07 2020 档案
摘要:Combiner是MR程序中Mapper和Reducer之外的一种组件(本质是一个Reducer类) Combinr组件的父类就是Reducer Conbimer只有在驱动类里设置了之后,才会运行 Combiner和Reducer的区别在于运行的位置: map sort copy sort(shuf
阅读全文
摘要:@ 排序概述 排序是MapReduce框架中最重要的操作之一。 Map Task和ReduceTask均会默认对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。 黑默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。 对于MapT
阅读全文
摘要:@ 问题引出 要求将统计结果按照条件输出到不同文件中(分区)。 比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区) 默认Partitioner分区 public class HashPartitioner<K,V> extends Partitioner<K,V>{ public int
阅读全文
摘要:封装成帧 封装成帧(framing)就是在一段数据的前后分别添加首部和尾部,然后就构成了一个帧。确定帧的界限。 首部和尾部的一个重要作用就是进行帧定界。 透明传输 若传输的数据是ASCll码中“可打印字符(共95个)“集时,就正常。 若传输的数据不是仅由“可打印字符”组成时,就会出问题。 用字节填充
阅读全文
摘要:1. 阶段定义 MapTask:map >sort map:Mapper.map()中将输出的key-value写出之前 sort:Mapper.map()中将输出的key-value写出之后 2. MapTask工作机制 Read阶段 MapTask通过用户编写的RecordReader,从输入I
阅读全文
摘要:在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题。 自定义InputFormat步骤如下: (1)自定义一个类继承FilelnputFormat。 (2)自定义一个类继承RecordReader,实现一次读取一个完整文
阅读全文
摘要:@ 数据发送模型 数据链路层的信道类型 数据链路层使用的信道主要有以下两种类型: 点对点信道:这种信道使用一对一的点对点通信方式。 广播信道:这种信道使用一对多的广播通信方式,因此过程比较复杂。广播信道上连接的主机很多,因此必须使用专用的共享信道协议来协调这些主机的数据发送。 链路与数据链路 链路(
阅读全文
摘要:xDSL( 用数字技术对现有的模拟电话用户线进行改造,使它能够承载宽带业务。) 标准模拟电话信号的频带被限制在300~3400Hz的范围内,但用户线本身实际可通过的信号频率仍然超过1MHz。 xDSL技术就把0~4kHz低端频谱留给传统电话使用,而**把原来没有被利用的高端频谱留给用户 上网使用。*
阅读全文
摘要:@ 1. 准备阶段 运行Job.waitForCompletion(),先使用JobSubmitter提交Job,在提交之前,会在Job的作业目录中生成以下文件: job.split:当前Job的切片信息,有几个切片对象 job.splitmetainfo:切片对象的属性信息 job.xml:job
阅读全文
摘要:虽然切片数越多,启动的maptask就越多,并行运行执行效率越高。但凡事都有个度,万一切片过多,也会影响执行效率 @ 执行流程 Job-->MRAppMaster-->RM-->调度队列-->NM-->Container-->MapTask 可以看见,从job提交到执行maptask,中间还会经历很
阅读全文
摘要:@ 片大小的计算 long splitSize = computeSplitSize(blockSize, minSize, maxSize); protected long computeSplitSize(long blockSize, long minSize, long maxSize) {
阅读全文
摘要:①获取当前输入目录中所有的文件 ②以文件为单位切片,如果文件为空文件,默认创建一个空的切片 ③如果文件不为空,尝试判断文件是否可切(不是压缩文件,都可切) ④如果文件不可切,整个文件作为1片 ⑤如果文件可切,先获取片大小(默认等于块大小),循环判断 待切部分/ 片大小 > 1.1,如果大于先切去一片
阅读全文
