Java8-Stream流
Java8-Stream基础操作
JAVA技术交流群:737698533
在学习Stream之前必须有Lambda,的基础
Stream是Java8的新特性,可以进行对集合进行一些类似SQL的操作,例如筛选,排序,分组等,极大提高编码效率
而操作使用链式编程,只需要在源操作上.xxx()方法即可使用
特点:
- 不是数据结构,不会存储数据
- 惰性求值,中间操作只对操作进行记录,只有执行结束操作时才会进行求值操作
- 不会修改原来数据源,Stream的操作会保存在另一个新的对象中
Stream基础操作分类
| 中间操作 | 终止操作 |
|---|---|
| filter | allMatch |
| limit | anyMatch |
| skip | noneMatch |
| distinct | findFirst |
| map | findAny |
| flatMap | count,max,min |
| sorted | reduce |
| collect |
操作Stream只需要3步 :
- 创建Stream,得到一个数据源,通过例如集合,数组,来获取一个流
- 中间操作对数据进行处理
- 终止操作,执行中间操作,产生结果
Stream的任何操作都是在stream对象上进行的,也就是说,任何Stream操作首先都需要获取到Stream对象
创建Stream流
-
可以通过Collection系列集合提供的stream()串行流或parallelStream并行流来获取流
public void test(){ List list=new ArrayList(); //获取串行流 list.stream(); //获取并行流 list.parallelStream(); }对于串行和并行现在可以简单理解为 串行上的操作是在一个线程中依次完成,而并行是在多个线程上同时执行,我们现在仅需要使用串行流即可
-
通过Arrays中的静态方法stream来获取数组流
public void test(){ User [] users=new User[1]; Stream<User> stream = Arrays.stream(users); } -
通过Stream的静态方法of()
public void test(){ String[] strings=new String[10]; Stream<String> stream = Stream.of(strings); }
那么现在已经获取到Stream流了,我们可以进行类似SQL的操作
为了方便演示,创建Student类
public class Student {
//学生姓名
private String name;
//学生年龄
private int age;
//学生所在年级
private int grade;
//性别,1男0女
private int sex;
//省略构造,get,set,toString方法
}
在类初始化时添加一些数据
private static List<Student> studentList =new ArrayList<>();
//用于下面演示
private static Student student =new Student("小明",7,1,1);
static{
studentList.add(student);
studentList.add(student);
studentList.add(new Student("小花",7,2,0));
studentList.add(new Student("小李",9,3,0));
studentList.add(new Student("小赵",8,3,1));
studentList.add(new Student("小王",7,3,0));
studentList.add(new Student("小亮",6,2,1));
studentList.add(new Student("小光",6,1,0));
}
中间操作
筛选和切片
- filter 从流中排除某些元素
- limit 类似mysql的limit 指定元素最大数量,具有短路功能,可以提高效率
- skip(n) 跳过元素,返回跳过n个元素,不足n个返回一个空流
- distinct 筛选 通过流所生成元素的hashcode和equals去除重复元素
首先来看filter 从流中排除元素
我们来看一下filter方法参数
Stream<T> filter(Predicate<? super T> predicate);
//看一下传入参数,函数式接口,可以使用Lambda
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
}
那也就说明,我们可以自己定义判断条件,结果返回一个boolean类型即可
public void test(){
Stream<Student> studentStream = studentList.stream()
.filter((x) -> x.getAge() > 8);
System.out.println("未执行终止操作前");
studentStream.forEach(System.out::println);
}
//结果,很明显只有一个小李年龄大于8岁
未执行终止操作前
User{name='小李', age=9, grade='3', sex=0}
关于上面两个来解释一下,可以理解为x就是每次循环studentList中那个Student对象,使用lambda简化了代码而已,同时我们证明了所有的中间操作都是惰性求值,只有执行到终止方法才会真正的进行操作
如果不使用Lambda就是下面这样,非常的麻烦
studentList.stream()
.filter(new Predicate(){
@Override
public boolean test(Object o) {
Student student=(Student) o;
return student.getAge()>8;
}
})
.forEach(new Consumer() {
@Override
public void accept(Object o) {
System.out.println(o);
}
});
接下来看limit,类似于SQL中的limit,但是没有起始值,只有需要的条数
limit具有短路功能,可以提高效率, 假如list中有很多条数据,limit只需要找到设置的数量就停止查找,减少了资源的浪费
public void test3() {
studentList.stream()
.limit(2)
.forEach(System.out::println);
}
//结果,只显示两条
User{name='小明', age=7, grade='1', sex=1}
User{name='小明', age=7, grade='1', sex=1}
skip(n) 跳过n条数据,如果流中数据不足n条,那么返回个空流, 这里的空流指流里没有数据,而不是返回null
public void test3() {
studentList.stream()
.skip(6)
.forEach(System.out::println);
}
//结果,只获取到数据的最后两条
