二、Dockerfile与K8S组件和部署
一.基于dockerfile构建nginx镜像
1.在Dockerfile目录下准备编译安装的相关文件
root@docker-server1:~# mkdir -p /data/dockerfile/web/nginx
root@docker-server1:~# cp nginx.conf /data/dockerfile/web/nginx/
root@docker-server1:~# cd /data/dockerfile/web/nginx/
root@docker-server1:/data/dockerfile/web/nginx# cp /etc/apt/sources.list .
root@docker-server1:/data/dockerfile/web/nginx# sed -i "s/deb https/deb http/g" sources.list
root@docker-server1:/data/dockerfile/web/nginx# wget https://nginx.org/download/nginx-1.20.2.tar.gz
2.编写Dockerfile文件
root@docker-server1:/data/dockerfile/web/nginx# vim Dockerfile
root@docker-server1:/data/dockerfile/web/nginx# cat Dockerfile
##Nginx image
FROM ubuntu:20.04
LABEL "maintainer"="kevin 12345678@qq.com"
COPY sources.list /etc/apt/sources.list
RUN apt-get update && apt-get install -y iproute2 ntpdate tcpdump telnet traceroute nfs-kernel-server nfs-common lrzsz tree openssl libssl-dev libpcre3 libpcre3-dev zlib1g-dev ntpdate tcpdump telnet traceroute gcc openssh-server iotop unzip zip make vim && mkdir /data/nginx -p
ADD nginx-1.20.2.tar.gz /usr/local/src
RUN cd /usr/local/src/nginx-1.20.2 && ./configure --prefix=/apps/nginx && make && make install && ln -sv /apps/nginx/sbin/nginx /usr/bin && rm -rf /usr/local/src/nginx-1.20.2 && rm -rf /usr/local/src/nginx-1.20.2.tar.gz
RUN ln -sv /dev/stdout /apps/nginx/logs/access.log
RUN ln -sv /dev/stderr /apps/nginx/logs/error.log
RUN groupadd -g 2022 nginx && useradd -g nginx -s /usr/sbin/nologin -u 2022 nginx && chown -R nginx.nginx /apps/nginx /data/nginx
EXPOSE 80 443
CMD ["/apps/nginx/sbin/nginx","-g","daemon off;"]
3.生成nginx镜像
root@docker-server1:/data/dockerfile/web/nginx# vim build.sh
root@docker-server1:/data/dockerfile/web/nginx# cat build.sh
#!/bin/bash
docker build -t nginx-ubuntu:1.20.2-v1 .
root@docker-server1:/data/dockerfile/web/nginx# chmod +x build.sh
root@docker-server1:/data/dockerfile/web/nginx# ll
total 1064
drwxr-xr-x 2 root root 4096 Jan 7 02:54 ./
drwxr-xr-x 3 root root 4096 Jan 7 02:27 ../
-rwxr-xr-x 1 root root 53 Jan 7 02:54 build.sh*
-rw-r--r-- 1 root root 944 Jan 7 02:47 Dockerfile
-rw-r--r-- 1 root root 1062124 Nov 16 14:51 nginx-1.20.2.tar.gz
-rw-r--r-- 1 root root 648 Jan 7 02:29 nginx.conf
-rw-r--r-- 1 root root 1313 Jan 7 02:45 sources.list
root@docker-server1:/data/dockerfile/web/nginx# ./build.sh
root@docker-server1:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx-ubuntu 1.20.2-v1 f3814ce35749 15 seconds ago 443MB
4.生成容器测试镜像
root@docker-server1:~# docker run -d -p 80:80 nginx-ubuntu:1.20.2-v1
