(2)torch.nn
1.Conv2d
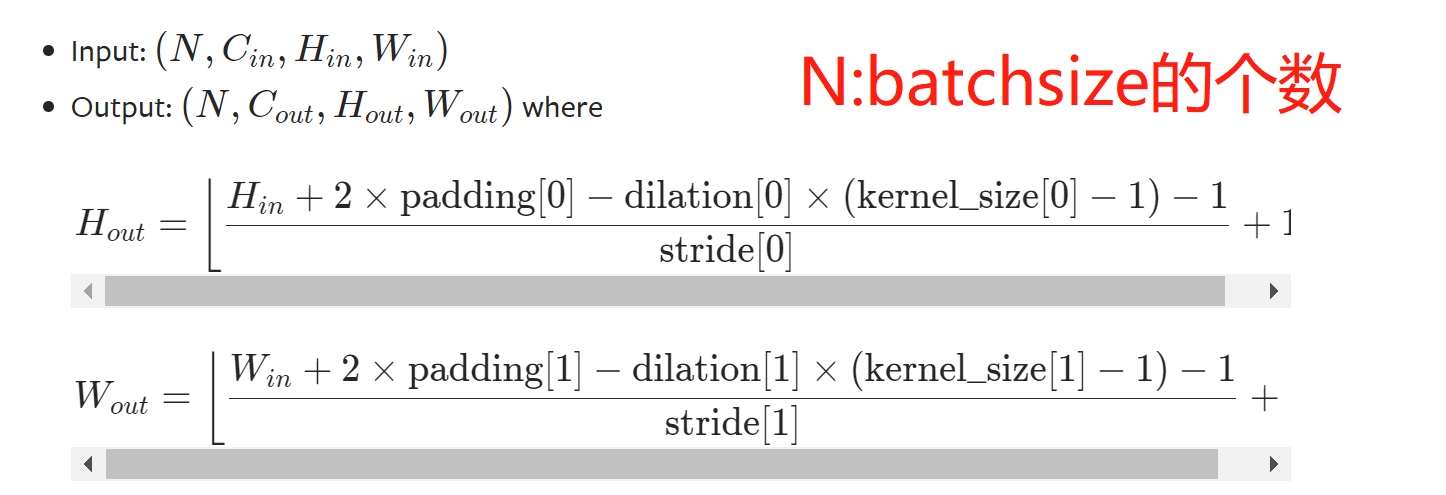
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
所谓channel:
- 最初输入图片样本的channels,取决于图片类型,如RGB 3通道
- 卷积操作完成后输入的out_channels,取决于卷积核的数量,并且此次卷积后的out_channels会作为下一次卷积时的卷积核的in_channels
import torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("./datasets", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64) class Qian(nn.Module): def __init__(self): super(Qian, self).__init__() self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=(3, 3), stride=(1, 1), padding=0) def forward(self, x): x = self.conv1(x) return x
qian = Qian() # print(qian) writer = SummaryWriter("log") step = 0 for data in dataloader: imgs, targets = data output = qian(imgs) print(imgs.shape) print(output.shape) #input:torch.Size([64, 3, 32, 32]) writer.add_images("input", imgs, step) #output:torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]改回3个通道显示图片 output = torch.reshape(output, (-1, 3, 30, 30))#-1表示自动计算batchsize是多少 writer.add_images("output", output, step) step = step + 1 writer.close()
注意forward()和init()同级,也不要拼错forward!!