User{name='小亮', age=6, grade='2', sex=1}
User{name='小光', age=6, grade='1', sex=0}
//====我们来设置跳过条数大点,让它返回一个空流看看
//因为返回的是个空流,forEach看不到效果,我们使用另一个中间操作count,它返回的是流中数据的数量
public void test3() {
long count = studentList.stream()
.skip(100)
.count();
System.out.println(count);
}
//结果 0
distinct 筛选,通过流所生成元素的hashcode和equals去除重复元素
public void test4() {
studentList.stream()
//排除重复
.distinct()
.forEach(System.out::println);
}
//结果,只有一个小明,我们在开始时添加了两个同一对象的小明,distinct方法根据hashcode和equals去除了
//其他Student数据....就不展示了
映射
map方法,这个map不是我们理解的那个类似于hashMap,它的作用是接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射为一个新的元素
什么意思呢,来看下面的例子,例如数组中存放了学生的英文名字,我们需要把名字全部转换为大写
@Test
public void test5() {
String[] names = new String[]{"jame", "joker", "jack"};
Arrays.stream(names)
.map((name)-> name.toUpperCase())
.forEach(System.out::println);
}
//结果
JAME
JOKER
JACK
可以看到,所有的名字都转换为了大写,那么意味着数组中所有的字符串都使用了toUpperCase()转大写方法
我们来看下面的这个例子
//这个方法将student对象转换为一个Stream<Student >流
public static Stream<Student> getStudentStream(Student student){
List<Student> studentList=new ArrayList<>();
studentList.add(student);
return studentList.stream();
}
//这个方法里调用getStudentStream方法,将每一个学生类都包装为Stream类型
public void test() {
Stream<Stream<Student>> streamStream = studentList.stream()
.map(MyStream::getStudentStream);
streamStream.forEach((ss)->{
ss.forEach(System.out::println);
});
}
//结果
User{name='小明', age=7, grade='1', sex=1}
User{name='小明', age=7, grade='1', sex=1}
.....
可以看到在从Stream中获取Student对象时很麻烦,有简单点的方法吗?当然有,来看下面这个方法
flatMap 方法接收一个函数作为参数,将流中每个值转换为另一个流,然后把所有流连接为一个流
还是上面那个例子,我们将map替换为flatMap方法,结果和上面一致就不展示了
public void test() {
studentList.stream()
.flatMap(MyStream::getStudentStream)
.forEach(System.out::println);
}
什么原理呢?我们上面的方法getStudentStream调用完成后每一个学生对象都变为一个流,但是它们还是在最初的studentList的流中,类似套娃,流中还有一个流,而flatMap就是将最初的流中的所有流的数据都提取到最初的流中,形成一个流
比如背包中有一个钱包,钱包里面有钱,我们打开背包,然后打开钱包才能拿到钱,而现在flatMap把钱包中的钱都拿出来放入了背包中,我们只需要打开背包即可拿到
排序
sorted()如果不传入参数,则根据自然排序
public void test() {
studentList.stream()
.sorted()
.forEach(System.out::println);
}
我们启动测试,出现了异常
java.lang.ClassCastException: com.jame.basics.stream.Student cannot be cast to java.lang.Comparable
为什么呢?原来sorted方法的自然排序会调用Comparable接口的compareTo方法,而我们的Student根本没有实现这个接口,我们来实现一下,只是个简单的判断,判断了年龄和年级
@Override
public int compareTo(Object o) {
Student student = (Student) o;
if (student.getAge() > this.getAge())
return 1;
if (student.getGrade() > this.getGrade())
return 1;
return -1;
}
那么我们再来试一下sorted方法,看一下结果
User{name='小李', age=9, grade='3', sex=0}
User{name='小赵', age=8, grade='3', sex=1}
User{name='小王', age=7, grade='3', sex=0}
User{name='小花', age=7, grade='2', sex=0}
User{name='小明', age=7, grade='1', sex=1}
User{name='小明', age=7, grade='1', sex=1}
User{name='小亮', age=6, grade='2', sex=1}
User{name='小光', age=6, grade='1', sex=0}
可以看到已经进行降序的排序了,如果想要升序排序只需要修改Student中的compareTo方法即可
那么除了实现Comparabl接口来进行排序,还能有其他办法吗? 还有一个办法
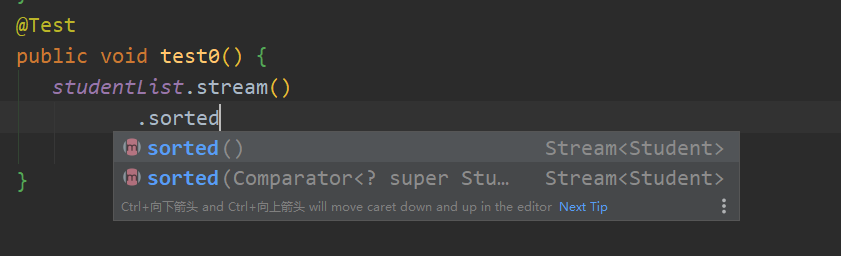
我们看到除了使用无参,还有个构造可以传入一个lambda,我们可以在lambda中定义排序规则
public void test() {
studentList.stream()
.sorted((s1,s2)->{
if(s1.getSex()>s2.getSex())
return 1;
return -1;
})
.forEach(System.out::println);
}
//结果
User{name='小光', age=6, grade='1', sex=0}
User{name='小王', age=7, grade='3', sex=0}
