

flink 数据倾斜问题解决方案
一 数据倾斜的影响
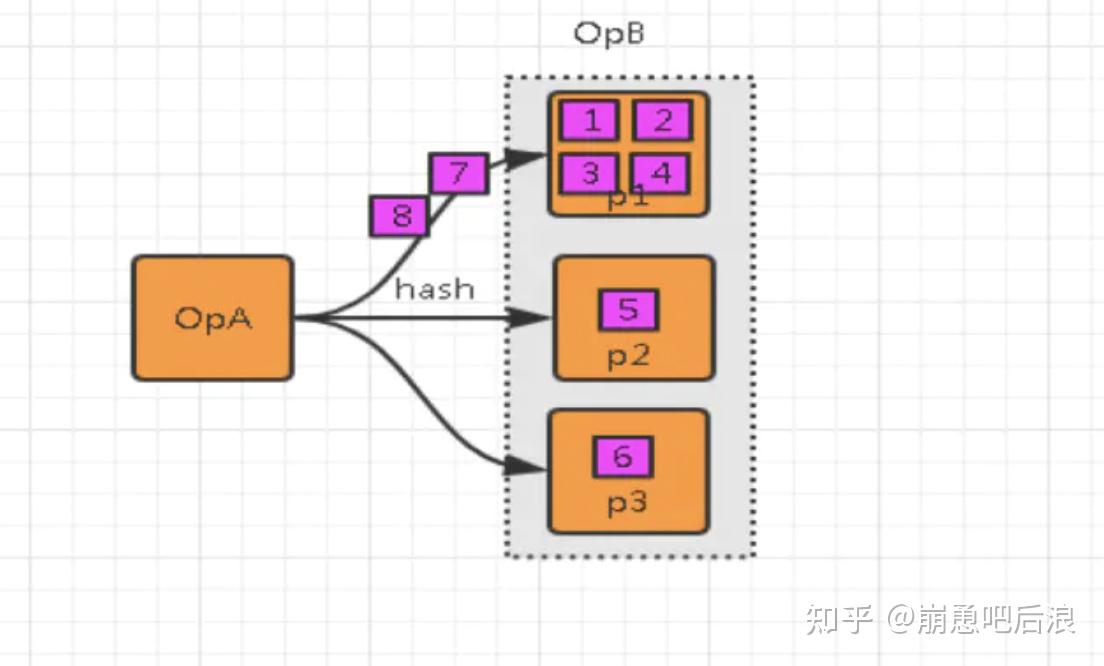
(1)单点问题
数据集中在某些分区上(Subtask),导致数据严重不平衡。
(2)GC 频繁
过多的数据集中在某些 JVM(TaskManager),使得JVM 的内存资源短缺,导致频繁 GC。
(3)吞吐下降、延迟增大
数据单点和频繁 GC 导致吞吐下降、延迟增大。
(4)系统崩溃
严重情况下,过长的 GC 导致 TaskManager 失联,系统崩溃。
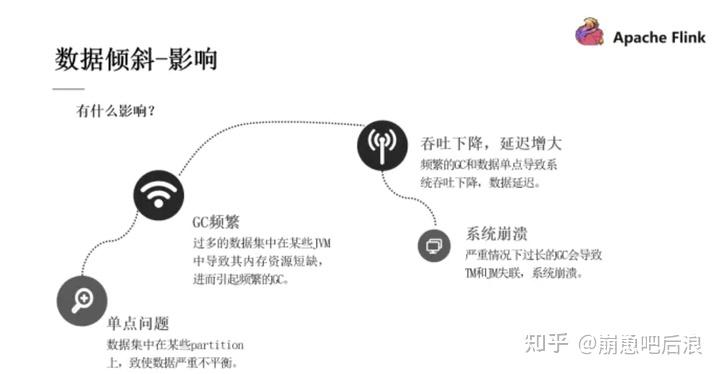
