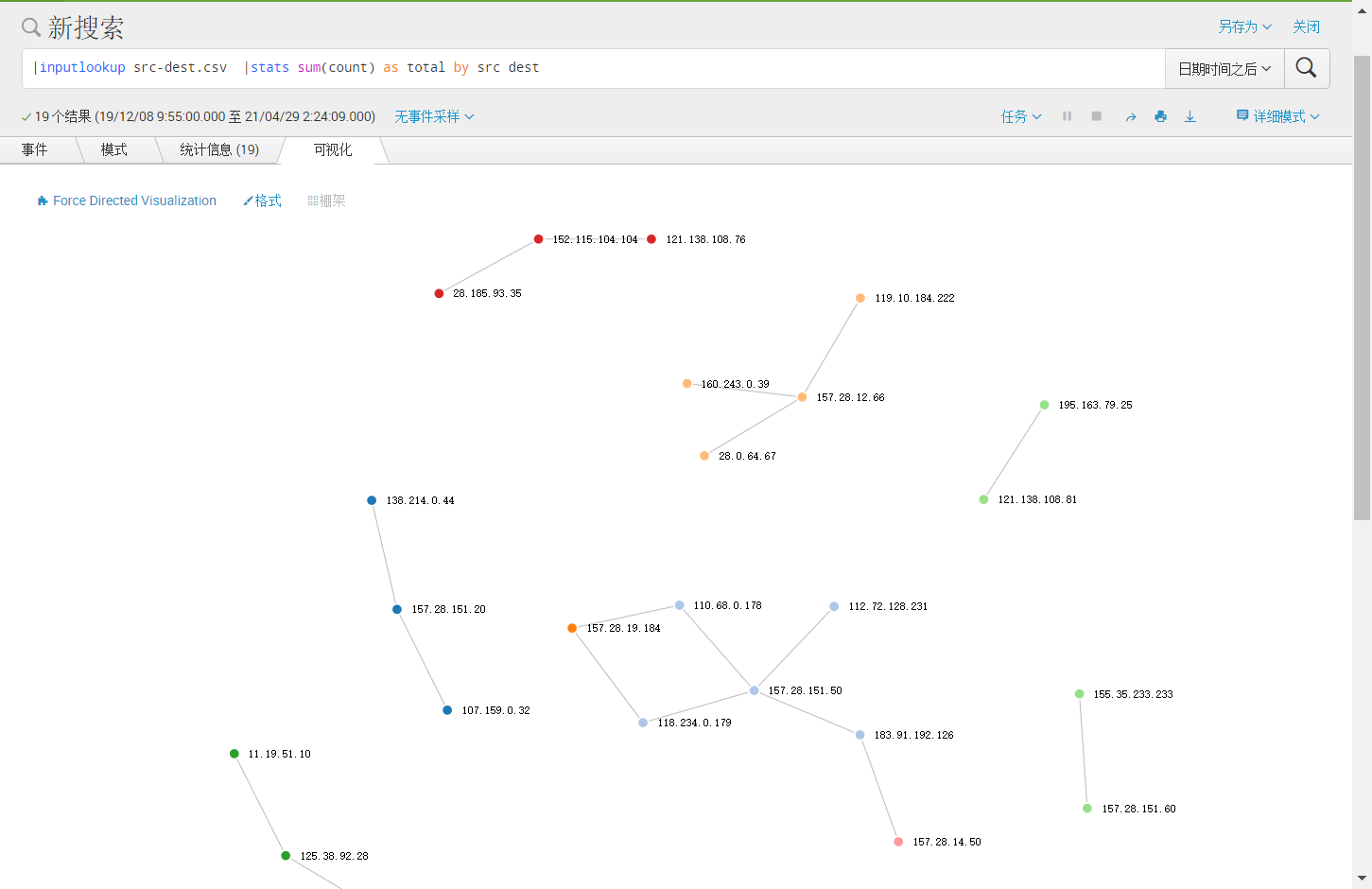
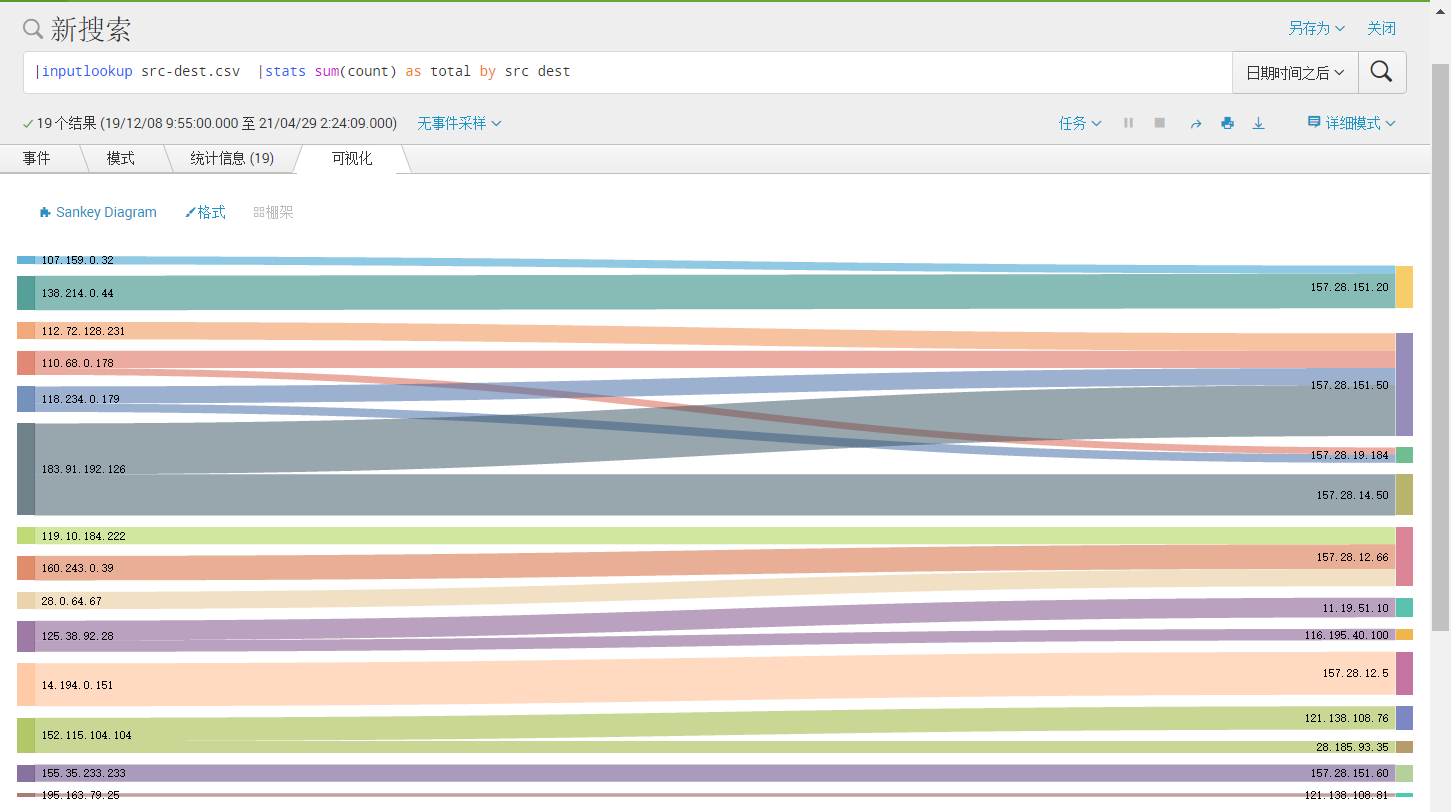
桑基图:
二 、方法:
使用 自定义命令 diagramsinge
SPL搜索语句:| inputlookup src-dest.csv |stats sum(count) as total by src dest | diagramsinge src_field=src dest_field=dest value=110.68.0.178 iter_mode=all
三 、结果:

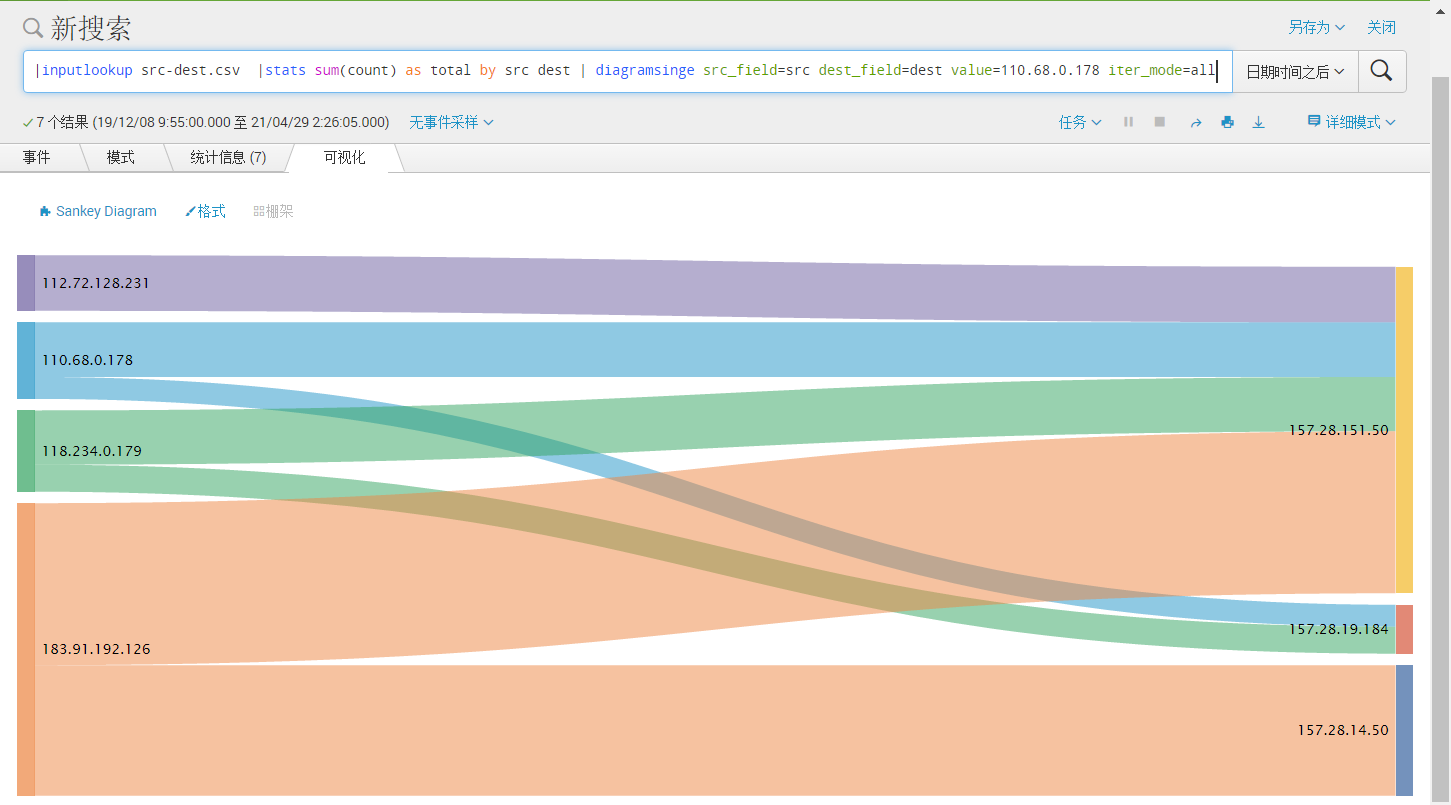
四、实现过程
a、编写命令脚本diagramsinge.py
路径 $SPLUNK_HOME/etc/apps/{app_name}/bin
脚本
#!/usr/bin/env python # coding=utf-8 # # Copyright © 2011-2015 Splunk, Inc. # # Licensed under the Apache License, Version 2.0 (the "License"): you may # not use this file except in compliance with the License. You may obtain # a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, WITHOUT # WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the # License for the specific language governing permissions and limitations # under the License. from __future__ import absolute_import, division, print_function, unicode_literals # import app import sys import os import logging as logger #logger.basicConfig(level=logger.INFO, format='%(asctime)s %(levelname)s %(message)s', # filename=os.path.join('/opt/splunk/', 'test.log'), filemode='a') from splunklib.searchcommands import dispatch, EventingCommand, Configuration, Option, validators from splunklib import six def formattsinge(sourcedata, filterarray, max_order, results, src, dest,iter_mode): filterarray2 = [] sourcedata2 = [] unsourcedata2 = {} limit_bool = True if max_order <= -1 or max_order > 0 else False if filterarray and sourcedata and limit_bool: for row in sourcedata: haved_bool = True for filter in filterarray: if haved_bool: if iter_mode == 'src' or iter_mode == 'all': if filter == row[src]: