

Flink 流数据处理 基于Flink1.12.0版本 MapFunction 只适用于一对一的转换,而 FlatMapFunction中可以一对多,或者多对一
序言
基于官网教程整理的一个教程。基于Flink1.12.0版本。
目前该版本的Flink支持的source与sink如下所示
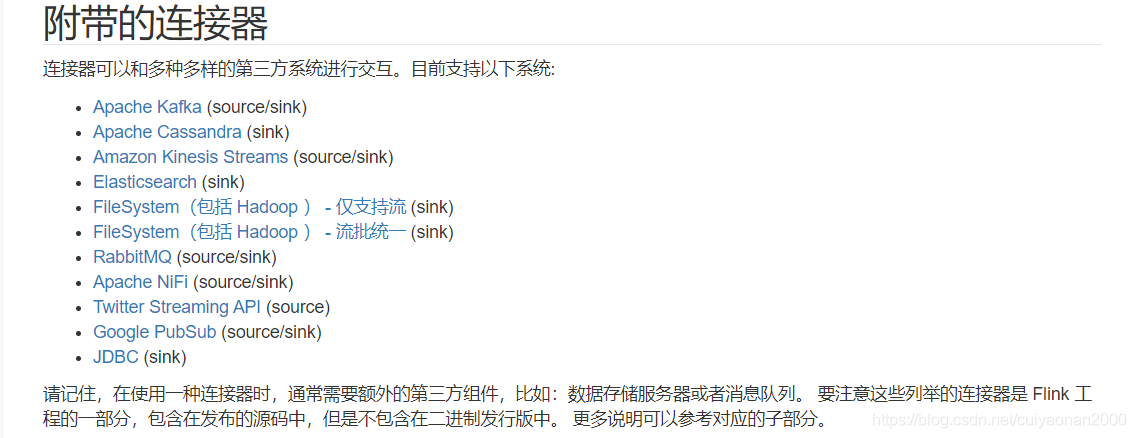
参考资料:
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/try-flink/index.html ------官网安装教程
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/
流定义
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。(如下图所示演示数据流的图像定义)
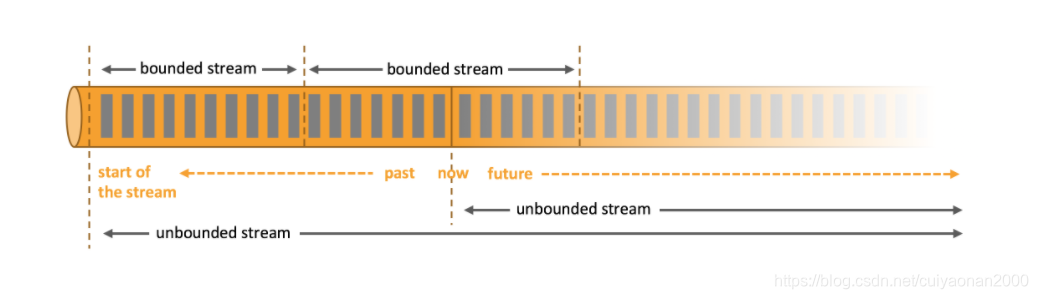
- 批处理:是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
- 流处理: 正相反其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。(应用程序的组成,此句话比较重要cuiyaonan2000@163.com)
通常,程序代码中的 transformation 和 dataflow 中的算子(operator)之间是一一对应的。但有时也会出现一个 transformation 包含多个算子的情况,如下图所示。(算子即我们的处理数据流的程序)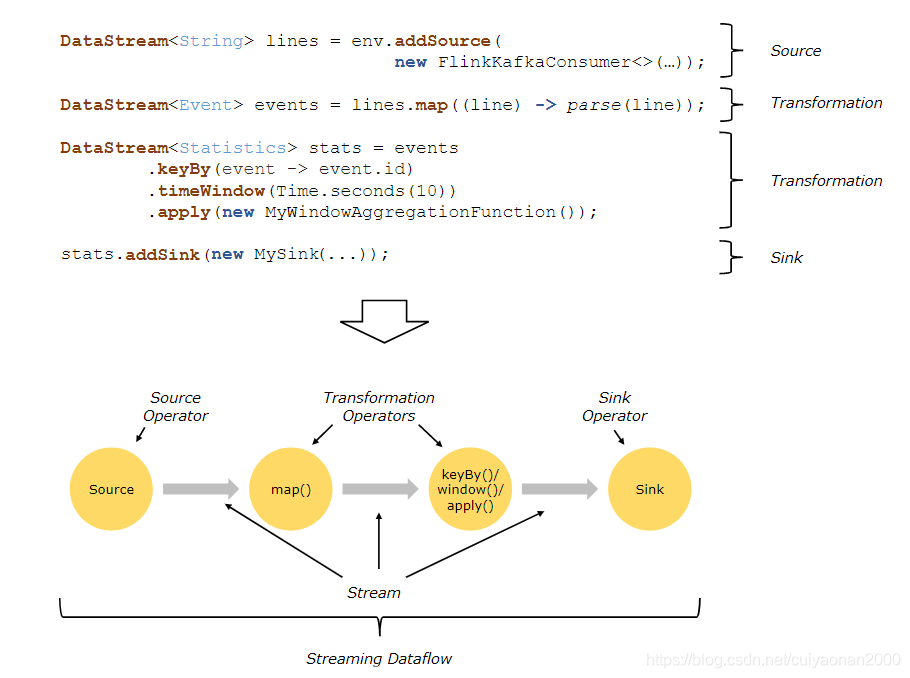
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种数据汇中。(如下图所示)
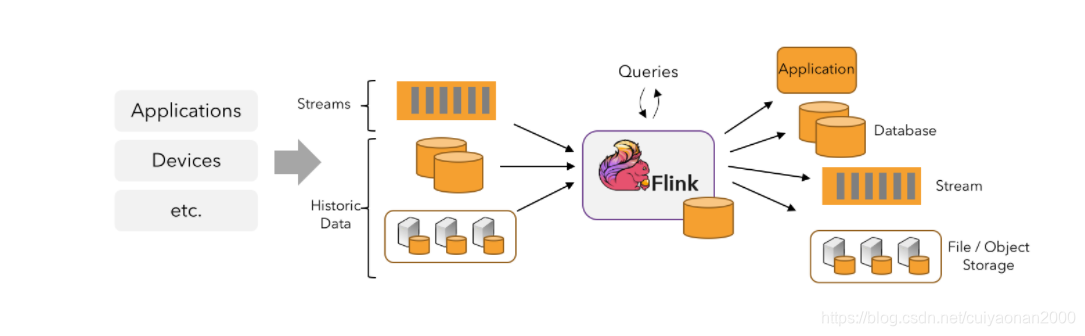
数据流的运转
Flink 程序本质上是分布式并行程序。
在程序执行期间,
