redis布隆过滤器
一、布隆过滤器介绍
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构(probabilistic data structure),用于快速判断一个元素是否“可能存在于”某个集合中, 或者“肯定不存在”于该集合中。 它由 Burton Howard Bloom 在 1970 年提出,广泛应用于缓存系统、推荐系统、网络爬虫、垃圾邮件过滤等场景。布隆过滤器 不存储元素本身,而是通过多个哈希函数将元素映射到位数组(bit array)中的若干位置,并将这些位置设为 1。
查询时,只要所有对应位都是 1,就认为“可能存在”;只要有一个位是 0,就“一定不存在”。
优点:节省内存、查询速度快(O(k),k 是哈希函数个数)
缺点:存在误判率(false positive),但不会漏判(false negative)
二、布隆过滤器原理
1、一个长度为 m 的位数组(bit array), 初始所有位为 0。2、k 个独立的哈希函数
每个函数将输入元素映射到 [0, m-1] 范围内的一个整数(即位数组的索引)。
通俗地讲就是新创建的布隆过滤器是一串被置为0的Bit数组(假设有m位),同时声明k个不同的Hash函数生成统一的随机分布(k是一个小于m的常数)。
向布隆过滤器中添加元素时,通过k个Hash函数将元素映射到Bit中的k个点,并将这些位置的值设置为1,一个Bit位可能被不同数据共享
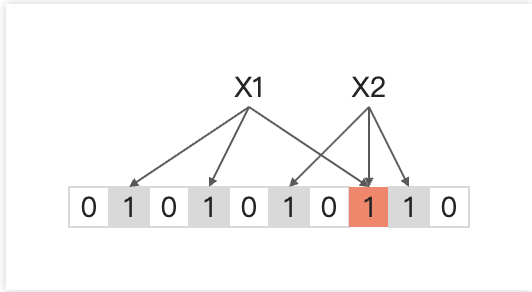
查询元素时,仍通过k个Hash函数得到对应的k个位,判断目标位置是否为1,若目标位置全为1则认为该元素在布隆过滤器内,否则认为该元素不存在,下图展示了在布隆过滤器中查询Y1和Y2是否存在的过程。
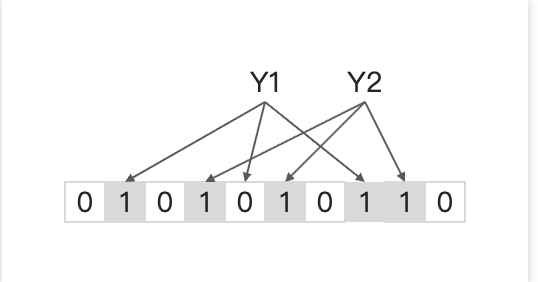
由上图可以发现,虽然从未向布隆过滤器中插入过Y2这个元素(插入的是x1,x2),但是布隆过滤器却判断Y2存在,因此,布隆过滤器是可能存在误判的,即存在假阳性(false positive)。至此,可以得出关于布隆过滤器的几个特性:
- Bit位可能被不同数据共享。
- 存在假阳性(false positive),且布隆过滤器中的元素越多,假阳性的可能性越大,但不存在假阴性(false negative),即不会将存在的元素误判为不存在。
- 元素可以被加入布隆过滤器,但无法被删除,因为Bit位是可以共享的,删除时有可能会影响到其他元素。
为什么会有误判(False Positive)?
因为不同元素经过哈希后,可能恰好命中相同的位。
例如:
元素 A 设置了位 3、7、12
元素 B 设置了位 5、7、15
元素 C 查询时,哈希结果是 3、5、12 → 这些位都被 A 和 B 设为 1 了
→ 布隆过滤器会错误地认为 C 存在(但实际上没插入过)
但反过来:如果某一位是 0,说明没有任何元素设置过它 → 元素一定不存在。
三、布隆过滤器命令
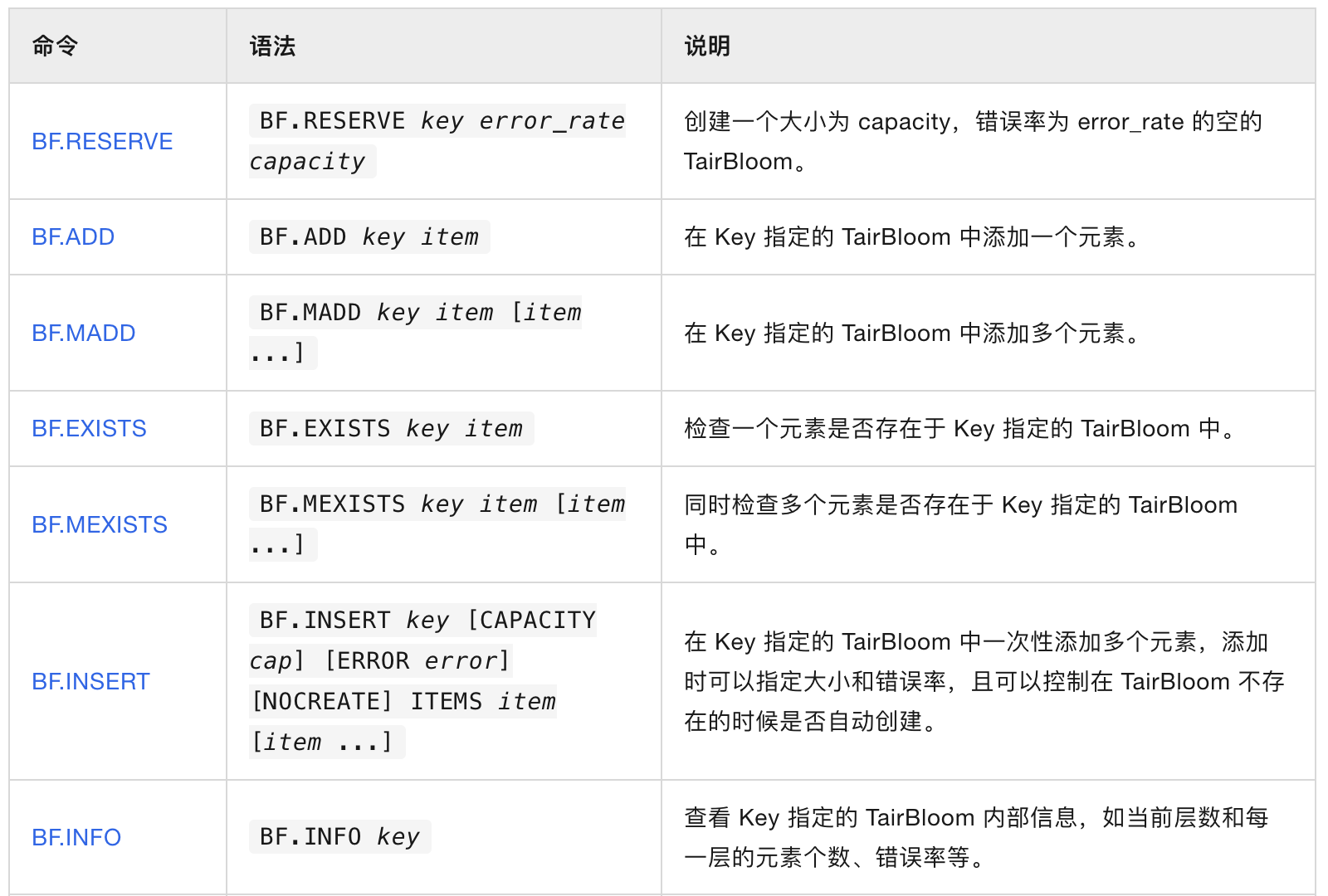

BF.REVERSE解释:
Key:Key名称(TairBloom数据结构),用于指定作为命令调用对象的TairBloom。
error_rate:期望的错误率(False Positive Rate),该值必须介于0和1之间。该值越小,精度越高,TairBloom的内存占用量越大,CPU使用率越高。