filterarray2.append(row[dest]) results.append(row) unsourcedata2[row[src] + row[dest]] = row haved_bool = False if iter_mode == 'dest' or iter_mode == 'all': if filter == row[dest]: filterarray2.append(row[src]) results.append(row) unsourcedata2[row[src] + row[dest]] = row haved_bool = False max_order -= 1 unsourcedata2_keys = unsourcedata2.keys() for row1 in sourcedata: if row1[src] + row1[dest] not in unsourcedata2_keys: sourcedata2.append(row1) formattsinge(sourcedata2, filterarray2, max_order, results, src, dest,iter_mode) else: return results return results def formattsinge_sort(sourcedata, filterarray, max_order, results, src, dest, sort_field,iter_mode): filterarray2 = [] sourcedata2 = [] unsourcedata2 = {} limit_bool = True if max_order == -1 or max_order > 0 else False if filterarray and sourcedata and limit_bool and len(filterarray) < max_order: for row in sourcedata: haved_bool = True for filter in filterarray: if haved_bool: filters = filter.split('_') if len(filter.split('_')) > 1 else [filter, 0] if iter_mode == 'src' or iter_mode == 'all': if filters[0] == row[src] and filters[1] < row[sort_field]: filterarray2.append(row[dest] + '_' + row[sort_field]) results.append(row) unsourcedata2[row[src] + row[dest]] = row haved_bool = False if iter_mode == 'dest' or iter_mode == 'all': if filters[0] == row[dest] and filters[1] > row[sort_field]: filterarray2.append(row[src] + '_' + row[sort_field]) results.append(row) unsourcedata2[row[src] + row[dest]] = row haved_bool = False max_order -= 1 unsourcedata2_keys = unsourcedata2.keys() for row1 in sourcedata: if row1[src] + row1[dest] not in unsourcedata2_keys: sourcedata2.append(row1) formattsinge_sort(sourcedata2, filterarray2, max_order, results, src, dest, sort_field,iter_mode) else: return results return results @Configuration() class DiagramSingeCommand(EventingCommand): # self.logger.debug("command start run ...") limit = Option(require=False, validate=validators.Integer()) src_field = Option(require=True, validate=validators.Fieldname()) dest_field = Option(require=True, validate=validators.Fieldname()) sort_field = Option(require=False, validate=validators.Fieldname()) value = Option(require=True) iter_mode = Option(require=False) def transform(self, records): self.logger.debug('CountMatchesCommand: %s', records) # logs command line src_field = self.src_field dest_field = self.dest_field sort_field = self.sort_field value = [str(self.value)] results_default = [] iter_mode = self.iter_mode if self.iter_mode and self.iter_mode in ['src', 'dest', 'all'] else 'src' limit = self.limit if self.limit else 1000 records_list = [] for r in records: records_list.append(r) if sort_field: records = formattsinge_sort(records_list, value, limit, results_default, src_field, dest_field,sort_field,iter_mode) else : records = formattsinge(records_list, value, limit, results_default, src_field, dest_field,iter_mode) for record in records: yield record dispatch(DiagramSingeCommand, sys.argv, sys.stdin, sys.stdout, __name__)
b、配置文件:commands.conf
路径: $SPLUNK_HOME/etc/apps/{app_name}/local
[diagramsinge]
filename = diagramsinge.py
supports_getinfo = false
supports_rawargs = true
chunked = true
c、配置文件:searchbnf.conf
路径: $SPLUNK_HOME/etc/apps/{app_name}/local
