
Handling Missing Data with Graph Representation Learning
Handling Missing Data with Graph Representation Learning
introduction
缺失数据目前有两种方法,feature imputation 和 label prediction即对已缺失数据进行插补和不管缺失数据,利用已知数据直接进行标签预测的
统计学方法目前的缺陷:
1.对数据分布有强假设
2.不能灵活处理混合数据类型的情况即同时包含连续和离散变量的情况
3.基于矩阵完成(matrix completion)的方法不能推广到未知样本,当模型遇到新的数据样本,需要再次训练
4.现有的方法(基于树结构的模型)依赖于启发式(heuristics)(就是非常依赖已有的数据经验),会有可扩展性问题(scalability issues)
Methodology
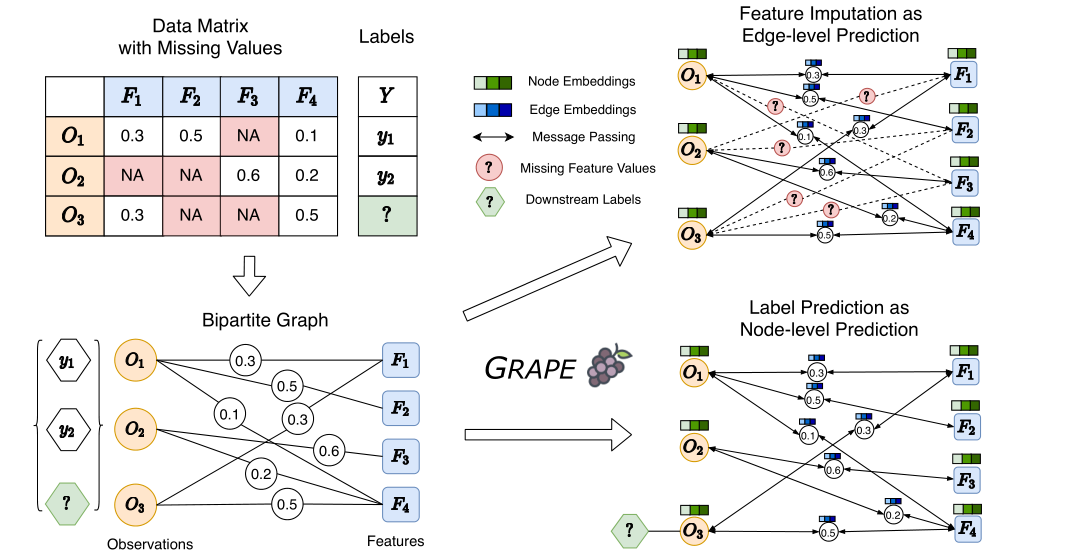
1.建立二部图:一侧是所有数据节点,另一侧是所有的特征项,为两类节点建边,基本上类似全连接,如果特征缺失就不建边。边的值就是特征值,如果是离散值就用one-hot。
2.这里网络的构建是在graphsage的基础上做的
\[n_v^{(l)}=AGG_l(\sigma(P^{(l)}\cdot Concat(h_v^{(l-1)},e_{uv}^{(l-1)})|{\forall u\in N(v,\varepsilon_{drop})})\\
h_v^{(l)}=\sigma(Q^{(l)}\cdot Concat(h_v^{(l-1)},n_v^{(l)}))\\
e_{uv}^{(l)}=\sigma(W^{(l)}\cdot Concat(e_{uv}^{(l-1)},h_u^{(l)},h_v^{(l)}))\\
\]
这里的P,Q,W都是可学习训练参数,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号