

《数据挖掘导论》目录
目录
什么是数据挖掘
常见的相似度计算方法介绍
决策树介绍
基于规则的分类
贝叶斯分类器
人工神经网络介绍
关联分析
异常检测
数据挖掘
数据挖掘(英语:Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
常见的数据相似度计算
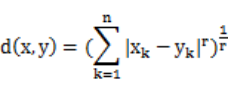
汉密尔顿距离(r = 1)
欧式距离(r = 2)
上确界距离(r = max)
二元数据相似性
简单匹配系数(Simple Matching Coefficient,SMC):

Jaccard 系数:

余弦相似度:
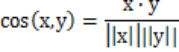
广义Jaccard系数:
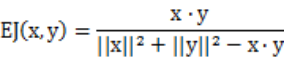
皮尔逊相关系数(Pearson’s correlation):
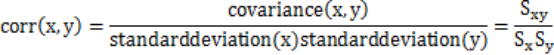
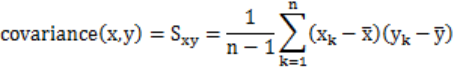

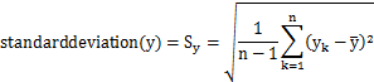
决策树(decision tree)(TODO)
决策树是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。
基于规则的分类器(TODO)
直接方法:直接从数据中提取分类规则
顺序覆盖算法:
Learn-One-Rule + 剪枝 à改善泛化误差
PRPPER算法:适合类分布不平衡类排序
间接方法:从其他分类模型(决策树、神经网络)中提取分类规则
朴素贝叶斯分类器(TODO)
前提:假设属性之间条件独立。
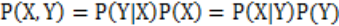
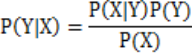
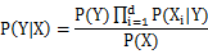
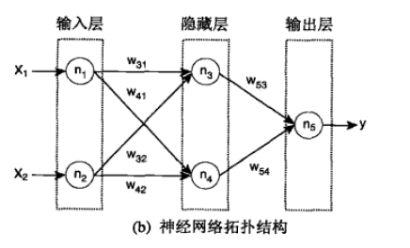
人工神经网络(TODO)

关联分析(association analysis)
注意:
第一:从大型事物数据集中发现模式可能在计算上付出高代价;
第二:所发现的某些模式可能是虚假的,因为它们是偶然发生的;
定义:
项集:
事务的集合:
支持度计数:
关联规则、支持度、置信度
关联规则:是形如X->Y的蕴含表达式、其中X、Y是不相交的项集。
关联规则发现:给定事务的集合T,关联规则发现是指找出支持度大于等于minsup并且置信度大于等于minconf的所有规则。
关联规则的挖掘通常的策略是将任务分解成下列两个子任务:
1,频繁项集的产生:其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集(frequent itemset)
2,规则的产生:其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则(strong rule)
关联规则的挖掘通常的策略是将任务分解成下列两个子任务:
1,频繁项集的产生:
减少候选项集的数目
减少比较次数
任何具有反单调性的度量都能够直接结合到数据挖掘算法中,可以对候选点选项集的指数搜索空间进行有效地剪枝。
异常检测
异常的成因
数据来源于不同的类
自然变异
数据测量和收集误差
小结:异常可以是上述原因或者我们未考虑的其他原因的结果。事实上,数据集中可能有多种异常源,并且任何特定的异常的底层原因常常是未知的。
异常检查方法
基于模型的技术
基于邻近度的技术
基于密度的技术
异常处理时,需要处理的问题:
用于定义异常的属性个数(多元属性相互关系)、全局观点与局部观点(在一个什么样的场景下)、点的异常程度、一次识别一个异常与多个异常异常、评估、有效性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号