- 一个流有一个或多个流分区(Stream Partition),-------------------------------看下图能够明白流分区,其实是把数据拆分,然后放到集群中去计算。
- 每个算子有一个或多个算子子任务(Operator Subtask)。每个子任务彼此独立,并在不同的线程中运行,或在不同的计算机或容器中运行。-------------------------------算子任务可以理解成集群,要不然分布式计算个屁
- 算子子任务数就是其对应算子的并行度。在同一程序中,不同算子也可能具有不同的并行度。-------------------------------并行度 可以理解一个 功能集群的机器数量。
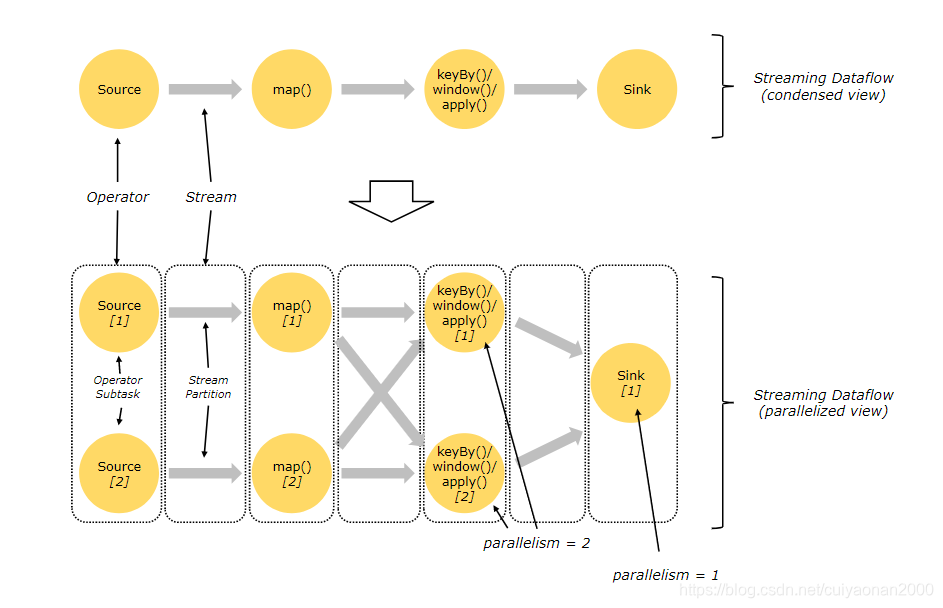
Flink 算子之间可以通过一对一(直传)模式或重新分发模式传输数据:------------------这个就是数据流的方向控制,或者就是我们理解的请求负载均衡的策略cuiyaonan2000@163.com
-
一对一模式(例如上图中的 Source 和 map() 算子之间)可以保留元素的分区和顺序信息。这意味着 map() 算子的 subtask[1] 输入的数据以及其顺序与 Source 算子的 subtask[1] 输出的数据和顺序完全相同,即同一分区的数据只会进入到下游算子的同一分区。
-
重新分发模式(例如上图中的 map() 和 keyBy/window 之间,以及 keyBy/window 和 Sink 之间)则会更改数据所在的流分区。当你在程序中选择使用不同的 transformation,每个算子子任务也会根据不同的 transformation 将数据发送到不同的目标子任务。例如以下这几种 transformation 和其对应分发数据的模式:keyBy()(通过散列键重新分区)、broadcast()(广播)或 rebalance()(随机重新分发)。在重新分发数据的过程中,元素只有在每对输出和输入子任务之间才能保留其之间的顺序信息(例如,keyBy/window 的 subtask[2] 接收到的 map() 的 subtask[1] 中的元素都是有序的)。因此,上图所示的 keyBy/window 和 Sink 算子之间数据的重新分发时,不同键(key)的聚合结果到达 Sink 的顺序是不确定的。
