celery工作原理介绍
在学习Celery之前,我先简单的去了解了一下什么是生产者消费者模式。
生产者消费者模式
在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
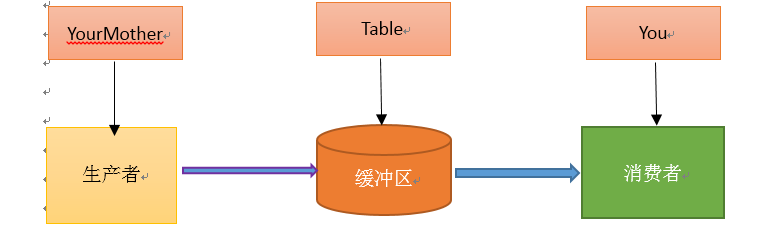
单单抽象出生产者和消费者,还够不上是生产者消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据,如下图所示:

生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过消息队列(缓冲区)来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给消息队列,消费者不找生产者要数据,而是直接从消息队列里取,消息队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个消息队列就是用来给生产者和消费者解耦的。------------->这里又有一个问题,什么叫做解耦?
解耦:假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者就会白白糟蹋大好时光。缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
因为太抽象,看过网上的说明之后,通过我的理解,我举了个例子:吃包子。
假如你非常喜欢吃包子(吃起来根本停不下来),今天,你妈妈(生产者)在蒸包子,厨房有张桌子(缓冲区),你妈妈将蒸熟的包子盛在盘子(消息)里,然后放到桌子上,你正在看巴西奥运会,看到蒸熟的包子放在厨房桌子上的盘子里,你就把盘子取走,一边吃包子一边看奥运。在这个过程中,你和你妈妈使用同一个桌子放置盘子和取走盘子,这里桌子就是一个共享对象。生产者添加食物,消费者取走食物。桌子的好处是,你妈妈不用直接把盘子给你,只是负责把包子装在盘子里放到桌子上,如果桌子满了,就不再放了,等待。而且生产者还有其他事情要做,消费者吃包子比较慢,生产者不能一直等消费者吃完包子把盘子放回去再去生产,因为吃包子的人有很多,如果这期间你好朋友来了,和你一起吃包子,生产者不用关注是哪个消费者去桌子上拿盘子,而消费者只去关注桌子上有没有放盘子,如果有,就端过来吃盘子中的包子,没有的话就等待。对应关系如下图:
考察了一下,原来当初设计这个模式,主要就是用来处理并发问题的,而Celery就是一个用python写的并行分布式框架。
然后我接着去学习Celery
Celery的定义
Celery(芹菜)是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必需工具。
我比较喜欢的一点是:Celery支持使用任务队列的方式在分布的机器、进程、线程上执行任务调度。然后我接着去理解什么是任务队列。
任务队列
任务队列是一种在线程或机器间分发任务的机制。
消息队列
消息队列的输入是工作的一个单元,称为任务,独立的职程(Worker)进程持续监视队列中是否有需要处理的新任务。
Celery 用消息通信,通常使用中间人(Broker)在客户端和职程间斡旋。这个过程从客户端向队列添加消息开始,之后中间人把消息派送给职程,职程对消息进行处理。如下图所示:
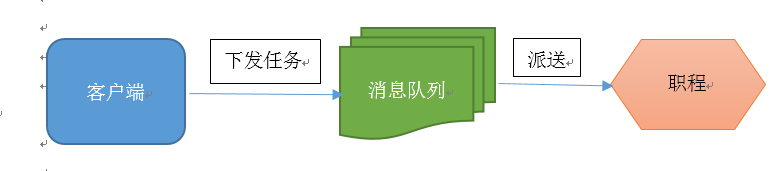
Celery 系统可包含多个职程和中间人,以此获得高可用性和横向扩展能力。
Celery的架构
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,包括,RabbitMQ,Redis,MongoDB等,这里我先去了解RabbitMQ,Redis。
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括Redis,MongoDB,Django ORM,AMQP等,这里我先不去看它是如何存储的,就先选用Redis来存储任务执行结果。
然后我接着去安装Celery,在安装Celery之前,我已经在自己虚拟机上安装好了Python,版本是2.7,是为了更好的支持Celery的3.0以上的版本。