二 数据倾斜的定位
步骤1:定位反压
定位反压有2种方式:Flink Web UI 自带的反压监控(直接方式)、Flink Task Metrics(间接方式)。通过监控反压的信息,可以获取到数据处理瓶颈的 Subtask。
步骤2:确定数据倾斜
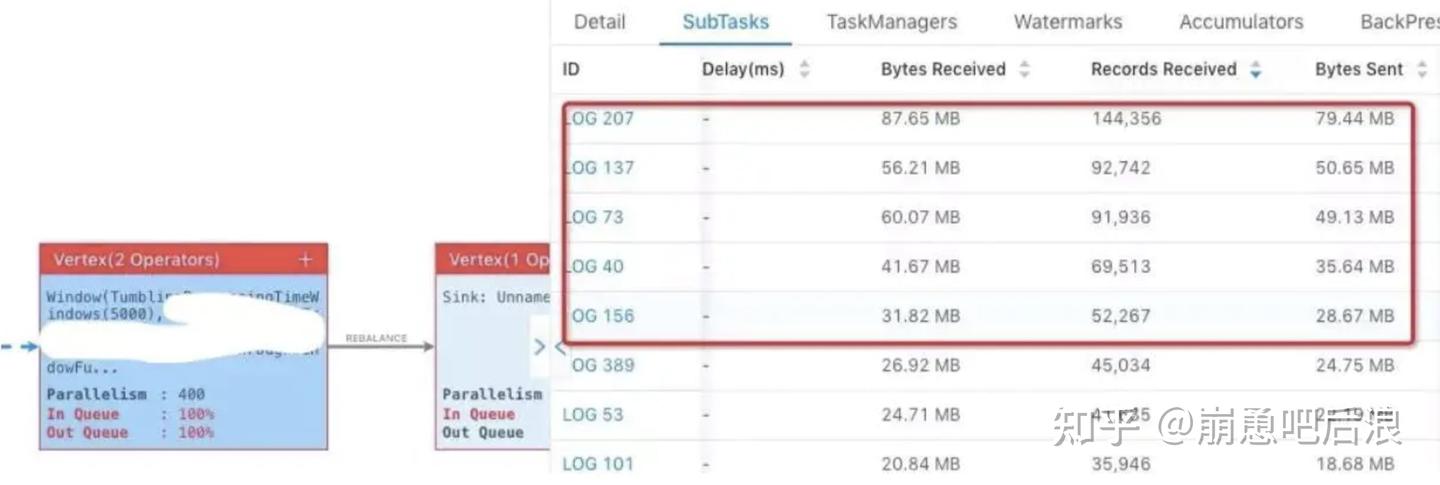
Flink Web UI 自带Subtask 接收和发送的数据量。当 Subtasks 之间处理的数据量有较大的差距,则该 Subtask 出现数据倾斜。如下图所示,红框内的 Subtask 出现数据热点。
三 Flink 如何处理常见数据倾斜?