[diagramsinge-command] syntax = diagramsinge src_field=<field_name> dest_field=<field_name> value=<value> limit=<int> sort_field=<field_name> iter_mode=<mode> alias = shortdesc = 格式化统计结果. description = \ 追溯与指定源关联的结果 comment1 = \ 运行此命令后会修改事件告警状态. example1 = | stats count by src dest \ | diagramsinge src_field="src" dest_field="dest" value="127.0.0.1" appears-in = 1.5 maintainer = dnoble usage = public tags = stats
命令注解*
名称:diagramsinge
描述:diagramsinge命令类型为Dataset processing,Dataset processing命令要求整个数据集就位,然后命令才能运行。这些命令不进行转换,不进行分发,不进行流传输并且不进行编排。diagramsinge通过对输入的数据及给定的参数对数据进行过滤。
用例:| inputlookup src-dest.csv |stats sum(count) as total by src dest | diagramsinge src_field=src dest_field=dest value=110.68.0.178 iter_mode=all
起始节点:src,目的节点:dest,搜索条件为:110.68.0.178,模式:all,查询所有与110.68.0.178有直接或间接关联的数据。
| inputlookup src-dest.csv |stats sum(count) as total max(_time) as time by src dest | diagramsinge src_field=src dest_field=dest value=110.68.0.178 iter_mode=src sort_field=time
起始节点:src,目的节点:dest,搜索条件为:110.68.0.178,模式:src,排序:time,查询所有src=110.68.0.178的数据,src=110.68.0.178时对应的dest作为src,以此类推。
参数:src_field
【字段名称】 指定起始节点的字段名
dest_field
【字段名称】 指定目的节点的字段名
value
【字段值】 指定关注的节点值
iter_mode
src (默认)将关注的节点值作为起始节点,并将其对应的目的节点作为起始节点,以此类推。
dest 将关注的节点值作为目的节点,并将其对应的起始节点作为目的节点,以此类推。
all 将关注的节点值作为起始节点和目的节点,并将其对应的节点作为起始节点及目的节点,以此类推。
sort_field
【字段名称】(测试)依据指定字段的值对结果排序,以使每个链路在时间上连续,注意会排除时续不一致的结果。
limit
【数值】(默认1000)限制节点计算次数。
使用条件:在自定义diagramsinge,需要有列出节点字段
| stats count by src dest
或者
| table src dest count
参考:
https://dev.splunk.com/enterprise/docs/devtools/customsearchcommands/
https://docs.splunk.com/Documentation/Splunk/latest/Search/Typesofcommands
https://github.com/splunk/splunk-sdk-python/tree/master/examples/searchcommands_template/bin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号