ddf4e60ab9a162571bff94a15fa37a667dd2d5d174dbd46bdd44408a5466aeca
root@docker-server1:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ddf4e60ab9a1 nginx-ubuntu:1.20.2-v1 "/apps/nginx/sbin/ng…" 3 seconds ago Up 3 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp, 443/tcp blissful_mirzakhani
root@docker-server1:~# docker exec -it ddf4e60ab9a1 bash
root@ddf4e60ab9a1:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4596 3104 ? Ss 05:24 0:00 nginx: master process /apps/nginx/sbin/nginx -g daemon off;
nobody 7 0.0 0.0 5280 2680 ? S 05:24 0:00 nginx: worker process
root 8 0.2 0.0 4240 3480 pts/0 Ss 05:26 0:00 bash
root 18 0.0 0.0 5896 2852 pts/0 R+ 05:26 0:00 ps aux
2.熟练掌握容器的cpu和内存的资源限制
1.容器的资源限制介绍
默认情况下,容器没有资源的使用限制,可以使用主机内核调度程序允许的尽可能多的资源;
Docker 提供了控制容器使用资源的方法,可以限制容器使用多少内存或 CPU等,在docker run 命令的运行时配置标志实现资源限制功能。
其中许多功能都要求宿主机的内核支持,要检查是否支持这些功能,可以使用docker info 命令 ,如果内核中的某项特性可能会在输出结尾处看到警告, 如下所示:
WARNING: No swap limit support
可通过修改内核参数消除以上警告
root@docker-server1:~# vim /etc/default/grub
GRUB_CMDLINE_LINUX="cgroup_enable=memory net.ifnames=0 swapaccount=1"
root@docker-server1:~# update-grub
root@docker-server1:~# reboot
root@docker-server1:~# docker info
Client:
Context: default
Debug Mode: false
Plugins:
app: Docker App (Docker Inc., v0.9.1-beta3)
buildx: Docker Buildx (Docker Inc., v0.7.1-docker)
scan: Docker Scan (Docker Inc., v0.12.0)
Server:
Containers: 9
Running: 0
Paused: 0
Stopped: 9
Images: 23
Server Version: 20.10.12
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 1
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 io.containerd.runtime.v1.linux runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 7b11cfaabd73bb80907dd23182b9347b4245eb5d
runc version: v1.0.2-0-g52b36a2
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 5.4.0-91-generic
Operating System: Ubuntu 20.04.3 LTS
OSType: linux
Architecture: x86_64
CPUs: 2
Total Memory: 3.816GiB
Name: docker-server1
ID: 4RMV:YM64:VYYH:WU44:CKHD:WTER:LWHE:L4DC:3QL2:NA7P:QQ73:Q4IJ
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
10.0.0.8
127.0.0.0/8
Registry Mirrors:
https://8idw6a7x.mirror.aliyuncs.com/
Live Restore Enabled: false
2.容器的内存限制
Docker 可以强制执行硬性内存限制,即只允许容器使用给定的内存大小。
Docker 也可以执行非硬性内存限制,即容器可以使用尽可能多的内存,除非内核检测到主机上的内存不够用了。
-m , --memory= #容器可以使用的最大物理内存量,硬限制,此选项最小允许值为4m (4 MB),此项较常用
--memory-swap #只有在设置了 --memory 后才会有意义。使用 Swap,可以让容器将超出限制部分的内存置换到磁盘上,WARNING: 经常将内存交换到磁盘的应用程序会降低性能
3.容器的CPU限制
一个宿主机,有几十个核心的CPU,但是宿主机上可以同时运行成百上千个不同的进程用以处理不同的任务,多进程共用一个CPU的核心为可压缩资源,即一个核心的CPU可以通过调度而运行多个进程,但是同一个单位时间内只能有一个进程在 CPU 上运行,那么这么多的进程怎么在 CPU 上执行和调度的呢?