自定义时间流处理---------------在数据流中增加时间戳,保证事件的还原顺序。
对于大多数流数据处理应用程序而言,能够使用处理实时数据的代码重新处理历史数据并产生确定并一致的结果非常有价值。
在处理流式数据时,我们通常更需要关注事件本身发生的顺序而不是事件被传输以及处理的顺序,因为这能够帮助我们推理出一组事件(事件集合)是何时发生以及结束的。例如电子商务交易或金融交易中涉及到的事件集合。
为了满足上述这类的实时流处理场景,我们通常会使用记录在数据流中的事件时间的时间戳,而不是处理数据的机器时钟的时间戳。
有状态流处理
Flink 中的算子可以是有状态的。这意味着如何处理一个事件可能取决于该事件之前所有事件数据的累积结果。
Flink 应用程序可以在分布式群集上并行运行,其中每个算子的各个并行实例会在单独的线程中独立运行,并且通常情况下是会在不同的机器上运行。
有状态算子的并行实例组在存储其对应状态时通常是按照键(key)进行分片存储的。每个并行实例算子负责处理一组特定键的事件数据,并且这组键对应的状态会保存在本地。
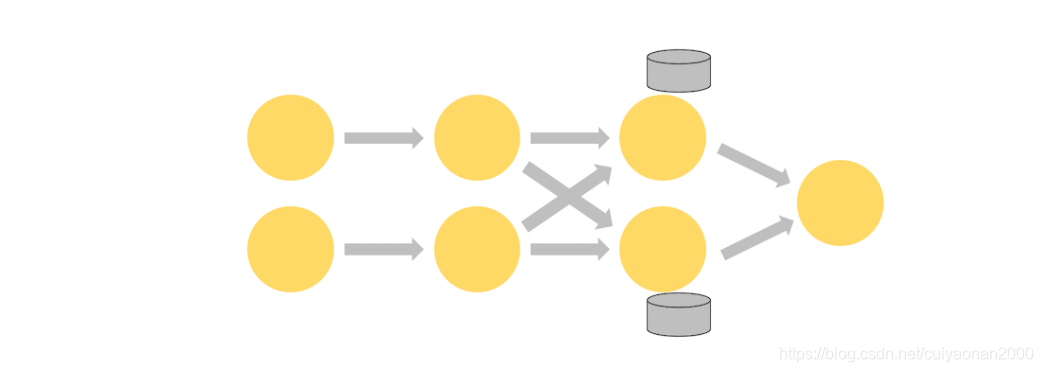
如下图的 Flink 作业,其前三个算子的并行度为 2,最后一个 sink 算子的并行度为 1,其中第三个算子是有状态的,
并且你可以看到第二个算子和第三个算子之间是全互联的(fully-connected),它们之间通过网络进行数据分发。
通常情况下,实现这种类型的 Flink 程序是为了通过某些键对数据流进行分区,以便将需要一起处理的事件进行汇合,然后做统一计算处理。
Flink 应用程序的状态访问都在本地进行,因为这有助于其提高吞吐量和降低延迟。通常情况下 Flink 应用程序都是将状态存储在 JVM 堆上,但如果状态太大,我们也可以选择将其以结构化数据格式存储在高速磁盘中。
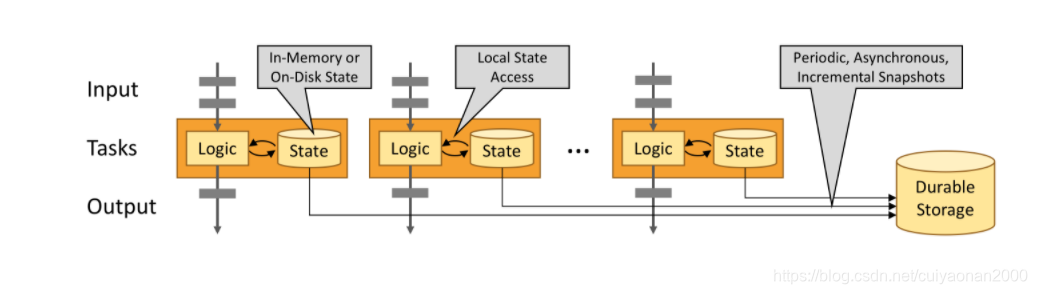
通过状态快照实现的容错
当发生故障时,Flink 作业会恢复上次存储的状态,重置数据源从状态中记录的上次消费的偏移量开始重新进行消费处理。而且状态快照在执行时会异步获取状态并存储,并不会阻塞正在进行的数据处理逻辑。