摘要:有一文件,如图所示 每行第一个字段为名字,后面的则为该人的一些信息,所以此时的输入格式应该是以每一行的名字为Key,每一行的其他信息为Value。 KeyValueTextInputFormat 作用: 针对文本文件!使用分割字符,分隔符前的为Key,分隔符后的为value,所以这种输入格式就是将每
阅读全文
摘要:有两个文件: NlineInputFormat 切片策略: 读取配置文件中的参数mapreduce.input.lineinputformat.linespermap,默认为1,以文件为单位,切片每此参数行作为1片! 既然有参数,那就可以修改,设置为每N行切为一片: Configuration co
阅读全文
摘要:复用(multiplexing)是通信技术中的基本概念。 @ 频分复用 FDM(Frequency Division Multiplexing) 用户在分配到一定的频带后,在通信过程中自始至终都占用这个频带。 频分复用的所有用户在同样的时间占用不同的带宽资源(请注意,这里的“带宽”是频率带宽而不是数
阅读全文
摘要:@ 导向传输媒体 导向传输媒体中,电磁波沿着固体媒体传播。 双绞线 屏蔽双绞线STP 无屏蔽双绞线 UTP 同轴电缆 50Ω同轴电缆用于数字传输,由于多用于基带传输,也叫基带同轴电缆 75Ω同轴电缆用于模拟传输,即宽带同轴电缆 光纤 非导向传输媒体 非导向传输媒体就是指自由空间,其中的电磁波传输被称
阅读全文
摘要:如果一个文件的内容不只是简单的单词,而是类似于一个对象那般,有多种属性值,如: 在这个文件中,每一行的内容分别代表:手机号、IP、访问网站、上行流量、下行流量、状态码,现在需要统计每个手机号访问网站的上行流量、下行流量以及它们的总和。由于mapper按照每行进行切片,不妨创建一个bean,封装这些属
阅读全文
摘要:@ 一、准备数据 注意:准备的数据的格式必须是文本,每个单词之间使用制表符分割。编码必须是utf-8无bom 二、MR的编程规范 MR的编程只需要将自定义的组件和系统默认组件进行组合,组合之后运行即可! 三、编程步骤 ①Map阶段的核心处理逻辑需要编写在Mapper中 ②Reduce阶段的核心处理逻
阅读全文
摘要:@ 物理层的基本概念 物理层解决如何在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。 物理层的主要任务 确定与传输媒体的接口的一些特性,即: 机械特性:例接口形状,大小,引线数目 电气特性:例规定电压范围(-5v到+5V) 功能特性:例规定-5V表示0,+5V表示1 过程特性:也
阅读全文
摘要:准备好新的数据节点(DataNode) ①准备机器,配置好JDK、hadoop的环境变量,在hdfs-site.xml和yarn-site.xml文件中分别配置NameNode和ResourceManager所在主机名 ②待服役成功后,启动datanode和nodemanager进程即可 ③服役了新
阅读全文
摘要:MapReduce处理数据的大致流程 ①InputFormat调用RecordReader,从输入目录的文件中,读取一组数据,封装为keyin-valuein对象 ②将封装好的key-value,交给Mapper.map() >将处理的结果写出 keyout-valueout ③ReduceTask
阅读全文
摘要:@ 概念 Job(作业) : 一个MapReduce程序称为一个Job。 MRAppMaster(MR任务的主节点): 一个Job在运行时,会先启动一个进程,这个进程称为MRAppMaster,负责Job中执行状态的监控,容错,和RM申请资源,提交Task等。 Task(任务): Task是一个进程
阅读全文
摘要:从源头上解决,在上传到HDFS之前,就将多个小文件归档 使用tar命令 带上参数-zcvf 示例: tar -zcvf xxx.tar.gz 小文件列表 如果小文件已经上传到HDFS了,可以使用在线归档 使用hadoop archive命令 示例: hadoop archive -archiveNa
阅读全文
摘要:@ 计算机网络体系架构相关概念 IS0--internet standard organzation 国际标准化组织 0SI/RM--Open System Interconnection 开放式系统互联 TCP/IP Suite 因特网事实上的国际标准 Network Protocols 数据交换
阅读全文
摘要: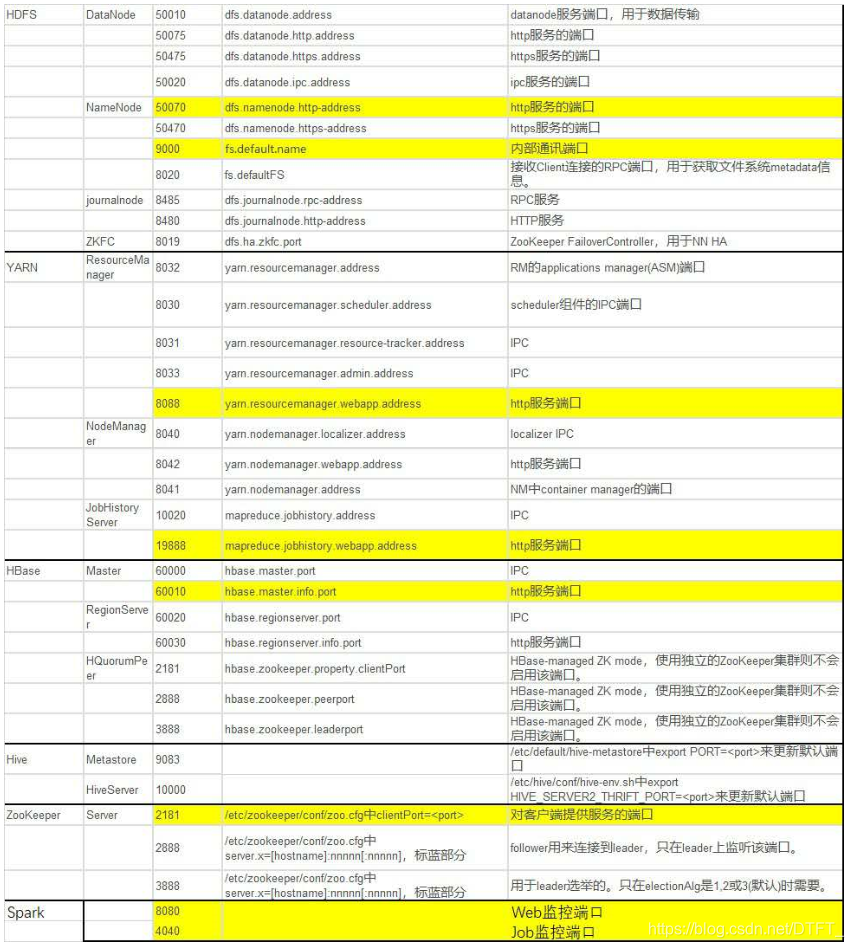
阅读全文
摘要:@ 集群启动顺序: NameNode启动 NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。这个