User{name='小李', age=9, grade='3', sex=0}
User{name='小花', age=7, grade='2', sex=0}
User{name='小亮', age=6, grade='2', sex=1}
User{name='小赵', age=8, grade='3', sex=1}
User{name='小明', age=7, grade='1', sex=1}
User{name='小明', age=7, grade='1', sex=1}
我们定义了根据性别排序,女生排在前面
终止操作
所有的终止操作使用后会直接返回结果,后面不允许在进行任何操作
查找与匹配
allMatch 查找所有元素是否符合条件
//判断所有人的年龄是否都等于8
public void test10(){
boolean b = studentList.stream()
.allMatch((x) -> x.getAge() == 8);
}
//结果 false
anyMatch 查找是否有一个符合条件
//判断是否有一个学生年龄为8
public void test10(){
boolean b = studentList.stream()
.anyMatch((x) -> x.getAge() == 8);
}
//结果 true
noneMatch 查找是否有不符合条件的 全都不满足才会返回true
//判断是否有年龄不为8的
public void test10(){
boolean b = studentList.stream()
.noneMatch((x) -> x.getAge() == 8);
System.out.println(b);
}
//false 双重否定就是肯定,也就是说学生中有年龄为8岁的
findFirst 返回第一个元素
public void test10(){
Optional<Student> first = studentList.stream()
.findFirst();
System.out.println(first.get());
}
//结果 User{name='小明', age=7, grade='1', sex=1}
//为什么返回的是一个Optional呢?我们可以简单理解为Optional就是对Student的一个包装
//因为在Stream中,只要可能出现null的地方,都会返回一个包装类
findAny 返回任意一个元素
public void test10(){
Optional<Student> first = studentList.stream()
.findAny();
System.out.println(first.get());
}
//这个方法一般和filter 方法一起使用,单独使用的话一般返回的都是第一个对象
count 返回Stream流中总数
public void test11() {
long count = studentList.stream()
.count();
System.out.println(count);
}
//结果 8
max 返回流中最大对象,我们可以自定义判断条件
//这里我们使用学生类的年龄作为判断条件
public void test10() {
Optional<Student> student = studentList.stream()
.max((s1, s2) -> {
if (s1.getAge() > s2.getAge())
return 1;
return -1;
});
System.out.println(student.get());
}
//结果 User{name='小李', age=9, grade='3', sex=0}
min 返回流中最小对象 同样,我们也可以自定义判断的条件
//使用学生类的年级来判断
public void test12() {
Optional<Student> student = studentList.stream()
.min((s1, s2) -> {
if (s1.getGrade() > s2.getGrade())
return 1;
return -1;
});
System.out.println(student.get());
}
//结果 User{name='小明', age=7, grade='1', sex=1}
归约
reduce 可以将流中元素反复结合起来,得到一个值,来看下面例子
public void test15() {
List<Integer> list=new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
Optional<Integer> reduce = list.stream()
.reduce((x, y) -> {
System.out.println(x+"=="+y);
return x+y;
});
System.out.println(reduce.get());
}
//结果
x:1==y:2
x:3==y:3
x:6==y:4
10
我们可以清楚的看到第一次进入这个方法时,流中的第一条数据赋值给了x,而y赋值了第2条数据,当执行完一遍后将结果赋值给了x,y的数据则依次迭代下去
还有一个注意的点: 返回的类型可能为空,所以Stream使用了Optional来包装
reduce还可以设置起始值
public void test15() {
List<Integer> list=new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
Integer reduce = list.stream()
.reduce(5, (x, y) -> {
System.out.println("x:" + x + "==y:" + y);
return x + y;
});
System.out.println(reduce);
}
//结果
x:5==y:1
x:6==y:2
x:8==y:3
x:11==y:4
15
当设置起始值后,第一次x的值为设置的起始值,而y则为流中第一条数据的值,以后的遍历每次都会把return的值赋值给x,y的值则根据流中得数据迭代赋值
我们可以看到返回的类型已经不是Optional,原因也可以想到,因为赋值了起始值,所以不用怕传入的流中没有数据了
下面是一个小例子,用一个Student对象来保存整个学生集合中年龄最大的值,班级最大的值
public void test13() {
Student s = new Student();
Optional<Student> reduce = studentList.stream()
.reduce((x, y) -> {
if (x.getAge() < y.getAge())
s.setAge(y.getAge());
if (x.getGrade() < y.getGrade())
s.setGrade(y.getGrade());
return s;
});
System.out.println(reduce.get());
//结果 User{name='null', age=9, grade='3', sex=0}
如果不太理解可以自己试试
收集
如果我们想通过Stream流来获取List,Map,Set怎么办呢?
