
2020年3月10日 Python爬取网络数据导入数据库
一、目标

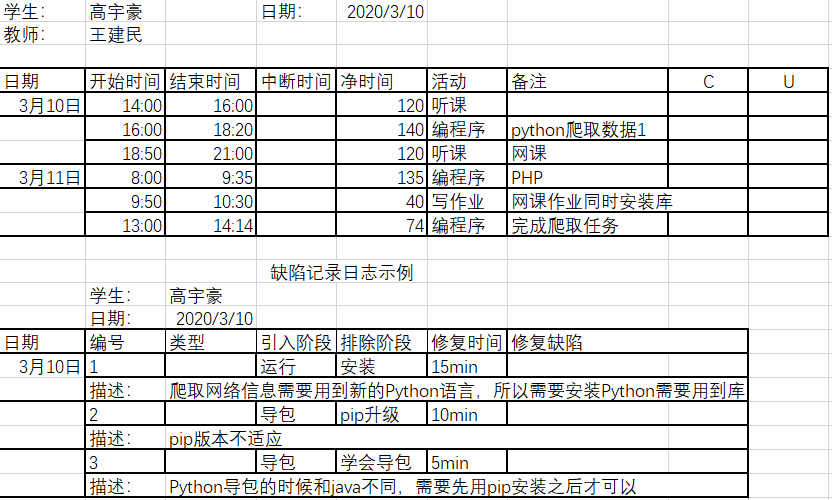
二、PSP表格
三、源程序代码
Python部分
from os import path import requests from bs4 import BeautifulSoup import json import pymysql import numpy as np import time from _ast import Try url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0' #请求地址 headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息 response = requests.get(url,headers = headers) #发送网络请求 #print(response.content.decode('utf-8'))#以字节流形式打印网页源码 content = response.content.decode('utf-8') #print(content) soup = BeautifulSoup(content, 'html.parser') listA = soup.find_all(name='script',attrs={"id":"getAreaStat"}) #世界确诊 listB = soup.find_all(name='script',attrs={"id":"getListByCountryTypeService2"}) #listA = soup.find_all(name='div',attrs={"class":"c-touchable-feedback c-touchable-feedback-no-default"}) account = str(listA) world_messages = str(listB)[87:-21] messages = account[52:-21] messages_json = json.loads(messages) world_messages_json = json.loads(world_messages) valuesList = [] cityList = [] worldList = [] localtime = time.localtime(time.time()) L=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) print(L) for i in range(len(messages_json)): #value = messages_json[i] #value = (messages_json[i].get('provinceName'),messages_json[i].get('provinceShortName'),messages_json[i].get('currentConfirmedCount'),messages_json[i].get('confirmedCount'),messages_json[i].get('suspectedCount'),messages_json[i].get('curedCount'),messages_json[i].get('deadCount'),messages_json[i].get('comment'),messages_json[i].get('locationId')) value = (messages_json[i].get('provinceName'),messages_json[i].get('confirmedCount'),messages_json[i].get('curedCount'),messages_json[i].get('deadCount'),messages_json[i].get('locationId')) valuesList.append(value) cityValue = messages_json[i].get('cities') #print(cityValue) 一个省内没有划分开的值 for j in range(len(cityValue)): #cityValueList = (cityValue[j].get('cityName'),cityValue[j].get('currentConfirmedCount'),cityValue[j].get('confirmedCount'),cityValue[j].get('suspectedCount'),cityValue[j].get('curedCount'),cityValue[j].get('deadCount'),cityValue[j].get('locationId'),messages_json[i].get('provinceShortName')) cityValueList = (messages_json[i].get('provinceName'),cityValue[j].get('cityName'),cityValue[j].get('confirmedCount'),cityValue[j].get('curedCount'),cityValue[j].get('deadCount'),cityValue[j].get('locationId')) #print(cityValueList) 省份内各个城市的值 cityList.append(cityValueList) #print(cityList) #城市 #print(valuesList) #省份 db=pymysql.connect("localhost","root","123456","echart_yiqing", charset='utf8') cursor = db.cursor() sql_city="insert into info_copy (Province,City,Confirmed_num,Cured_num,Dead_num,Code,Date) values (%s,%s,%s,%s,%s,%s,'"+L+"')" sql_province="insert into info_copy (Province,Confirmed_num,Cured_num,Dead_num,Code,Date) values (%s,%s,%s,%s,%s,'"+L+"')" #print(sql) value_tuple= tuple(valuesList) city_tuple=tuple(cityList) try: cursor.executemany(sql_province,valuesList) cursor.executemany(sql_city,city_tuple) db.commit() except: print('执行失败,进入回调4') db.rollback() db.close()
其他部分用的是上次的部分就不写了,Python的部分主要就是用request来向网页发送请求然后对网页里面的标签进行解析,找到自己需要的信息获取就行,自我感觉有点类似于servlet中的request获取信息的方式。另外由于搜索的那个页面中的信息没有日期,所以在程序中加入了time语句来获取系统的时间,在导入数据库的时候一同导入。
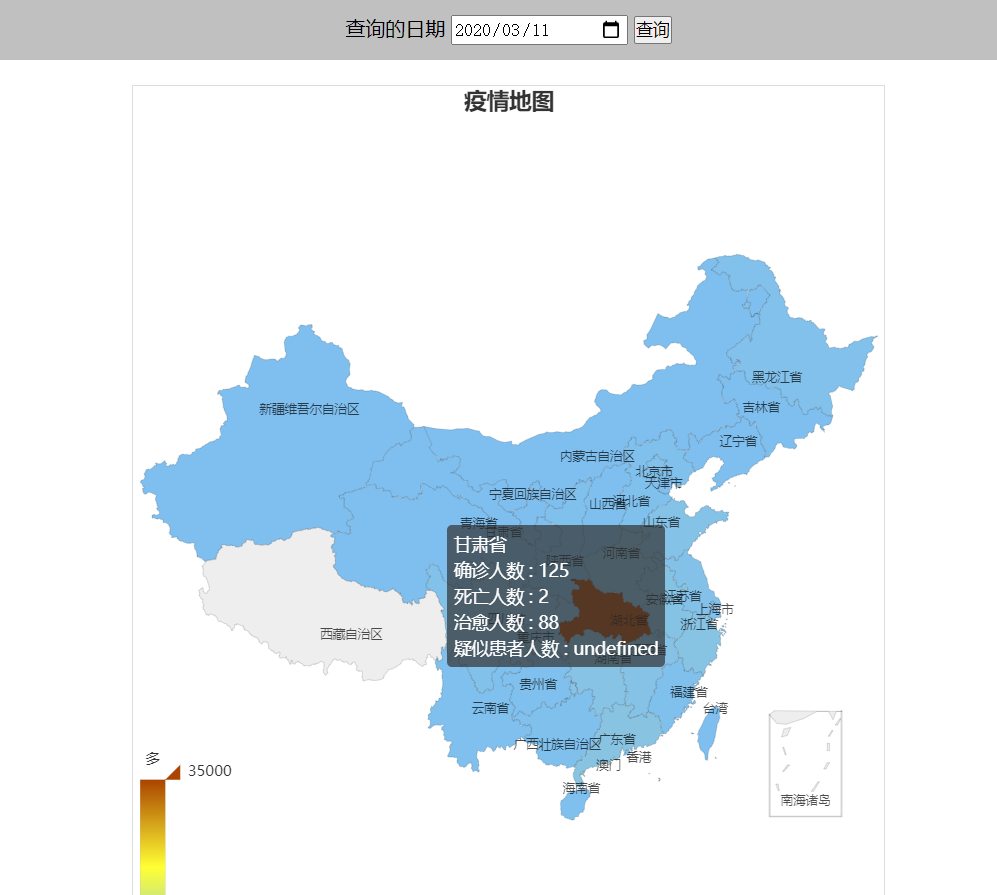
四、效果图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号