阅读全文
摘要:1.NN的作用 保存HDFS上所有文件的元数据! 接受客户端的请求! 接受DN上报的信息,给DN分配任务(维护副本数)! 2.元数据的存储 元数据存储在fsiamge文件+edits文件中! fsimage(元数据的快照文件) edits(记录所有写操作的日志文件) NN负责处理集群中所有客户端的请
阅读全文
摘要:1.速率 连接在计算机网络上的主机在数字信道上传送数据位数的速率,也称为data rate或bit rate 单位是单位是b/s,kb/s,Mb/s,Gb/s. 2.带宽 数据通信领域中,数字信道所传送的最高数据率 单位是b/s,kb/s,Mb/s,Gb/s. 3.吞吐量 即在单位时间内通过某个网络
阅读全文
摘要:@ 单点启动 如果集群是第一次启动,需要格式化NameNode hadoop namenode -format 在某一台机器上启动NameNode节点 hadoop-daemon.sh start namenode 在其他机器上启动DataNode节点 hadoop-daemon.sh start
阅读全文
摘要:记住一句话: 节点距离=两个节点到达最近的共同祖先的距离总和 如图: 在同一节点上,它们之间的距离当然是0,2*0=0 在同一机架上的不同节点,它们的共同祖先就是这个机架,而这两个节点到机架的距离都是1,所以这两个节点的距离为1+1=2 在同一集群的不同机架上的节点,它们的共同祖先是集群,而这两个节
阅读全文
摘要:@ 写数据流程 ①服务端启动HDFS中的NN和DN进程 ②客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件 ③NN处理请求,检查客户端是否有权限上传,路径是否合法等 ④检查通过,NN响应客户端可以上传 ⑤客户端根据自己设置的块大小,开始上传第一个块,默认0-128M, NN根
阅读全文
摘要:假如我有一个文件在HDFS上分成了0~3,共四块,那么如何把它们下载到本地并且恢复成完整的文件呢? public class TestCustomUploadAndDownload { private FileSystem fs; private FileSystem localFs; privat
阅读全文
摘要:在之前的总结中,对文件的上传和下载都是默认的全部大小。 那么,如何做到上传文件时,只上传这个文件的一部分或只下载文件的某一部分? 官方实现的代码: InputStream in=null; OutputStream out = null; try { in = srcFS.open(src); ou
阅读全文
摘要:Java部分 1、基础篇 ①怎么理解面对对象? ②重载和重写区别? ③什么是字节码?采用字节码文件最大的好处? ④列举基本数据类型?分别所占字节? ⑤StringBuffer、StringBuild区别? ⑥异常怎么处理? 2、集合篇 ①都有哪些集合? ②Hashmap是线程安全的吗?为什么? ③H
阅读全文
摘要:Linux部分 ①列举你使用的常用指令? ②怎么查看服务是否开启?后面的参数都是什么意思? ③怎么查看服务器内存使用情况? ④日志查看指令? ⑤跨机房怎么传输文件? Hadoop部分 ①怎么搭建一个Hadoop集群? ②Hadoop的Shuffer机制? ③切片概念?文件256M时,几个切片? ④M
阅读全文
摘要:在这里总结了一下使用java对HDFS上文件的操作,比如创建目录、上传下载文件、文件改名、删除…… 首先对一些类名、变量名做出解释说明: FileSystem: 文件系统的抽象基类 FileSystem的实现取决于fs.defaultFS的配置! 有两种实现! LocalFileSystem: 本地
阅读全文
摘要:HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x版本中是128M,老版本中是64M。 那么,问题来了,为什么一个block的大小就是128M呢? 默认为128M的原因,基于最佳传输损耗理论! 不论对磁盘的文件
阅读全文
摘要:HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。 HDFS定义 HDFS(Hadoop Distributed
阅读全文
摘要:一个集群中,每台机器的时间必须保证是同步的! 主要借助linux的ntp服务执行和远程时间服务器的时间同步! 保证当前机器的ntp服务是开机自启动! chkconfig --list ntpd 使用命令: ntpdate -u 时间服务器的地址 比如: ntpdate -u ntp1.aliyun.