我们可以通过collect方法,将流转换为其他形式,接收一个Collector接口的实现用于给Stream中元素做总汇的方法
例如我们想把所有学生名字转换为一个Set集合
可以看到需要一个Collector收集器接口来进行需要的收集操作,而JDK提供了一个Collectors的工具类来提供不同的收集操作

public void test16() {
Set<String> nameSet = studentList.stream()
//map接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射为一个新的元素
//而这个函数是getName,可以理解为每个对象都调用getName方法,那么返回的就全都是一个String类型的
.map(Student::getName)
//toSet(),将结果收集为一个Set集合
.collect(Collectors.toSet());
for (String s : nameSet) {
System.out.println(s);
}
}
//结果小光
小明
小李
....
类似的操作还有toList,就不再演示,也可以使用toCollection来生成Collection接口类型下的其他集合
public void test16() {
studentList.stream()
.map(Student::getName)
.collect(Collectors.toCollection(HashSet::new));
}
也可以通过收集器来获取平均值
public void test16() {
Double sAveragin = studentList.stream()
//还有averagingInt averagingLong 就是结果类型不同,一个为int 一个为long
.collect(Collectors.averagingDouble(Student::getAge));
System.out.println(sAveragin);
}
//结果 7.125
获取总和
public void test16() {
Double sAveragin = studentList.stream()
//和上面获取平均值一样,还有不同的返回类型,类似summingInt等等
.collect(Collectors.summingDouble(Student::getAge));
System.out.println(sAveragin);
}
//结果 57.0
分组
类似于SQL的分组,那么它的返回类型肯定是一个map,该怎么写呢?来看下面的例子
//我们根据年龄分组
public void test17() {
Map<Integer, List<Student>> collect = studentList.stream()
.collect(Collectors.groupingBy(Student::getAge));
Set<Integer> integers = collect.keySet();
for (Integer integer : integers) {
System.out.println("key:"+integer+"===value:"+collect.get(integer));
}
}
//结果
key:6===value:[User{name='小亮', age=6, grade='2', sex=1}, User{name='小光', age=6, grade='1', sex=0}]
key:7===value:[User{name='小明', age=7, grade='1', sex=3}, User{name='小明', age=7, grade='1', sex=3}, User{name='小花', age=7, grade='2', sex=0}, User{name='小王', age=7, grade='3', sex=0}]
key:8===value:[User{name='小赵', age=8, grade='3', sex=1}]
key:9===value:[User{name='小李', age=9, grade='3', sex=0}]
多级分组
比如我们先按照年级分组,然后根据性别分组该怎么办呢?这时候就需要使用多级分组了

我们可以看到,这个Collectors.groupingBy()方法中还可以再传入一个Collector对象,一切都明白了,再写一个收集器放入就可以了,来看下面例子
public void test18() {
Map<Integer, Map<Integer, List<Student>>> map = studentList.stream()
.collect(Collectors.groupingBy(
(x) -> x.getGrade(),
Collectors.groupingBy((y) -> y.getSex())
));
Set<Integer> keySet = map.keySet();
for (Integer k : keySet) {
System.out.println("年级为:"+k);
Map<Integer, List<Student>> map1 = map.get(k);
Set<Integer> keySet1 = map1.keySet();
for (Integer k1 : keySet1) {
System.out.print("性别:"+k1);
System.out.println(map1.get(k1));
}
}
}
//结果
年级为:1
性别:0[User{name='小光', age=6, grade='1', sex=0}]
性别:1[User{name='小明', age=7, grade='1', sex=1}, User{name='小明', age=7, grade='1', sex=1}]
年级为:2
性别:0[User{name='小花', age=7, grade='2', sex=0}]
性别:1[User{name='小亮', age=6, grade='2', sex=1}]
年级为:3
性别:0[User{name='小李', age=9, grade='3', sex=0}, User{name='小王', age=7, grade='3', sex=0}]
性别:1[User{name='小赵', age=8, grade='3', sex=1}]