capacity:TairBloom的初始容量,即期望添加到TairBloom中的元素的个数。

由于布隆过滤器只能插入新元素且无法删除已有元素,因此布隆过滤器的内存占用量只会增加不会减少。为防止布隆过滤器越来越大,甚至导致Redis内存溢出(Out Of Memory),提供如下使用建议。
拆分业务数据:拆分、细化业务数据,避免将大量数据存入一个布隆过滤器中,这样不仅会导致这个key过大,影响查询性能,同时也会由于这个key中插入了过多数据,大部分的查询流量都会请求到这个key所在的Redis实例上,从而造成热点key,甚至发生访问倾斜的情况。
请拆分业务数据,将数据分散到多个布隆过滤器中,若实例为集群实例,可以将布隆过滤器分散到集群内的各个实例上,均衡内存容量与流量,充分发挥分布式集群的优势。
定期重建:如果业务允许,可以定期重建TairBloom,通过DEL删除TairBloom,从后端数据库拉取数据并重建布隆过滤器,以控制布隆过滤器的大小。
也可以在初期创建多个布隆过滤器,并采用多个布隆过滤器轮转切换的方式实现控制单个布隆过滤器的大小。该方案的优点为仅需创建一次布隆过滤器,无需频繁地重建布隆过滤器,缺点是需要创建多个布隆过滤器,会浪费部分内存空间。
四、在 Redis 中使用布隆过滤器
Redis 本身不内置布隆过滤器,但扩展了布隆过滤器模块,可通过 RedisBloom 模块实现,也可以自己写一个布隆过滤器,下面介绍使用RedisBloom 模块:4.1、下载
方式 1:通过源码编译# 克隆源码
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom
# 编译(需要 gcc 环境)
make
# 编译后生成 redisbloom.so 文件
方式 2:直接下载预编译文件从 RedisBloom 官网( https://redisbloom.io/ )或 GitHub Releases 下载对应系统的 redisbloom.so,
然后把它放到一个目录当中,哪个目录都可以,但一般建议在redis安装目录中新建一个module目录,之后所有的扩展模块都可以放在这个目录中
4.2、 加载模块到 Redis
有两种加载方式,推荐永久加载。(1)临时加载(重启 Redis 后失效)
通过 redis-cli 连接 Redis,执行 MODULE LOAD 命令:
# 替换为你的 redisbloom.so 模块文件所在的实际路径
MODULE LOAD /path/redisbloom.so
(2)永久加载(推荐)
修改 Redis 配置文件 redis.conf,添加 loadmodule 指令:
# 编辑 redis.conf
vim /etc/redis/redis.conf
# 添加以下内容(路径替换为你的 redisbloom.so 所在的实际路径)
loadmodule /path/redisbloom.so
# 修改后重启 Redis 服务
# 验证模块是否加载成功
连接 Redis 后,执行 MODULE LIST 查看已加载的模块,若包含 redisbloom 则表示成功:
MODULE LIST
# 输出示例:1) 1) "name" 2) "redisbloom" ...
参考文献:阿里云tair企业版布隆过滤器文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号