PyTorch 搭建卷积神经网络
关于卷积神经网络的理论基础不再详细说明,具体可见 卷积神经网络CNN。
1 卷积层
import torch in_channels, out_channels = 5, 10 width, heigh = 100, 100 kernal_size = 3 batch_size = 1 # PyTorch中所有输入数据都是小批量处理 input = torch.randn(batch_size, in_channels, width, heigh) conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=kernal_size) output = conv_layer(input) print(input.shape) print(output.shape) print(conv_layer.weight.shape)
输出:
torch.Size([1, 5, 100, 100]) torch.Size([1, 10, 98, 98]) torch.Size([10, 5, 3, 3])
这里的输入为 5 通道的 100*100 大小图像,该卷积层包括 10 个卷积核,每个卷积核为 5 通道的 3*3 大小,因此输出为 10 通道的 98*98 大小图像。
输入的通道数就是卷积核的通道数,输出的通道数就是卷积核的个数。
如果不想改变图像大小,可以使用 padding 填充图像:
import torch input = [3, 4, 6, 5, 7, 2, 4, 6, 8, 2, 1, 6, 7, 8, 4, 9, 7, 4, 6, 2, 3, 7, 5, 4, 1] input = torch.Tensor(input).view(1, 1, 5, 5) conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False) kernal = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]).view(1, 1, 3, 3) conv_layer.weight.data = kernal output = conv_layer(input) print(output)
输出:
tensor([[[[ 91., 168., 224., 215., 127.], [114., 211., 295., 262., 149.], [192., 259., 282., 214., 122.], [194., 251., 253., 169., 86.], [ 96., 112., 110., 68., 31.]]]], grad_fn=<ThnnConv2DBackward>)
还可以设置歩长 stride :
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)
2 池化层
import torch input = [3, 4, 6, 5, 2, 4, 6, 8, 1, 6, 7, 8, 9, 7, 4, 6] input = torch.Tensor(input).view(1, 1, 4, 4) maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2) output = maxpooling_layer(input) print(output)
输出:
tensor([[[[4., 8.],
[9., 8.]]]])
一般不会改变通道数。
2 卷积神经网络
我们构建一个如下图所示的网络来训练手写数字集 MNIST
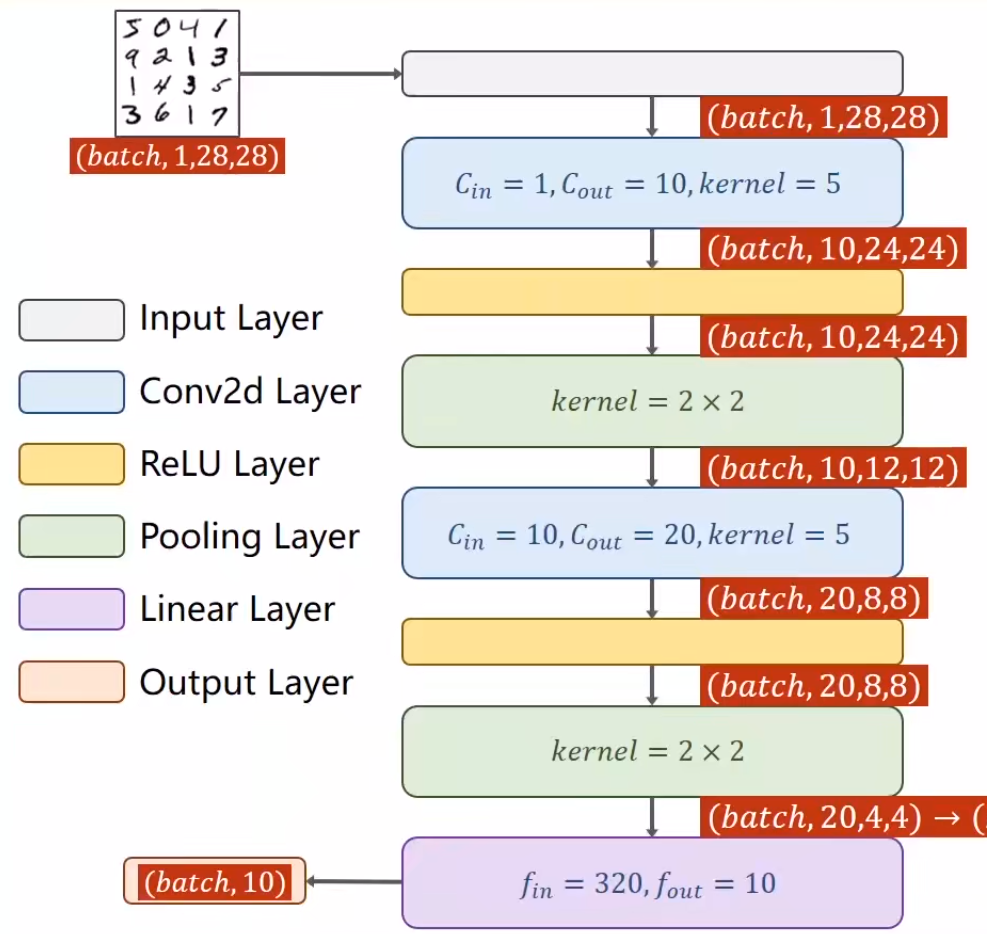
完整代码如下:
import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F import torch.optim as optim batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, transform=transform, download=True) test_dataset = datasets.MNIST(root='../dataset/mnist', train=False, transform=transform, download=True) train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) self.pooling = torch.nn.MaxPool2d(2) self.fc = torch.nn.Linear(320, 10) def forward(self, x): batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # flatten x = self.fc(x) return x model = Net() criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300)) running_loss = 0.0 def test(): correct = 0 total = 0 with torch.no_grad(): # 测试不需要计算梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total)) if __name__ == '__main__': for epoch in range(100): train(epoch) test()
如何使用 GPU 训练神经网络:
1. 将模型迁移到 GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device)
2. 将数据迁移到 GPU
inputs, target = inputs.to(device), target.to(device)
完整代码如下:
import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F import torch.optim as optim batch_size = 64 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, transform=transform, download=True) test_dataset = datasets.MNIST(root='../dataset/mnist', train=False, transform=transform, download=True) train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) self.pooling = torch.nn.MaxPool2d(2) self.fc = torch.nn.Linear(320, 10) def forward(self, x): batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # flatten x = self.fc(x) return x model = Net() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data inputs, target = inputs.to(device), target.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300)) running_loss = 0.0 def test(): correct = 0 total = 0 with torch.no_grad(): # 测试不需要计算梯度 for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy on test set: %d %%' % (100 * correct / total)) if __name__ == '__main__': for epoch in range(100): train(epoch) test()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号