


利用python+selenium爬取人人贷用户信息
P2P网络信贷,由于其优秀的集资功能和对闲散资金的高度利用,使得普惠金融成为可能,但它也比传统信贷有着更高的风险,其风险主要来自于借贷双方的信息不对称性。现利用python+selenium爬取人人贷网站上借贷人的基本信息,后期可用于数据分析来探索借贷人的相关特征。
工作环境
首先下载并安装python软件,其次使用pip安装本爬虫脚本用到的selenium模块。按住 win+R键,输入cmd调用系统的DOS命令栏,然后用pip安装对应的python包,使用的命名格式如下:pip install “模块名”,如安装selenium模块,命令如下pip install selenium。采用这种方式分别安装selenium、pandas、bs4、requests模块。
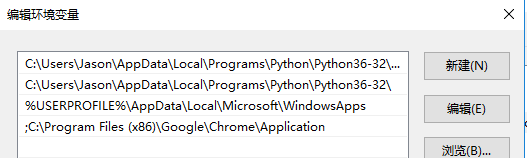
本脚本调用的是Chrome浏览器(可实现无头浏览),需要先下载并安装Chrome浏览器,并且下载与Chrome版本对应的Chrome驱动器Chromedriver到与Chrome程序所在的文件夹,并在电脑属性中设置环境变量,将该路径添加至path:;C:\Program Files (x86)\Google\Chrome\Application(注意:此路径前有英文分号)。
环境变量设置步骤如下:1.按住Windows键,在“此电脑”处单击鼠标右键,在其下拉菜单中用鼠标左键单击“属性”,在弹出的对话框中点击“高级系统设置”,再点击“环境变量”,双击“path”,“新建”,粘贴Chrome程序路径。如下图:
脚本说明
此脚本主要包含3块:登录网站,收集借款人的借款ID和利用借款ID爬取借款人的相关信息。
(1)登录网站。由于借款人的借款信息只有在登录后在“散标”目录下才可见。如下图:
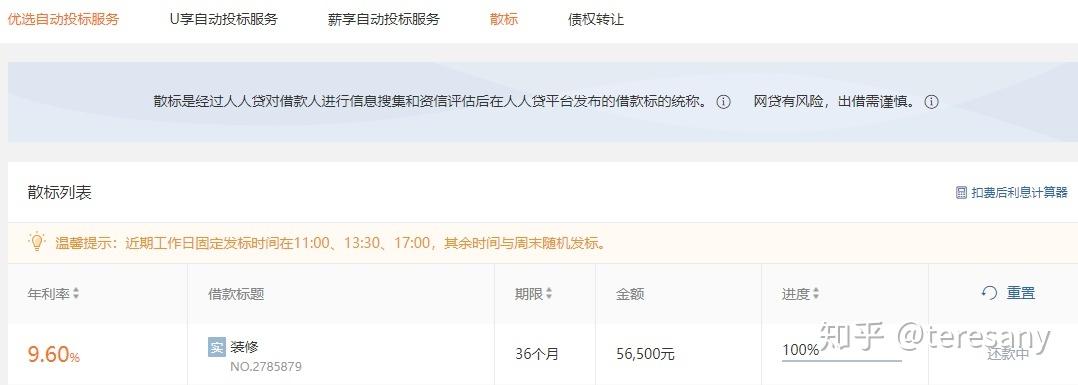
因此爬取前需先在人人贷注册,随后使用密码登录。需注意的是,根据人人贷网站设计特点,打开网址https://www.renrendai.com/login后,需在页面上点击“密码登录”才进入到登录界面。
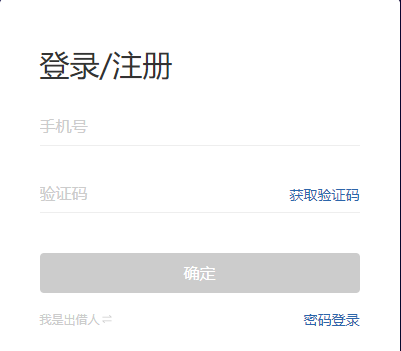
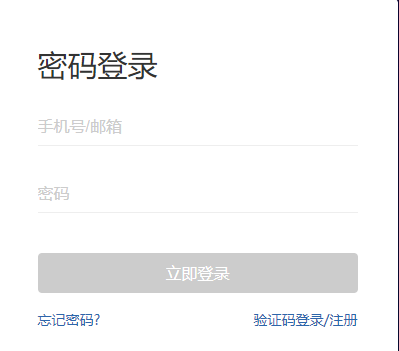
关键代码如下:
driver.get("https://www.renrendai.com/login")
driver.find_element_by_class_name("tab-password").click() # 点击密码登录(在隐藏模块)
driver.find_element_by_id("login_username").send_keys(username)
time.sleep(2) #设置等待时间,不用修改
driver.find_element_by_id("J_pass_input").send_keys(password)
time.sleep(5) #设置等待时间,以防止用户名下拉菜单挡住登录按钮
driver.find_element_by_class_name("button-block").click() #点击登录(2)收集loan ID。人人贷的每一位借款人的借款信息所在网址有一定的规律性,即网址后缀为借款人的借款ID,如网址“https://www.renrendai.com/loan-2785879.html”的借款人的借款ID为2785879。
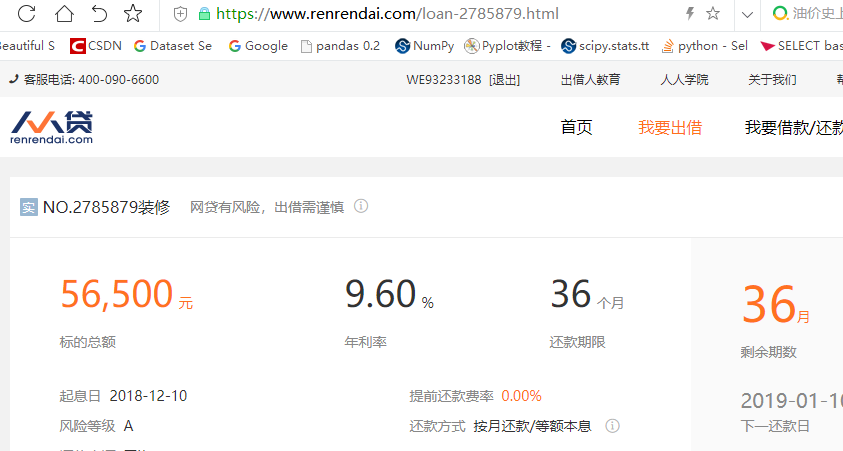
关键代码如下:
df_list = []
for j in range(100): # 当前100散标信息页面一共只有100页,所以填的是100,可根据具体情况修改
url = "https://www.renrendai.com/loan/list/loanList?startNum=%s&limit=10" % str(j)
response = requests.get(url)
data_dict = json.loads(response.content) # json.load读取json文件,json.loads读取字符串。
for i in range(10):
df_list.append({'loanId': data_dict['data']['list'][i]['loanId']})
df = pd.DataFrame(df_list, columns=['loanId'])将借款ID保存在DataFrame类型下的df中,便于后面爬取信息时调用。
(3)爬取信息。关键代码如下:
url="https://www.renrendai.com/loan-%s.html"%str(loan_id)
driver.get(url)