Linux kernel 进程的调度基于CFS(Completely Fair Scheduler),完全公平调度。
默认情况下,每个容器对主机的CPU周期的访问都是不受限制的。
--cpus= #指定一个容器可以使用多少个可用的CPU核心资源。例如,如果主机有两个CPU,如果设置了 --cpus="1.5" ,则可以保证容器最多使用1.5个的CPU(如果是4核CPU,那么还可以是4核心上每核用一点,但是总计是1.5核心的CPU)。这相当于设置 --cpu-period="100000" 和 --cpu-quota="150000" 。此设置可在Docker 1.13及更高版本中可用,目的是替代--cpu-period和--cpu-quota两个参数,从而使配置更简单,但是最大不能超出宿主机的CPU总核心数(在操作系统看到的CPU超线程后的数值),此项较常用
4.使用stress-ng测试cpu和内存配置
4.1 容器方式安装stress-ng
root@docker-server1:~# docker pull lorel/docker-stress-ng
Using default tag: latest
latest: Pulling from lorel/docker-stress-ng
Image docker.io/lorel/docker-stress-ng:latest uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker.com/registry/spec/deprecated-schema-v1/
c52e3ed763ff: Pull complete
a3ed95caeb02: Pull complete
7f831269c70e: Pull complete
Digest: sha256:c8776b750869e274b340f8e8eb9a7d8fb2472edd5b25ff5b7d55728bca681322
Status: Downloaded newer image for lorel/docker-stress-ng:latest
docker.io/lorel/docker-stress-ng:latest
root@docker-server1:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx-ubuntu 1.20.2-v1 f3814ce35749 35 minutes ago 443MB
<none> <none> 8082772c341d 43 minutes ago 437MB
<none> <none> 24e2e4cc2bb8 2 hours ago 425MB
<none> <none> c4b8d6aa6d44 2 hours ago 72.8MB
<none> <none> b913bfe4a922 2 hours ago 425MB
<none> <none> 1d06f03bdffc 3 hours ago 105MB
<none> <none> c1414b9965ca 3 hours ago 72.8MB
<none> <none> 1b741b46b313 3 hours ago 72.8MB
10.0.0.8/test/nginx v1.1 81c4b1177a6c 9 days ago 141MB
tomcat latest fb5657adc892 2 weeks ago 680MB
10.0.0.8/test/redis v1.1 7614ae9453d1 2 weeks ago 113MB
redis latest 7614ae9453d1 2 weeks ago 113MB
nginx latest f6987c8d6ed5 2 weeks ago 141MB
ubuntu 20.04 ba6acccedd29 2 months ago 72.8MB
ubuntu latest ba6acccedd29 2 months ago 72.8MB
lorel/docker-stress-ng latest 1ae56ccafe55 5 years ago 8.1MB
4.2 查看stress-ng帮助
root@docker-server1:~# docker run -it --rm lorel/docker-stress-ng
stress-ng, version 0.03.11
Usage: stress-ng [OPTION [ARG]]
--h, --help show help
--affinity N start N workers that rapidly change CPU affinity
--affinity-ops N stop when N affinity bogo operations completed
--affinity-rand change affinity randomly rather than sequentially
--aio N start N workers that issue async I/O requests
--aio-ops N stop when N bogo async I/O requests completed
--aio-requests N number of async I/O requests per worker
-a N, --all N start N workers of each stress test
-b N, --backoff N wait of N microseconds before work starts
-B N, --bigheap N start N workers that grow the heap using calloc()
--bigheap-ops N stop when N bogo bigheap operations completed
--bigheap-growth N grow heap by N bytes per iteration
--brk N start N workers performing rapid brk calls
--brk-ops N stop when N brk bogo operations completed
--brk-notouch don't touch (page in) new data segment page
--bsearch start N workers that exercise a binary search
--bsearch-ops stop when N binary search bogo operations completed
--bsearch-size number of 32 bit integers to bsearch
-C N, --cache N start N CPU cache thrashing workers