数据倾斜是大家都会遇到的高频问题,解决的方案也不少。
第一种场景是当我们的并发度设置的比分区数要低时,就会造成上面所说的消费不均匀的情况。

第二种提到的就是 key 分布不均匀的情况,可以通过添加随机前缀打散它们的分布,使得数据不会集中在几个 Task 中。
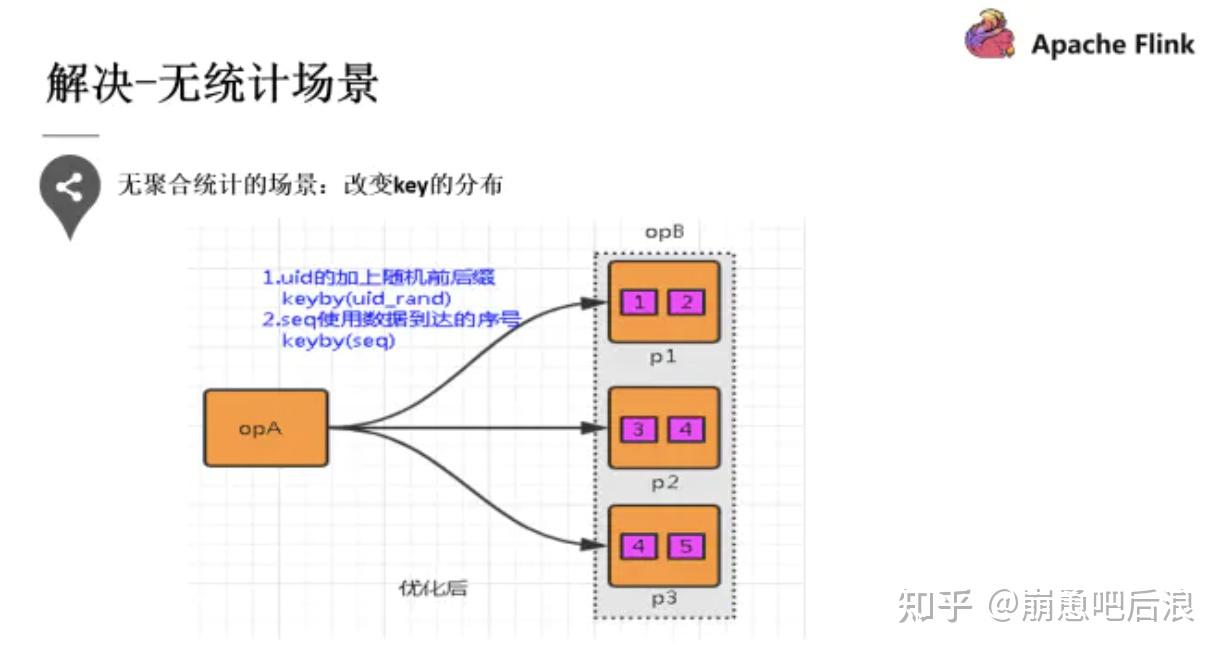
第三种 有统计场景
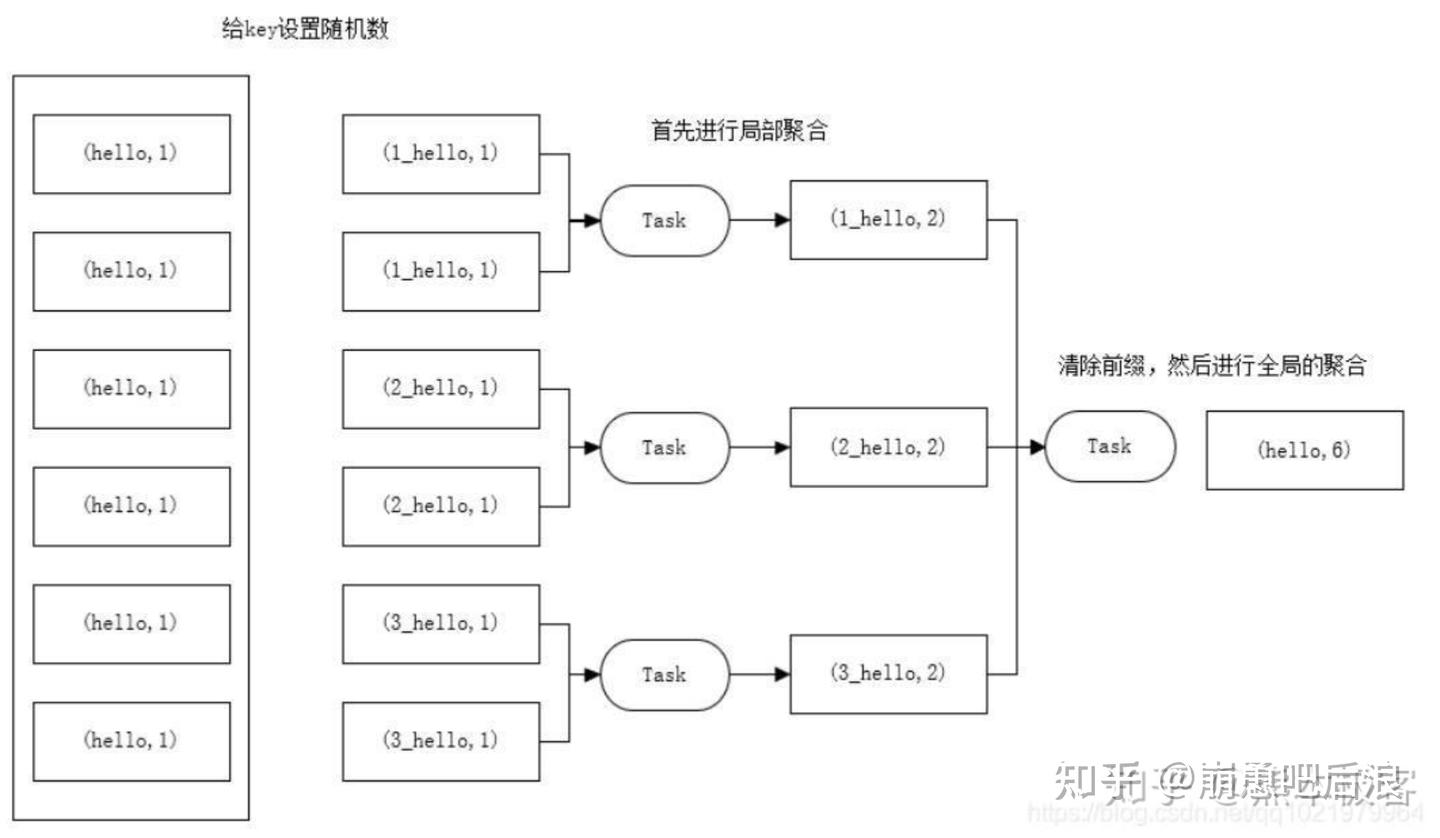
在每个节点本地对相同的 key 进行一次聚合操作,类似于 MapReduce 中的本地 combiner。