阅读全文
摘要:我们经常需要在集群中使用jps命令查看进程状态,而又懒得去每一台机器上分别执行jps命令,这时候就需要一个脚本文件来帮我们做这样的事情! 编写一个名为xcall的脚本文件吧! #!/bin/bash #在集群的所有机器上批量执行同一条命令 if(($#==0)) then echo 请输入您要操作的
阅读全文
摘要:搭集群最麻烦的就是修改配置文件,如果只用修改一个机器上的配置文件,然后用一个脚本就可以把配置文件同步到其他机器上,岂不快哉! 编写一个名为xsync的脚本文件: 作用: 将当前机器的文件,同步到集群所有机器的相同路径下! hadoop102:/A/a , 执行脚本后,将此文件同步到集群中所有机器的
阅读全文
摘要:举例: A机器的a用户,希望在A机器上,使用b用户的身份登录到B机器! ssh b@B 实现步骤: ①A机器的a用户,在A机器上生成一对密钥 ssh-keygen -t rsa,然后三次回车即可。 ②密钥分为公钥和私钥,a用户需要将公钥拷贝到B机器上b用户的家目录下的.ssh隐藏目录下的author
阅读全文
摘要:1. scp(安全拷贝) 又称为全量复制,每次复制都会复制所有文件。 使用: scp -r 源文件用户名A@主机名1:path1 目标文件用户名B@主机名2:path2 -r: 递归,复制目录 执行过程: 在主机1上,使用A用户读取path1的文件 再使用用户B登录到主机2,在主机2的path2路径
阅读全文
摘要:1.规划 Hadoop中的进程在多台机器运行! HDFS: 1个nn+N个DN n个2nn YARN: 1个RM+N个NM 避免单点故障,NN和RM建议分散到多台机器! 注意负载均衡 | hadoop101 | hadoop102 | hadoop103 | |--|--|--| | DN |DN
阅读全文
摘要:登录脚本的执行顺序:【注:仅适用于 bash shell】 Login-Shell 是指登录时,需要提供用户名密码的shell,如:su – user1 , 图形登录, ctrl+alt+F2-6进入的登录界面。 这种Login shell 执行脚本的顺序: 1./etc/profile 【全局pr
阅读全文
摘要:一、分布式HDFS的安装和启动 ①在$HADOOP_HOME/etc/hadoop/core-site.xml文件 <configuration> <property> <name>fs.defaultFS</name> <!-- 告知NN在哪个机器,NN使用哪个端口号接收客户端和DN的RPC请求.
阅读全文
摘要:一、Hadoop的安装 ①Hadoop运行的前提是本机已经安装了JDK,配置JAVA_HOME变量 ②在Hadoop中启动多种不同类型的进程 例如NN,DN,RM,NM,这些进程需要进行通信! 在通信时,常用主机名进行通信! 在192.168.6.100机器上的DN进程,希望访问192.168.6.
阅读全文
摘要:一、Hadoop 1.hadoop的初衷是采用大量的廉价机器,组成一个集群!完成大数据的存储和计算! 2.hadoop历史版本 hadoop 1.x HDFS: 负责大数据的存储 Common: HDFS和MR共有的常用的工具包模块! MapReduce: 负责计算,负责计算资源的申请的调度! 完成
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号