--cache-ops N stop when N cache bogo operations completed (x86 only)
--cache-flush flush cache after every memory write (x86 only)
--cache-fence serialize stores
--class name specify a class of stressors, use with --sequential
--chmod N start N workers thrashing chmod file mode bits
--chmod-ops N stop chmod workers after N bogo operations
-c N, --cpu N start N workers spinning on sqrt(rand())
--cpu-ops N stop when N cpu bogo operations completed
-l P, --cpu-load P load CPU by P %%, 0=sleep, 100=full load (see -c)
--cpu-method m specify stress cpu method m, default is all
-D N, --dentry N start N dentry thrashing processes
--dentry-ops N stop when N dentry bogo operations completed
--dentry-order O specify dentry unlink order (reverse, forward, stride)
--dentries N create N dentries per iteration
--dir N start N directory thrashing processes
--dir-ops N stop when N directory bogo operations completed
-n, --dry-run do not run
--dup N start N workers exercising dup/close
--dup-ops N stop when N dup/close bogo operations completed
--epoll N start N workers doing epoll handled socket activity
--epoll-ops N stop when N epoll bogo operations completed
--epoll-port P use socket ports P upwards
--epoll-domain D specify socket domain, default is unix
--eventfd N start N workers stressing eventfd read/writes
--eventfd-ops N stop eventfd workers after N bogo operations
--fault N start N workers producing page faults
--fault-ops N stop when N page fault bogo operations completed
--fifo N start N workers exercising fifo I/O
--fifo-ops N stop when N fifo bogo operations completed
--fifo-readers N number of fifo reader processes to start
--flock N start N workers locking a single file
--flock-ops N stop when N flock bogo operations completed
-f N, --fork N start N workers spinning on fork() and exit()
--fork-ops N stop when N fork bogo operations completed
--fork-max P create P processes per iteration, default is 1
--fstat N start N workers exercising fstat on files
--fstat-ops N stop when N fstat bogo operations completed
--fstat-dir path fstat files in the specified directory
--futex N start N workers exercising a fast mutex
--futex-ops N stop when N fast mutex bogo operations completed
--get N start N workers exercising the get*() system calls
--get-ops N stop when N get bogo operations completed
-d N, --hdd N start N workers spinning on write()/unlink()
--hdd-ops N stop when N hdd bogo operations completed
--hdd-bytes N write N bytes per hdd worker (default is 1GB)
--hdd-direct minimize cache effects of the I/O
--hdd-dsync equivalent to a write followed by fdatasync
--hdd-noatime do not update the file last access time
--hdd-sync equivalent to a write followed by fsync
--hdd-write-size N set the default write size to N bytes
--hsearch start N workers that exercise a hash table search
--hsearch-ops stop when N hash search bogo operations completed
--hsearch-size number of integers to insert into hash table
--inotify N start N workers exercising inotify events
--inotify-ops N stop inotify workers after N bogo operations