什么能被转化成流?
Flink 的 Java 和 Scala DataStream API 可以将任何可序列化的对象转化为流。Flink 自带的序列化器有----如下类就是支持序列化的累
- 基本类型,即 String、Long、Integer、Boolean、Array
- 复合类型:Tuples、POJOs 和 Scala case classes
而且 Flink 会交给 Kryo 序列化其他类型。也可以将其他序列化器和 Flink 一起使用。特别是有良好支持的 Avro。
Java tuples 和 POJOs---------------------即如何在Java创建Flink流
Flink 的原生序列化器可以高效地操作 tuples 和 POJOs
Tuples---------貌似是个泛型,属性根据传入参数确定,数量是动态的无线数组Object......
对于 Java,Flink 自带有 Tuple0 到 Tuple25 类型。
- Tuple2<String, Integer> person = Tuple2.of("Fred", 35);
-
- // zero based index!
- String name = person.f0;
- Integer age = person.f1;
POJOs-------------使用自己定义Java的Pojo需要满足的条件
如果满足以下条件,Flink 将数据类型识别为 POJO 类型(并允许“按名称”字段引用):
- 该类是公有且独立的(没有非静态内部类)
- 该类有公有的无参构造函数
- 类(及父类)中所有的所有不被 static、transient 修饰的属性要么是公有的(且不被 final 修饰),要么是包含公有的 getter 和 setter 方法,这些方法遵循 Java bean 命名规范。
示例:
- public class Person {
- public String name;
- public Integer age;
- public Person() {};
- public Person(String name, Integer age) {
- . . .