因为涉及到消息中间件,所以我先去选择一个在我工作中要用到的消息中间件(在Celery帮助文档中称呼为中间人<broker>),为了更好的去理解文档中的例子,我安装了两个中间件,一个是RabbitMQ,一个redis。
在这里我就先根据Celery3.1的帮助文档安装和设置RabbitMQ, 要使用 Celery,我们需要创建一个 RabbitMQ 用户、一个虚拟主机,并且允许这个用户访问这个虚拟主机。下面是我在个人虚拟机Ubuntu14.04上的设置:
$ sudo rabbitmqctl add_user forward password
#创建了一个RabbitMQ用户,用户名为forward,密码是password
$ sudo rabbitmqctl add_vhost ubuntu
#创建了一个虚拟主机,主机名为ubuntu
$ sudo rabbitmqctl set_permissions -p ubuntu forward ".*" ".*" ".*"
#允许用户forward访问虚拟主机ubuntu,因为RabbitMQ通过主机名来与节点通信
$ sudo rabbitmq-server
之后我启用RabbitMQ服务器,结果如下,成功运行:
之后我安装Redis,它的安装比较简单,如下:
$ sudo pip install redis
然后进行简单的配置,只需要设置 Redis 数据库的位置:
BROKER_URL = 'redis://localhost:6379/0'
URL的格式为:
redis://:password@hostname:port/db_number
URL Scheme 后的所有字段都是可选的,并且默认为 localhost 的 6379 端口,使用数据库 0。我的配置是:
redis://:password@ubuntu:6379/5
之后安装Celery,我是用标准的Python工具pip安装的,如下:
$ sudo pip install celery
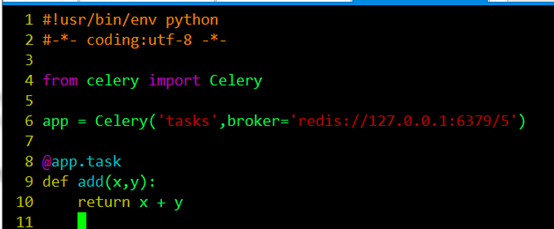
为了测试Celery能否工作,我运行了一个最简单的任务,编写tasks.py,如下图所示:
编辑保存退出后,我在当前目录下运行如下命令:
$ celery -A tasks worker --loglevel=info
#查询文档,了解到该命令中-A参数表示的是Celery APP的名称,这个实例中指的就是tasks.py,后面的tasks就是APP的名称,worker是一个执行任务角色,后面的loglevel=info记录日志类型默认是info,这个命令启动了一个worker,用来执行程序中add这个加法任务(task)。
然后看到界面显示结果如下:
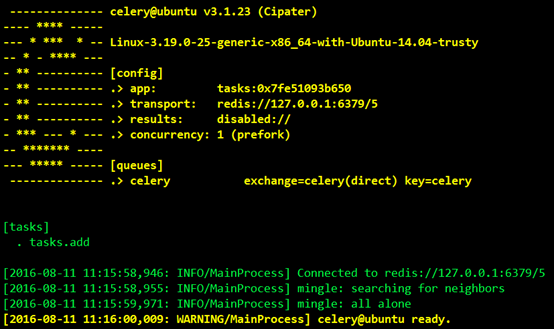
我们可以看到Celery正常工作在名称ubuntu的虚拟主机上,版本为3.1.23,在下面的[config]中我们可以看到当前APP的名称tasks,运输工具transport就是我们在程序中设置的中间人redis://127.0.0.1:6379/5,result我们没有设置,暂时显示为disabled,然后我们也可以看到worker缺省使用perfork来执行并发,当前并发数显示为1,然后可以看到下面的[queues]就是我们说的队列,当前默认的队列是celery,然后我们看到下面的[tasks]中有一个任务tasks.add.
了解了这些之后,根据文档我重新打开一个terminal,然后执行Python,进入Python交互界面,用delay()方法调用任务,执行如下操作:
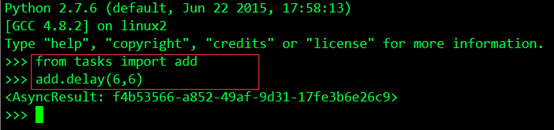
这个任务已经由之前启动的Worker异步执行了,然后我打开之前启动的worker的控制台,对输出进行查看验证,结果如下:

绿色部分第一行说明worker收到了一个任务:tasks.add,这里我们和之前发送任务返回的AsyncResult对比我们发现,每个task都有一个唯一的ID,第二行说明了这个任务执行succeed,执行结果为12。
查看资料说调用任务后会返回一个AsyncResult实例,可用于检查任务的状态,等待任务完成或获取返回值(如果任务失败,则为异常和回溯)。但这个功能默认是不开启的,需要设置一个 Celery 的结果后端(backend),这块我在下一个例子中进行了学习。
通过这个例子后我对Celery有了初步的了解,然后我在这个例子的基础上去进一步的学习。
因为Celery是用Python编写的,所以为了让代码结构化一些,就像一个应用,我使用python包,创建了一个celery服务,命名为pj。文件目录如下:

celery.py
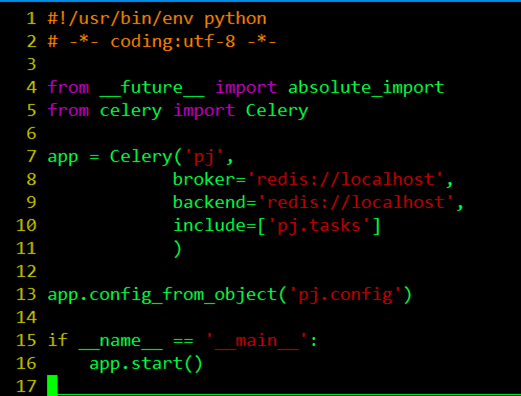
from __future __ import absolute_import
#定义未来文件的绝对进口,而且绝对进口必须在每个模块的顶部启用。
from celery import Celery
#从celery导入Celery的应用程序接口
App.config_from_object(‘pj.config’)
#从config.py中导入配置文件
if __name__ == ‘__main__’:
app.start()
#执行当前文件,运行celery
app = Celery(‘pj’,
broker=‘redis://localhost’,
backend=‘redis://localhost’,
include=[‘pj.tasks’]
)
#首先创建了一个celery实例app,实例化的过程中,制定了任务名pj(与当前文件的名字相同),Celery的第一个参数是当前模块的名称,在这个例子中就是pj,后面的参数可以在这里直接指定,也可以写在配置文件中,我们可以调用config_from_object()来让Celery实例加载配置模块,我的例子中的配置文件起名为config.py,配置文件如下:
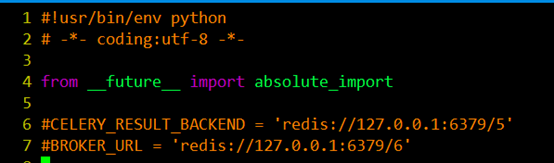
在配置文件中我们可以对任务的执行等进行管理,比如说我们可能有很多的任务,但是我希望有些优先级比较高的任务先被执行,而不希望先进先出的等待。那么需要引入一个队列的问题. 也就是说在我的broker的消息存储里面有一些队列,他们并行运行,但是worker只从对应 的队列里面取任务。在这里我们希望tasks.py中的add先被执行。task中我设置了两个任务:
所以我通过from celery import group引入group,用来创建并行执行的一组任务。然后这块现需要理解的就是这个@app.task,@符号在python中用作函数修饰符,到这块我又回头去看python的装饰器(在代码运行期间动态增加功能的方式)到底是如何实现的,在这里的作用就是通过task()装饰器在可调用的对象(app)上创建一个任务。
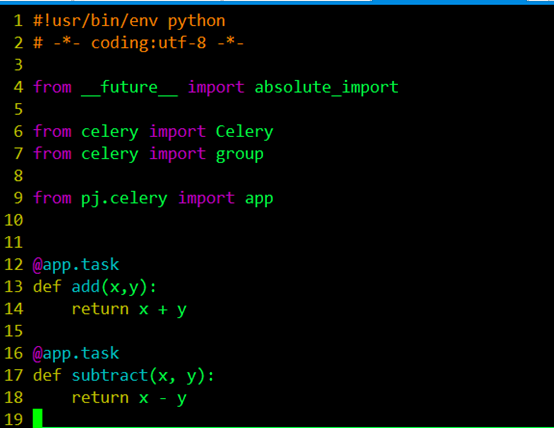
了解完装饰器后,我回过头去整理配置的问题,前面提到任务的优先级问题,在这个例子中如果我们想让add这个加法任务优先于subtract减法任务被执行,我们可以将两个任务放到不同的队列中,由我们决定先执行哪个任务,我们可以在配置文件中这样配置:

先了解了几个常用的参数的含义:
Exchange:交换机,决定了消息路由规则;
Queue:消息队列;
Channel:进行消息读写的通道;
Bind:绑定了Queue和Exchange,意即为符合什么样路由规则的消息,将会放置入哪一个消息队列;
我将add这个函数任务放在了一个叫做for_add的队列里面,将subtract这个函数任务放在了一个叫做for_subtract的队列里面,然后我在当前应用目录下执行命令:

这个worker就只负责处理for_add这个队列的任务,执行这个任务:

任务已经被执行,我在worker控制台查看结果:

可以看到worker收到任务,并且执行了任务。
在这里我们还是在交互模式下手动去执行,我们想要crontab的定时生成和执行,我们可以用celery的beat去周期的生成任务和执行任务,在这个例子中我希望每10秒钟产生一个任务,然后去执行这个任务,我可以这样配置:
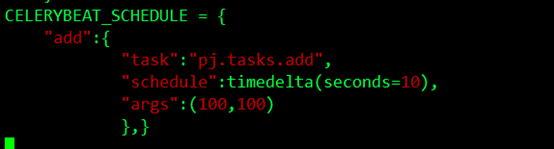
使用了scheduler,要制定时区:CELERY_TIMEZONE = 'Asia/Shanghai',启动celery加上-B的参数:

并且要在config.py中加入from datetime import timedelta。
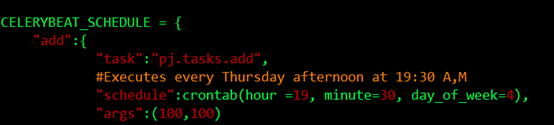
更近一步,如果我希望在每周四的19点30分生成任务,分发任务,让worker取走执行,可以这样配置:
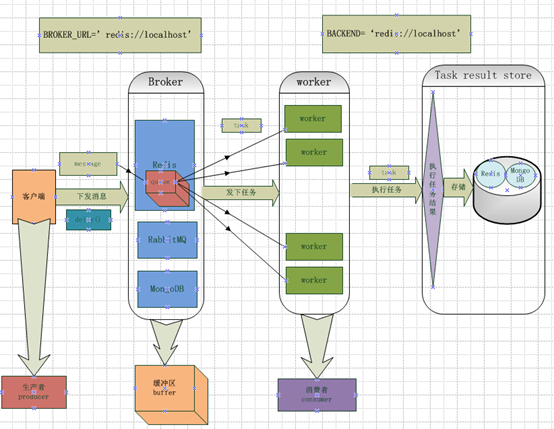
看完这些基础的东西,我回过头对celery在回顾了一下,用图把它的框架大致画出来,如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号