-i N, --io N start N workers spinning on sync()
--io-ops N stop when N io bogo operations completed
--ionice-class C specify ionice class (idle, besteffort, realtime)
--ionice-level L specify ionice level (0 max, 7 min)
-k, --keep-name keep stress process names to be 'stress-ng'
--kill N start N workers killing with SIGUSR1
--kill-ops N stop when N kill bogo operations completed
--lease N start N workers holding and breaking a lease
--lease-ops N stop when N lease bogo operations completed
--lease-breakers N number of lease breaking processes to start
--link N start N workers creating hard links
--link-ops N stop when N link bogo operations completed
--lsearch start N workers that exercise a linear search
--lsearch-ops stop when N linear search bogo operations completed
--lsearch-size number of 32 bit integers to lsearch
-M, --metrics print pseudo metrics of activity
--metrics-brief enable metrics and only show non-zero results
--memcpy N start N workers performing memory copies
--memcpy-ops N stop when N memcpy bogo operations completed
--mmap N start N workers stressing mmap and munmap
--mmap-ops N stop when N mmap bogo operations completed
--mmap-async using asynchronous msyncs for file based mmap
--mmap-bytes N mmap and munmap N bytes for each stress iteration
--mmap-file mmap onto a file using synchronous msyncs
--mmap-mprotect enable mmap mprotect stressing
--msg N start N workers passing messages using System V messages
--msg-ops N stop msg workers after N bogo messages completed
--mq N start N workers passing messages using POSIX messages
--mq-ops N stop mq workers after N bogo messages completed
--mq-size N specify the size of the POSIX message queue
--nice N start N workers that randomly re-adjust nice levels
--nice-ops N stop when N nice bogo operations completed
--no-madvise don't use random madvise options for each mmap
--null N start N workers writing to /dev/null
--null-ops N stop when N /dev/null bogo write operations completed
-o, --open N start N workers exercising open/close
--open-ops N stop when N open/close bogo operations completed
-p N, --pipe N start N workers exercising pipe I/O
--pipe-ops N stop when N pipe I/O bogo operations completed
-P N, --poll N start N workers exercising zero timeout polling
--poll-ops N stop when N poll bogo operations completed
--procfs N start N workers reading portions of /proc
--procfs-ops N stop procfs workers after N bogo read operations
--pthread N start N workers that create multiple threads
--pthread-ops N stop pthread workers after N bogo threads created
--pthread-max P create P threads at a time by each worker
-Q, --qsort N start N workers exercising qsort on 32 bit random integers
--qsort-ops N stop when N qsort bogo operations completed
--qsort-size N number of 32 bit integers to sort
-q, --quiet quiet output
-r, --random N start N random workers
--rdrand N start N workers exercising rdrand instruction (x86 only)
--rdrand-ops N stop when N rdrand bogo operations completed
-R, --rename N start N workers exercising file renames