soup = BeautifulSoup(driver.page_source,'lxml')
user_info_dict = {}
items = soup.find('div', class_="loan-user-info").find_all('span', class_="pr20")
for item in items:
index = item.parent.contents[0].get_text() # 或者index = item.contents[0] #或者index = item.get_text()
value = item.parent.contents[1].get_text()
user_info_dict[index] = value</code></pre></div><p data-pid="Fm5n2WDR">利用beautifulsoup4模块中的beautifulsoup函数爬取网站内容后解析json文件来获取所需信息。注意:class_="loan-user-info"此处的json文件中的class命名经常修改。</p><p data-pid="e7b20nLE">最终,运行脚本后将爬取到的信息存入CSV文件,用excel打开后如下:</p><figure data-size="normal"><div><img src="https://picx.zhimg.com/v2-f6e244e62d5fa8da7a9a0176cb9e04c5_1440w.jpg" data-caption="" data-size="normal" data-rawwidth="1151" data-rawheight="192" data-original-token="v2-f6e244e62d5fa8da7a9a0176cb9e04c5" class="origin_image zh-lightbox-thumb" width="1151" data-original="https://picx.zhimg.com/v2-f6e244e62d5fa8da7a9a0176cb9e04c5_r.jpg" style=""></div></figure><p data-pid="V2le3M7X">具体实现见网盘:</p><p data-pid="hepCpgcE">链接:<a href="https://link.zhihu.com/?target=https%3A//pan.baidu.com/s/1P4EhHbrFyWeF0SaM5b4hog" class=" external" target="_blank" rel="nofollow noreferrer" data-za-detail-view-id="1043"><span class="invisible">https://</span><span class="visible">pan.baidu.com/s/1P4EhHb</span><span class="invisible">rFyWeF0SaM5b4hog</span><span class="ellipsis"></span></a> </p><p data-pid="siBUOfQL">提取码:yi5z </p><p data-pid="QZNmTE29">参考文献:</p><p data-pid="Jnmp0J_Q">[1]<a href="https://link.zhihu.com/?target=https%3A//blog.csdn.net/starkbling/article/details/82144070" class=" wrap external" target="_blank" rel="nofollow noreferrer" data-za-detail-view-id="1043">手把手教你用python爬取人人贷网站借款人信息 - starkbling的博客 - CSDN博客</a></p><p data-pid="nIhFwCCJ">[2]<a href="https://link.zhihu.com/?target=https%3A//blog.csdn.net/u010986776/article/details/79266448%3Futm_source%3Dblogxgwz0" class=" wrap external" target="_blank" rel="nofollow noreferrer" data-za-detail-view-id="1043">使用slenium+chromedriver实现无敌爬虫 - 欧阳桫的技术博客 - CSDN博客</a></p><p></p><p></p></div>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号