map-side 预聚合之后,每个节点本地就只会有一条相同的 key,因为多条相同的 key 都被聚合起来了。其他节点在拉取所有节点上的相同 key 时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘 IO 以及网络传输开销。 两阶段聚合的具体措施:
①预聚合:加盐局部聚合,在原来的 key 上加随机的前缀或者后缀。
②聚合:去盐全局聚合,删除预聚合添加的前缀或者后缀,然后进行聚合统计。

其他数据倾斜表征:
问题1: flink实时程序在线上环境上运行遇到一个很诡异的问题,flink使用eventtime读取kafka数据发现无法触发计算。--->事件时间倾斜
解决:
发现问题:
经过代码打印查看后发现十个并行度执行含有十个分区的kafka,有几个分区的watermark不更新,如图所示。
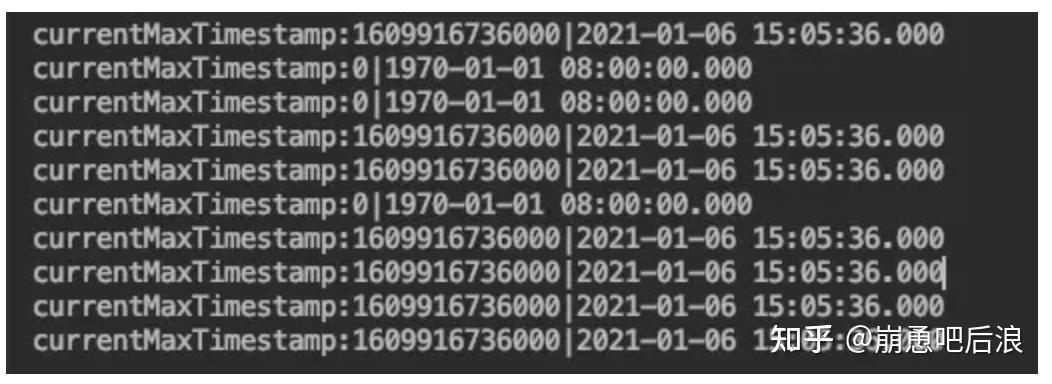
打开kafka监控,可以看到数据有严重的倾斜问题。如下图所示,10个分区中有三个分区数据量特别少,5号分区基本上没数据。
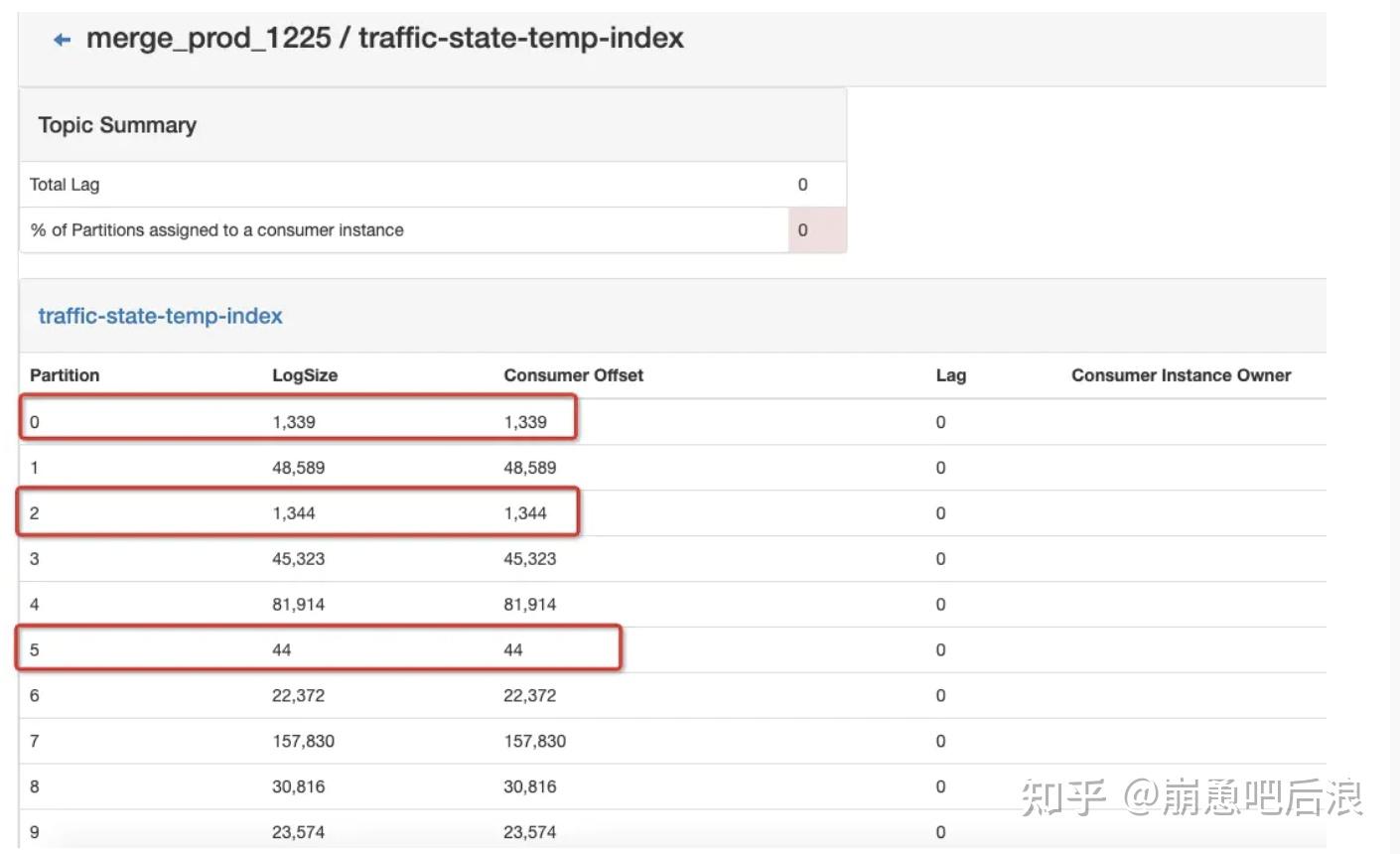
watermark的传递机制
当并行执行的情况下,如下图所示,每次接受的水印发送的水印都是最小的,木桶效应。但是,当某个分区始终无数据的时候,就不会更新该分区的watermark值,