- };
- }
-
- Person person = new Person("Fred Flintstone", 35);
完整的示例
该示例将关于人的记录流作为输入,并且过滤后只包含成年人。
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.api.common.functions.FilterFunction;
-
- public class Example {
-
- public static void main(String[] args) throws Exception {
- //获取本地环境
- final StreamExecutionEnvironment env =
- StreamExecutionEnvironment.getExecutionEnvironment();
-
- //获取流
- DataStream<Person> flintstones = env.fromElements(
- new Person("Fred", 35),
- new Person("Wilma", 35),
- new Person("Pebbles", 2));
-
- //处理数据
- DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
- @Override
- public boolean filter(Person person) throws Exception {
- return person.age >= 18;
- }
- });
-
- adults.print();
-
- env.execute();
- }
-
- public static class Person {
- public String name;
- public Integer age;
- public Person() {};
-
- public Person(String name, Integer age) {
- this.name = name;
- this.age = age;
- };
-
- public String toString() {
- return this.name.toString() + ": age " + this.age.toString();
- };
- }
- }
程序的启动条件Env
每个 Flink 应用都需要有执行环境,在该示例中为 env。流式应用需要用到 StreamExecutionEnvironment。
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上
JobManager对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。(这句话很重要cuiyaonan2000@163.com。说明任务拆分是在jobmanager上执行的)
注意,如果没有调用 execute(),应用就不会运行。
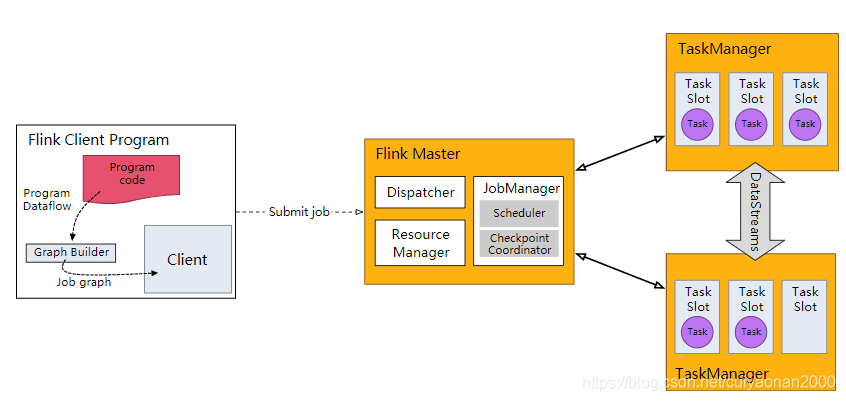
Jobmanager负责拆分任务以及收集任务的执行情况
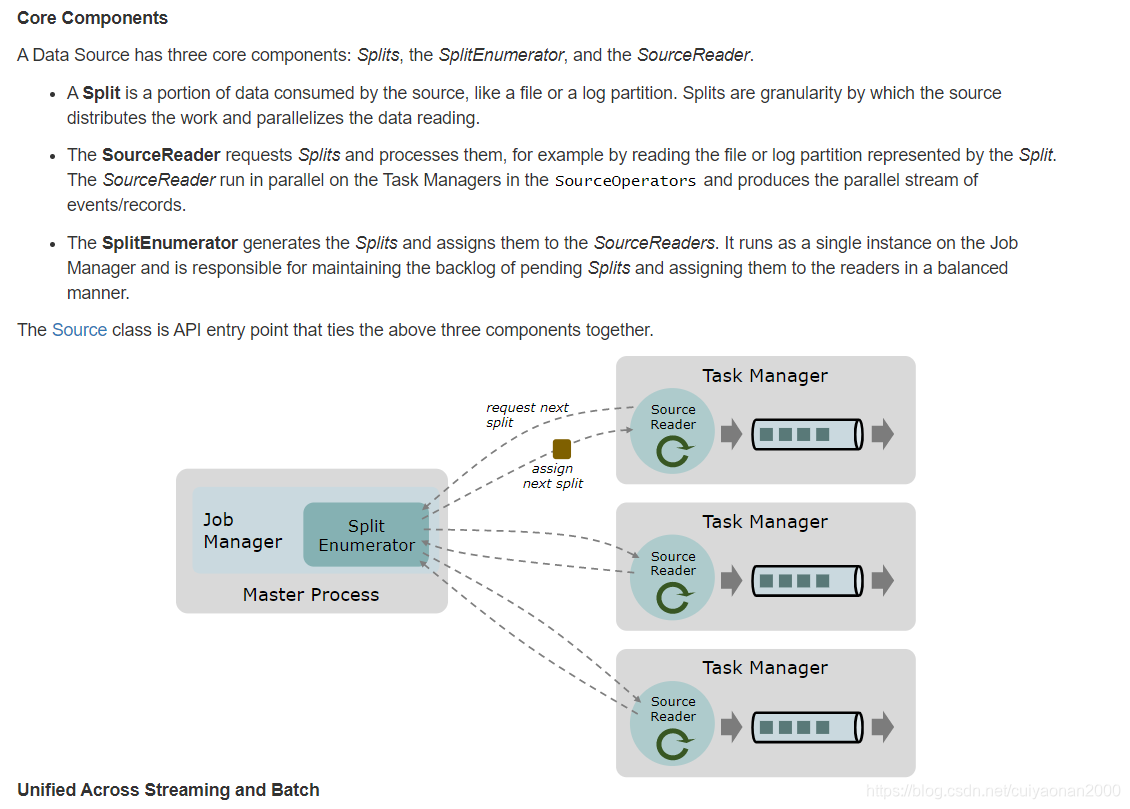
程序中如何获取数据流
在真实的应用中,最常用的数据源是那些支持低延迟,高吞吐并行读取以及重复(高性能和容错能力为先决条件)的数据源,例如 Apache Kafka,Kinesis 和各种文件系统。REST API 和数据库也经常用于增强流处理的能力(stream enrichment)。
- //获取流的方式一
- DataStream<Person> flintstones = env.fromElements(
- new Person("Fred", 35),
- new Person("Wilma", 35),
- new Person("Pebbles", 2));
-
-
- //获取流的方式二
- List<Person> people = new ArrayList<Person>();
-
- people.add(new Person("Fred", 35));
- people.add(new Person("Wilma", 35));
- people.add(new Person("Pebbles", 2));
-
- DataStream<Person> flintstones = env.fromCollection(people);
-
-
-
- //获取流的方式三
- DataStream<String> lines = env.socketTextStream("localhost", 9999)
-
-
-
- //获取流的方式四