2.MaxPool2d
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
ceil_mode:若为False,向下取整,反之向上取整
class Qian(nn.Module): def __init__(self): super(Qian, self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False) def forward(self, x): x = self.maxpool1(x) return x
3.ReLu&Sigmoid
class Qian(nn.Module): def __init__(self): super(Qian, self).__init__() # self.relu1 = ReLU() self.sigmoid1 = Sigmoid() def forward(self, input): # output = self.relu1(input) output = self.sigmoid1(input) return output
4.Linear

torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
上图in_features=d, out_features=L, bias=True
用于设置网络中的全连接层,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。
若全连接层的前一层输出为torch.size([64, 3, 32, 32]) --->torch.size([1, 1, 1, 196608])--->可利用output = torch.flatten(imgs)得到output的size
5.Sequential
- CIFAR10模型结构
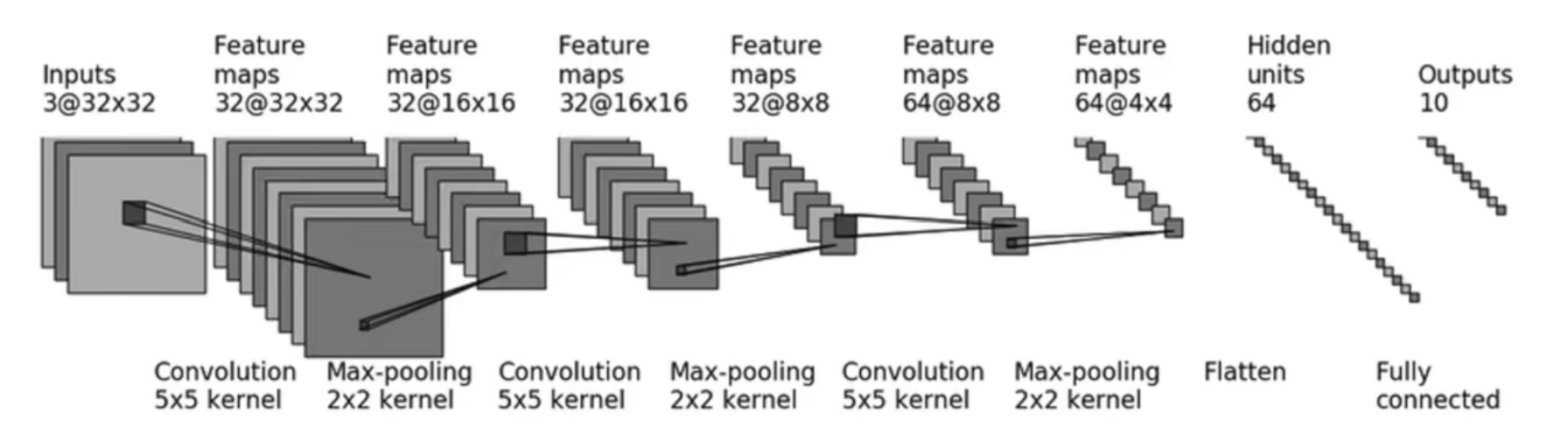
class Qian(nn.Module): def __init__(self): super(Qian, self).__init__() self.model1 = Sequential( Conv2d(3, 32, (5, 5), (1, 1), padding=2), MaxPool2d(2), Conv2d(32, 32, (5, 5), (1, 1), padding=2), MaxPool2d(2), Conv2d(32, 64, (5, 5), (1, 1), padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x
6.Loss
#计算实际输出和目标之间的差距、为更新输出提供依据 import torch from torch import nn from torch.nn import L1Loss inputs = torch.tensor([1, 2, 3], dtype=torch.float32) targets = torch.tensor([1, 2, 5], dtype=torch.float32) inputs = torch.reshape(inputs, (1, 1, 1, 3)) targets = torch.reshape(targets, (1, 1, 1, 3)) #L1loss loss_l1 = L1Loss(reduction='mean') result_l1 = loss_l1(inputs, targets)#(0+0+2)/3 print(result_l1) #均方误差损失 loss_mse = nn.MSELoss() result_mse = loss_mse(inputs, targets)#(0+0+4)/3 print(result_mse) #交叉熵 x = torch.tensor([0.1, 0.2, 0.3]) y = torch.tensor([1]) x = torch.reshape(x, (1, 3)) loss_cross = nn.CrossEntropyLoss() result_cross = loss_cross(x, y) print(result_cross)
交叉熵损失函数公式:
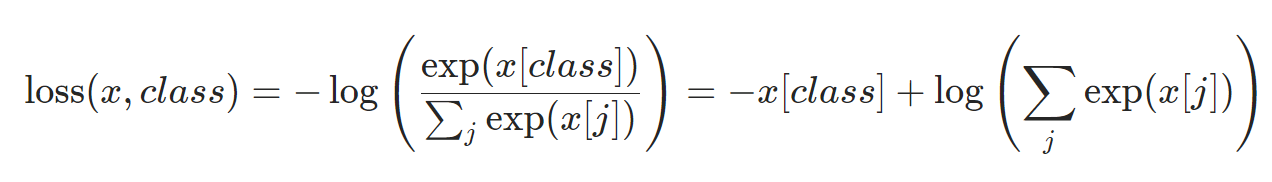
要有反向传播来计算梯度,从而为节点的更新提供依据
result_loss.backward()
7.optim
optim = torch.optim.SGD(qian.parameters(), lr=0.01)
optim.zero_grad()
optim.step()
qian = Qian() loss = nn.CrossEntropyLoss() optim = torch.optim.SGD(qian.parameters(), lr=0.01) #进行多轮优化 for epoch in range(20): running_loss = 0.0 for data in dataloader: imgs, targets = data outputs = qian(imgs) result_loss = loss(outputs, targets) #梯度清零 optim.zero_grad() #反向传播,得到每个可调节参数对应的梯度 result_loss.backward() #对每个参数进行改变 optim.step() running_loss = running_loss + result_loss print(running_loss) #会发现running_loss随着优化次数的增多而逐渐减小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号