那么窗口就一直不会被触发计算。这种现象在某些hash极端导致数据倾斜很普遍。
解决方案:
2.1 更改并行度
把并行度改小,使得每个并行进程处理多个分区数据,同个并行的进程处理多分区数据就会使用最大的水印。
2.3 withIdleness
flink 1.11新增了支持watermark空闲检测
WatermarkStrategy.withIdleness()方法允许用户在配置的时间内(即超时时间内)没有记录到达时将一个流标记为空闲,从而进一步支持 Flink 正确处理多个并发之间的事件时间倾斜的问题,
并且避免了空闲的并发延迟整个系统的事件时间。通过将 Kafka 连接器迁移至新的接口(FLINK-17669),用户可以受益于针对单个并发的空闲检测。
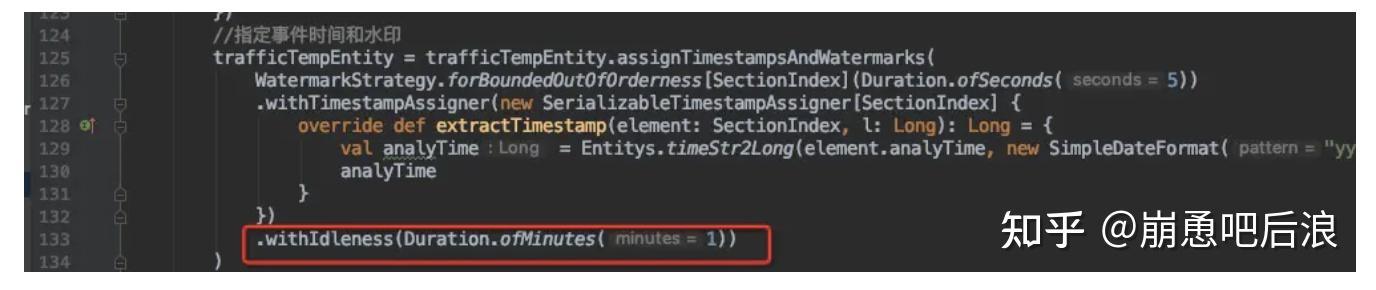
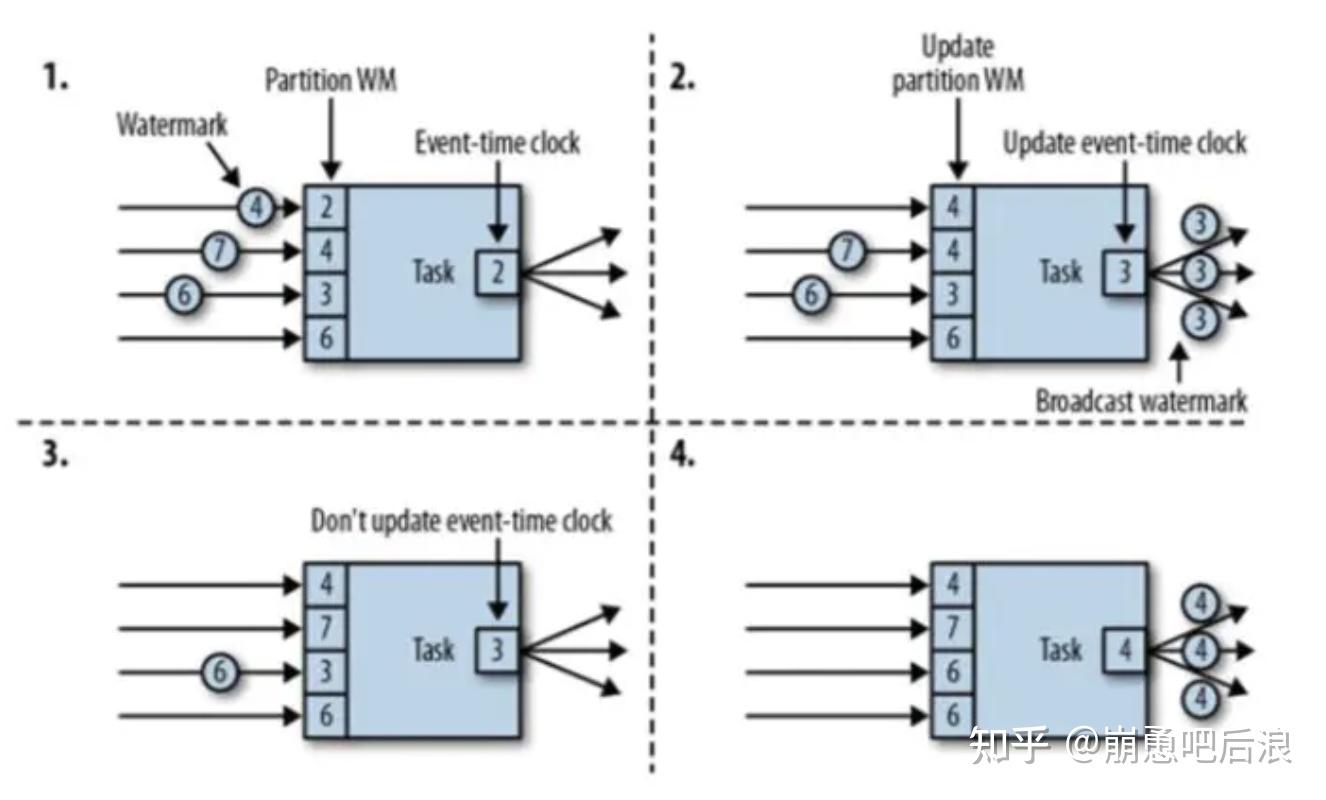
继续研究下withIdleness的实现原理
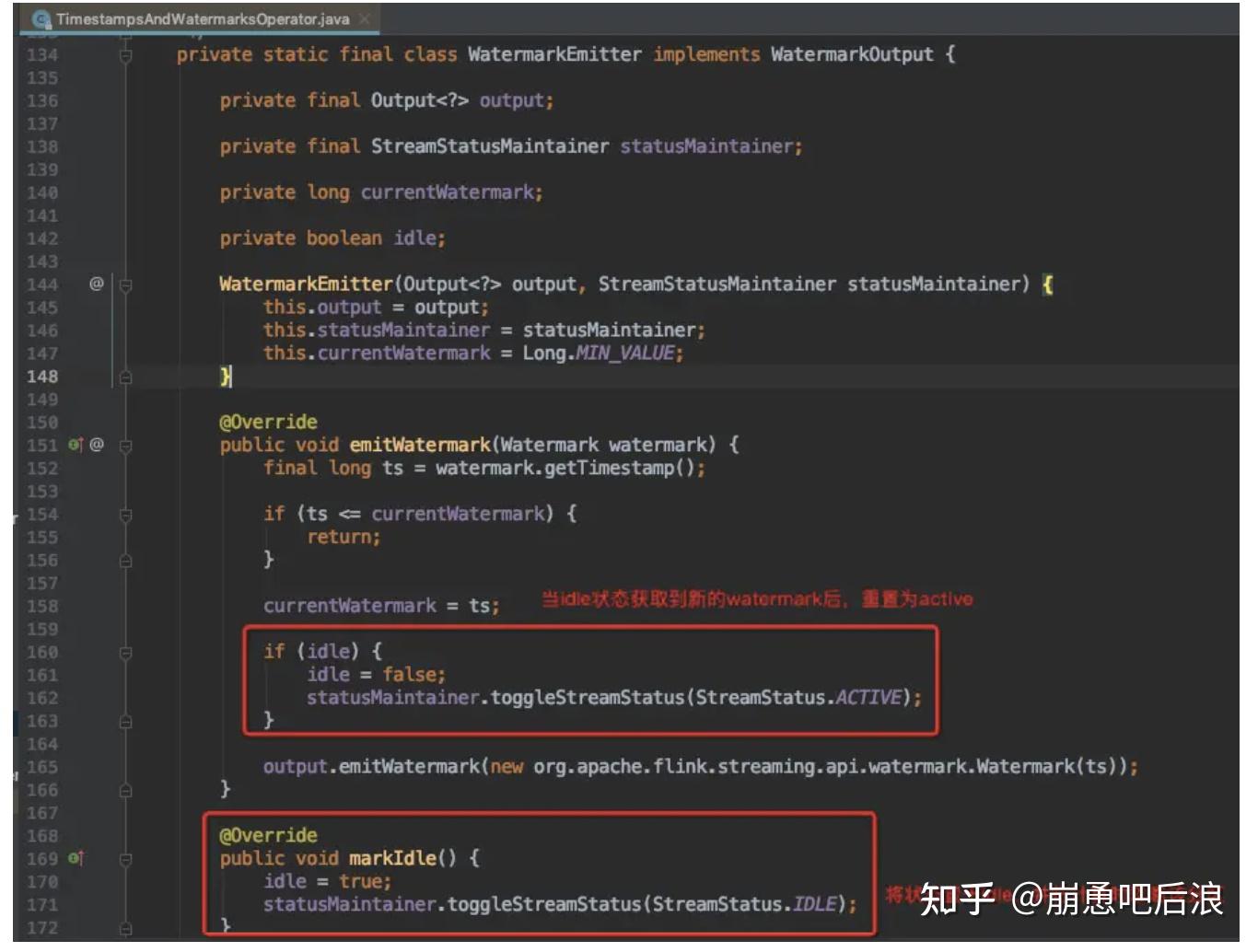
如图所示,可以看到idle的触发,是一个动态的过程,当满足了idle条件就会触发idle使分区忽略,如果接受到数据就会重制为活跃分区。
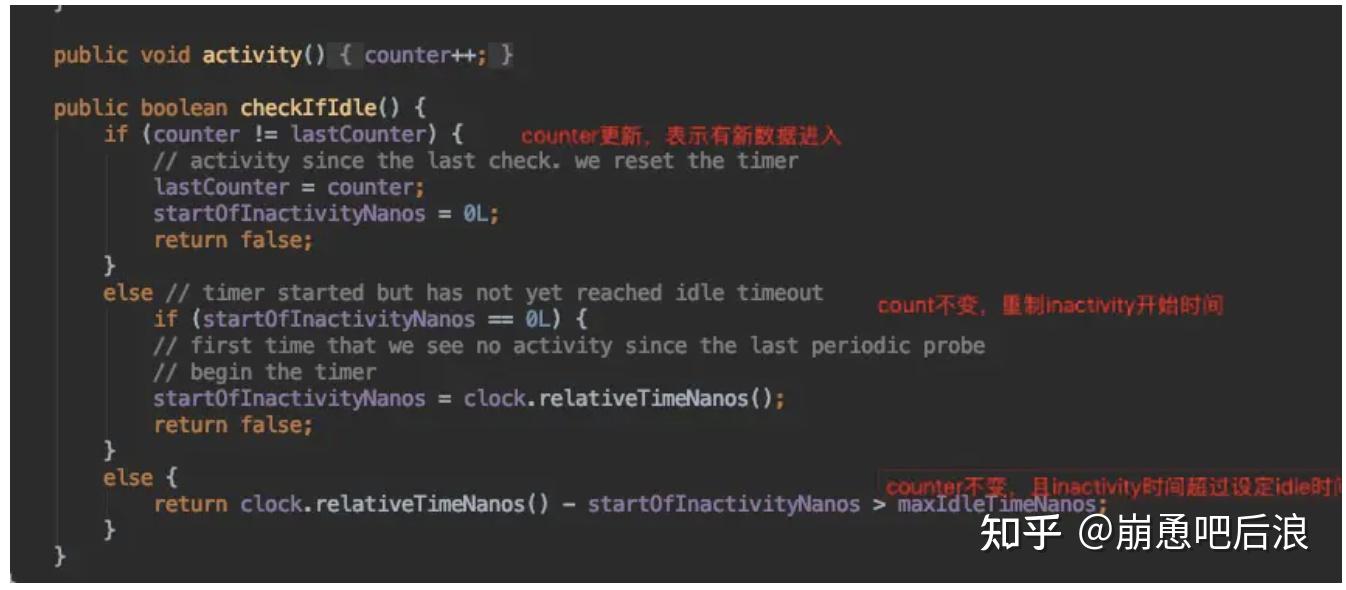
还有一个问题:kafka为什么分区数据量倾斜:我觉得 可能一大原因是 写入kafka的时候 做到没有数据均发。比如说 kafka 的key做hash的时候,也存在某些key是热点,导致没有均发。方案就是打散key,不怕数据量大,就怕不均衡。
问题2:分项目统计某个时间粒度的pv数据,每个项目的数据量不同,某个项目的数据量很大,导致这个项目的窗口中的数据很大,发生倾斜.简单来说:keyby之后每个流的量不一样,导致窗口的量不一样,差距大了就会倾斜 --->window数据倾斜

 浙公网安备 33010602011771号
浙公网安备 33010602011771号