

实验四
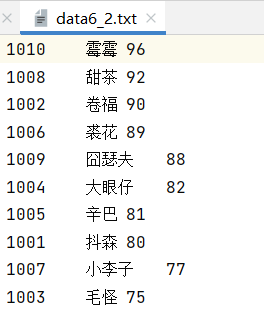
1 with open('data6_1.txt', 'r', encoding='utf-8') as f: 2 data = f.read().split('\n') 3 4 data1 = [str(i).split('\t') for i in data] 5 6 data1.sort(key=lambda x: x[2], reverse=True) 7 with open('data6_2.txt', 'w+',encoding='utf-8')as f: 8 for line in data1: 9 for i in line: 10 f.write(i + '\t') 11 print(i + '\t', end='') 12 f.write('\n') 13 print()

7-1
1 import random 2 3 with open('data7.txt', 'r', encoding='gbk')as f: 4 data = f.read().split('\n') 5 6 info = eval(input('输入随机抽点人数:')) 7 # 随机抽取模块 8 output = set() 9 while len(output) < info: 10 rand = random.randint(0, len(data) - 1) 11 output.add(str(data[rand])) 12 # 写入模块 13 with open('lucky.txt', 'w+', encoding='utf-8')as f: 14 for line in output: 15 f.write(line + '\n') 16 print(line)


7-2
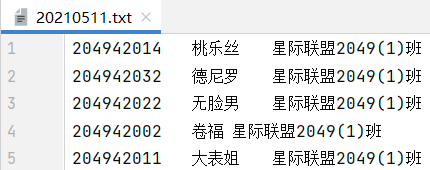
1 #时间模块 2 import datetime 3 t = datetime.datetime.now() 4 t = t.strftime('%Y%m%d') 5 6 import random 7 with open('data7.txt', 'r', encoding='gbk')as f: 8 data = f.read().split('\n') 9 10 info = eval(input('输入随机抽点人数:')) 11 # 随机抽取模块 12 output = set() 13 while len(output) < info: 14 rand = random.randint(0, len(data) - 1) 15 output.add(str(data[rand])) 16 # 写入模块 17 with open(f'{t}.txt', 'w+', encoding='utf-8')as f: 18 for line in output: 19 f.write(line + '\n') 20 print(line)

7-3
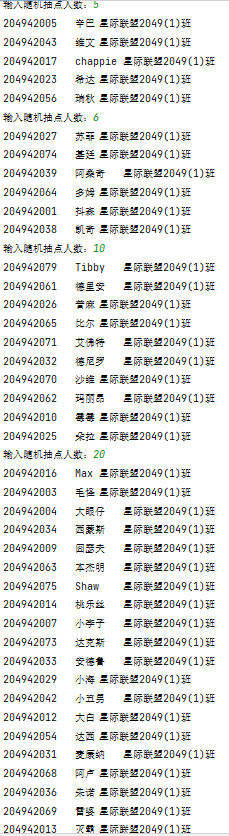
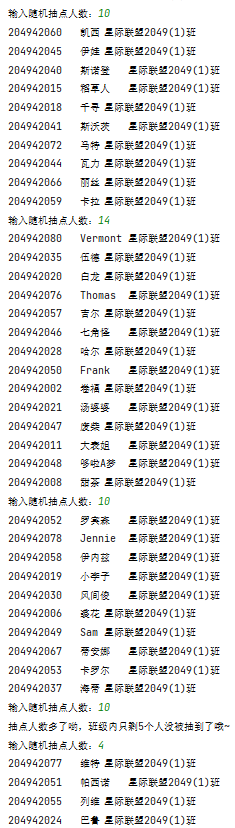
1 import random 2 # 时间模块 3 import datetime 4 t = datetime.datetime.now() 5 t = t.strftime('%Y%m%d') 6 with open('data7.txt', 'r', encoding='gbk')as f: 7 data = f.read().split('\n') 8 info = eval(input('输入随机抽点人数:')) 9 # 使用集合:防止总名单重复 10 output = set() 11 while info > 0: 12 in_data = set() # 使用集合防止单次抽点出现重复 13 # 随机抽取模块 14 while len(in_data - output) < info and len(data) >= len(output) + info: 15 rand = random.randint(0, len(data) - 1) 16 in_data.add(str(data[rand])) 17 if len(data) < len(output) + info and len(data) - len(output) != 0: 18 print(f'抽点人数多了哟,班级内只剩{len(data) - len(output)}个人没被抽到了哦~') 19 elif len(data) - len(output) == 0: 20 print('班级同学已经全部被点过啦!') 21 exit() 22 else: 23 # 写入模块 24 with open(f'{t}.txt', 'a+', encoding='utf-8')as f: 25 for line in in_data - output: 26 f.write(line + '\n') 27 print(line) 28 output = output | in_data 29 info = eval(input('输入随机抽点人数:'))



实验总结:这次实验中,我发现使用python读取文件时,由于文件数据的冗杂性,非常容易错读误读,机器识别输入数据是自动化处理中最艰难的部分之一,我猜想通用人工智能至今未被制造出的原因之一就是现实世界数据的冗杂性,使机器难以识别。在这次敲打代码的过程中,我学会应用对简单文件的读写和处理,浅显理解了一些代码的用途和简单组合,在面对稍显复杂的实际问题时,我就难以攻关了,还需要更多的练习和对代码的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号