如果有多个条件,只需要在后面添加Collectors.groupingBy即可,不过条件多了取的时候就非常麻烦了
我们也可以根据数值自己设置key的值,需要注意的是key的类型必须和当前分组的类型一致
public void test18() {
Map<Integer, Map<Integer, List<Student>>> map = studentList.stream()
.collect(Collectors.groupingBy(
(x) -> {
if(x.getGrade()==1){
return 111;
}else if(x.getGrade()==2){
return 222;
}else {
return 333;
}
},
Collectors.groupingBy((y) -> y.getSex())
));
Set<Integer> keySet = map.keySet();
for (Integer k : keySet) {
System.out.println("最外层k的值:"+k);
Map<Integer, List<Student>> map1 = map.get(k);
Set<Integer> keySet1 = map1.keySet();
for (Integer k1 : keySet1) {
System.out.println(map1.get(k1));
}
}
}
//结果
最外层k的值:333
[User{name='小李', age=9, grade='3', sex=0}, User{name='小王', age=7, grade='3', sex=0}]
[User{name='小赵', age=8, grade='3', sex=1}]
最外层k的值:222
[User{name='小花', age=7, grade='2', sex=0}]
[User{name='小亮', age=6, grade='2', sex=1}]
最外层k的值:111
[User{name='小光', age=6, grade='1', sex=0}]
[User{name='小明', age=7, grade='1', sex=3}, User{name='小明', age=7, grade='1', sex=3}]
partitioningBy 我们还可以通过某些判断根据true和false来分组
public void test20() {
Map<Boolean, List<Student>> map = studentList.stream()
.collect(Collectors.partitioningBy((x) -> x.getGrade() >= 2));
Set<Boolean> booleans = map.keySet();
for (Boolean aBoolean : booleans) {
System.out.println("年级是否大于等于2年级:"+aBoolean);
List<Student> studentList = map.get(aBoolean);
for (Student student : studentList) {
System.out.println(student);
}
}
}
//结果
年级是否大于等于2年级:false
User{name='小明', age=7, grade='1', sex=3}
User{name='小明', age=7, grade='1', sex=3}
User{name='小光', age=6, grade='1', sex=0}
年级是否大于等于2年级:true
User{name='小花', age=7, grade='2', sex=0}
User{name='小李', age=9, grade='3', sex=0}
User{name='小赵', age=8, grade='3', sex=1}
User{name='小王', age=7, grade='3', sex=0}
User{name='小亮', age=6, grade='2', sex=1}
summarizingInt 可以直接获取所有元素的某一项数值得最大值,最小值,平均值,总和,我们一起来看下面的例子
public void test21() {
IntSummaryStatistics collect = studentList.stream()
.collect(Collectors.summarizingInt((x)->x.getAge()));
System.out.println("学生年龄的最大值:"+collect.getMax());
System.out.println("学生年龄的最小值:"+collect.getMin());
System.out.println("学生年龄的平均值:"+collect.getAverage());
System.out.println("学生年龄的总和:"+collect.getSum());
}
//结果
学生年龄的最大值:9
学生年龄的最小值:6
学生年龄的平均值:7.125
学生年龄的总和:57
还有类似的例如summarizingDouble,summarizingLong,只不过是返回的类型不同,这里不再展示
连接操作
可以通过join方法将结果收集在一起,下面例子
public void test22() {
String collect = studentList.stream()
.map(Student::getName)
.collect(Collectors.joining());
System.out.println(collect);
}
//结果 小明小明小花小李小赵小王小亮小光
还可以设置分割符,开头符号,结尾符号
public void test22() {
String collect = studentList.stream()
.map(Student::getName)
.collect(Collectors.joining(",","我是开头符号","我是结尾符号"));
System.out.println(collect);
}
//结果
我是开头符号小明,小明,小花,小李,小赵,小王,小亮,小光我是结尾符号
到此,Stream的基本使用就完成了,感谢阅读
本文仅个人理解,如果有不对的地方欢迎评论指出或私信,谢谢٩(๑>◡<๑)۶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号