--rename-ops N stop when N rename bogo operations completed
--sched type set scheduler type
--sched-prio N set scheduler priority level N
--seek N start N workers performing random seek r/w IO
--seek-ops N stop when N seek bogo operations completed
--seek-size N length of file to do random I/O upon
--sem N start N workers doing semaphore operations
--sem-ops N stop when N semaphore bogo operations completed
--sem-procs N number of processes to start per worker
--sendfile N start N workers exercising sendfile
--sendfile-ops N stop after N bogo sendfile operations
--sendfile-size N size of data to be sent with sendfile
--sequential N run all stressors one by one, invoking N of them
--sigfd N start N workers reading signals via signalfd reads
--sigfd-ops N stop when N bogo signalfd reads completed
--sigfpe N start N workers generating floating point math faults
--sigfpe-ops N stop when N bogo floating point math faults completed
--sigsegv N start N workers generating segmentation faults
--sigsegv-ops N stop when N bogo segmentation faults completed
-S N, --sock N start N workers doing socket activity
--sock-ops N stop when N socket bogo operations completed
--sock-port P use socket ports P to P + number of workers - 1
--sock-domain D specify socket domain, default is ipv4
--stack N start N workers generating stack overflows
--stack-ops N stop when N bogo stack overflows completed
-s N, --switch N start N workers doing rapid context switches
--switch-ops N stop when N context switch bogo operations completed
--symlink N start N workers creating symbolic links
--symlink-ops N stop when N symbolic link bogo operations completed
--sysinfo N start N workers reading system information
--sysinfo-ops N stop when sysinfo bogo operations completed
-t N, --timeout N timeout after N seconds
-T N, --timer N start N workers producing timer events
--timer-ops N stop when N timer bogo events completed
--timer-freq F run timer(s) at F Hz, range 1000 to 1000000000
--tsearch start N workers that exercise a tree search
--tsearch-ops stop when N tree search bogo operations completed
--tsearch-size number of 32 bit integers to tsearch
--times show run time summary at end of the run
-u N, --urandom N start N workers reading /dev/urandom
--urandom-ops N stop when N urandom bogo read operations completed
--utime N start N workers updating file timestamps
--utime-ops N stop after N utime bogo operations completed
--utime-fsync force utime meta data sync to the file system
-v, --verbose verbose output
--verify verify results (not available on all tests)
-V, --version show version
-m N, --vm N start N workers spinning on anonymous mmap
--vm-bytes N allocate N bytes per vm worker (default 256MB)
--vm-hang N sleep N seconds before freeing memory
--vm-keep redirty memory instead of reallocating
--vm-ops N stop when N vm bogo operations completed
--vm-locked lock the pages of the mapped region into memory
--vm-method m specify stress vm method m, default is all
--vm-populate populate (prefault) page tables for a mapping