- DataStream<String> lines = env.readTextFile("file:///path");
基本的 stream sink-------------sink有很多方式这里仅仅是打印输出
上述示例用 adults.print() 打印其结果到 task manager 的日志中(如果运行在 IDE 中时,将追加到你的 IDE 控制台)。它会对流中的每个元素都调用 toString() 方法。
输出看起来类似于

数据管道 & ETL
无状态的转换
map()
map()中的对象应该继承implements MapFunction<TaxiRide, EnrichedRide> 才能在主流中使用map()方法进行 1个对象转换成另一个对象
- public static class EnrichedRide extends TaxiRide {
- public int startCell;
- public int endCell;
-
- public EnrichedRide() {}
-
- public EnrichedRide(TaxiRide ride) {
- this.rideId = ride.rideId;
- this.isStart = ride.isStart;
- ...
- this.startCell = GeoUtils.mapToGridCell(ride.startLon, ride.startLat);
- this.endCell = GeoUtils.mapToGridCell(ride.endLon, ride.endLat);
- }
-
- public String toString() {
- return super.toString() + "," +
- Integer.toString(this.startCell) + "," +
- Integer.toString(this.endCell);
- }
- }
-
- //这个类的实现接口是重点
- public static class Enrichment implements MapFunction<TaxiRide, EnrichedRide> {
-
- @Override
- public EnrichedRide map(TaxiRide taxiRide) throws Exception {
- return new EnrichedRide(taxiRide);
- }
- }
-
-
- DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
-
- DataStream<EnrichedRide> enrichedNYCRides = rides
- .filter(new RideCleansingSolution.NYCFilter())
- .map(new Enrichment());
-
- enrichedNYCRides.print();
flatmap()
MapFunction 只适用于一对一的转换:对每个进入算子的流元素,map() 将仅输出一个转换后的元素。对于除此以外的场景,你将要使用 flatmap()。
同理flatmap()中的对象应该实现FlatMapFunction<TaxiRide, EnrichedRide>
- DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
-
- DataStream<EnrichedRide> enrichedNYCRides = rides
- .flatMap(new NYCEnrichment());
-
- enrichedNYCRides.print();
-
-
- public static class NYCEnrichment implements FlatMapFunction<TaxiRide, EnrichedRide> {
-
- @Override
- public void flatMap(TaxiRide taxiRide, Collector<EnrichedRide> out) throws Exception {
- FilterFunction<TaxiRide> valid = new RideCleansing.NYCFilter();
- if (valid.filter(taxiRide)) {
- out.collect(new EnrichedRide(taxiRide));
- }
- }
- }
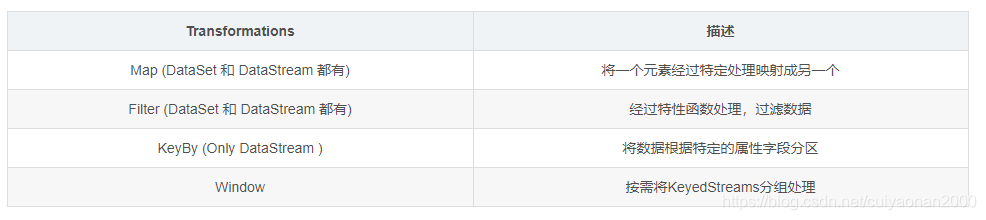
总结下常用的算子(后续可以根据使用情况慢慢增加)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号