python - 字符串编码
python 常用的编码类型:
GB2312编码:主要用于汉字处理和汉字通信等系统的信息交互。
ANSI(扩展的ASCII编码):主要是简体中文的交互(用一个字节表示英文,用两个字节表示一个中文)也叫GBK编码。
GBK编码:主要用于对中文的编码。
UTF-8编码:可以实现所有文字的编码,如日文、韩文。。。
ASCII编码:主要是把英文字母,数字,标点,字符转换成计算机能识别的二进制数。(部分)
Unicode编码:世界通用的,所有字符的编码。(全部)
注意:GB2312,ANSI,GBK,UTF-8,ASCII是属于存储编码,Unicode是属于字符编码
python 版本之间编码的差异:
py2.7
![]()
![]()
需要专门考虑中文字符的输出问题,因为python2是用的ascii存储编码的,ascii是无法处理中文的,所以在解码的时候会出现乱码
py3.6
python3是用UTF-8存储编码的,UTF-8可以进行中文解码,所以在python3中就不再考虑中文的兼容问题了。
编码解码原则:
原则1:用什么类型进行编码,就要用对应的进行解码
原则2:unicode(str类型)-->encode-->bytes类型
bytes类型 -->decode-->unicode(str类型)
类型错误也是无法进行编码的
编码实际应用
情景1:
>>> s = '中国'
>>> s = s.encode('utf-8') # 这里用utf8进行编码,注意如果括号里面不写类型,那么会默认为是utf8
>>> s.decode('utf-8') # 这里就要用utf8进行解码
'中国'
>>> s1 = '中国'.encode('gbk')
>>> s1.decode('gbk')
'中国'
情景2:
在py文件中,头部往往都有 # -*- coding: utf-8 -*-; # -*- coding: gbk -*- :声明文件的解码格式
那么在解码时,要用对应的类型进行解码,否则会报错
情景3:
保存文件的编码与解码不一致的情况

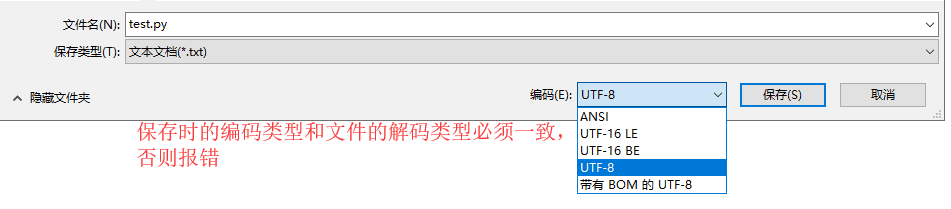
报错一般是如下两种:
1:SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xc4 in position 0:invalid continuation byte
2:SyntaxError: encoding problem: gbk
总结:
- 在计算机内存中,统一使用Unicode编码,如编程的时候
-
当需要保存到硬盘或者需要传输的时候,统一是用bytes编码(如 utf8,GBK等)
- 当读取文件时就是解码过程
- 网页也是如此,浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器 (源码往往就有类似声明<meta charset="UTF-8" />)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号