--wait N start N workers waiting on child being stop/resumed
--wait-ops N stop when N bogo wait operations completed
--zero N start N workers reading /dev/zero
--zero-ops N stop when N /dev/zero bogo read operations completed
Example: stress-ng --cpu 8 --io 4 --vm 2 --vm-bytes 128M --fork 4 --timeout 10s
Note: Sizes can be suffixed with B,K,M,G and times with s,m,h,d,y
4.3 默认一个workers 分配256M内存,2个即占512M内存
root@docker-server1:~# docker run --name c1 -it --rm lorel/docker-stress-ng --vm 2
stress-ng: info: [1] defaulting to a 86400 second run per stressor
stress-ng: info: [1] dispatching hogs: 2 vm
#因上一个命令是前台执行,下面在另一个终端窗口中执行,可以看到占用512M左右内存
root@docker-server1:~# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
10c47c64d5ad c1 199.92% 516.8MiB / 3.816GiB 13.23% 1.02kB / 0B 0B / 0B 5
4.4 指定内存
root@docker-server1:~# docker run --name c1 -it --rm -m 300m lorel/docker-stress-ng --vm 2
stress-ng: info: [1] defaulting to a 86400 second run per stressor
stress-ng: info: [1] dispatching hogs: 2 vm
root@docker-server1:~# docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
9bbe286dc1ea c1 135.47% 299.9MiB / 300MiB 99.96% 876B / 0B 2.7GB / 0B 5
root@docker-server1:~# docker run --name c2 -it --rm lorel/docker-stress-ng --vm 4
stress-ng: info: [1] defaulting to a 86400 second run per stressor
stress-ng: info: [1] dispatching hogs: 4 vm
root@docker-server1:~# docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
08b1efb62256 c2 200.07% 1.006GiB / 3.816GiB 26.36% 736B / 0B 0B / 0B 9
4.5 内存大小软限制
root@docker-server1:~# docker run -it --rm -m 256m --memory-reservation 128m --name c1 lorel/docker-stress-ng --vm 2 --vm-bytes 256m
stress-ng: info: [1] defaulting to a 86400 second run per stressor
stress-ng: info: [1] dispatching hogs: 2 vm
root@docker-server1:~# docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a632f34d918f c1 170.89% 256MiB / 256MiB 100.00% 806B / 0B 1.13GB / 0B 5
#查看硬限制
root@docker-server1:~# cat /sys/fs/cgroup/memory/docker/a632f34d918fbe77fa307d262bf1f22360b336baf6e46aaec0080a22cddede2d/memory.limit_in_bytes
268435456
#查看软限制
root@docker-server1:~# cat /sys/fs/cgroup/memory/docker/a632f34d918fbe77fa307d262bf1f22360b336baf6e46aaec0080a22cddede2d/memory.soft_limit_in_bytes
134217728
4.6 不限制容器CPU
root@docker-server1:~# lscpu |grep CPU
CPU op-mode(s): 32-bit, 64-bit
CPU(s): 2
On-line CPU(s) list: 0,1
CPU family: 6
Model name: Intel(R) Core(TM) i5-8500 CPU @ 3.00GHz
CPU MHz: 3000.001
NUMA node0 CPU(s): 0,1
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
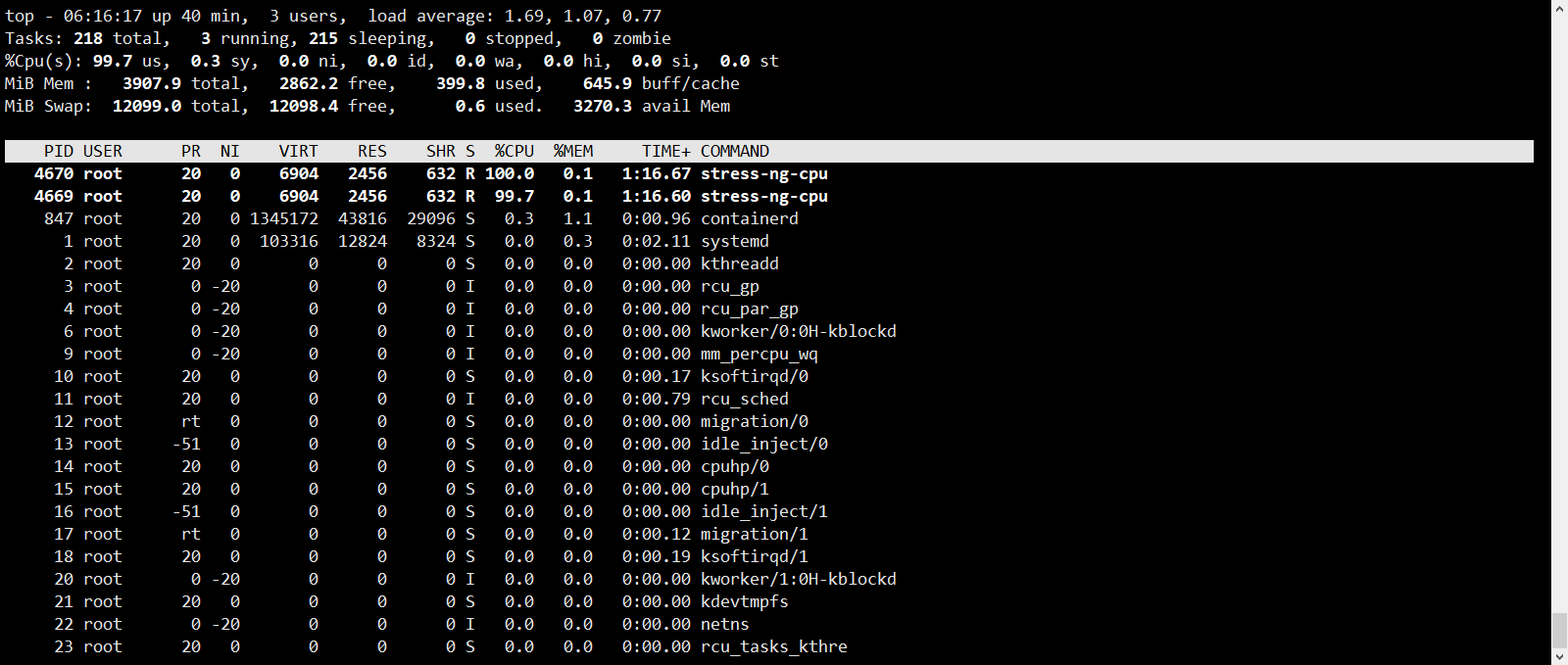
root@docker-server1:~# docker run -it --rm lorel/docker-stress-ng --cpu 2
stress-ng: info: [1] defaulting to a 86400 second run per stressor
stress-ng: info: [1] dispatching hogs: 2 cpu
root@docker-server1:~# docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
5c0987bbc2b7 naughty_yalow 198.96% 7.418MiB / 3.816GiB 0.19% 736B / 0B 0B / 0B 3
root@docker-server1:~# cat /sys/fs/cgroup/cpuset/docker/5c0987bbc2b7cd9de70f904e479b4eebe9032c234060ada4c4108ee7c7bcf3e2/cpuset.cpus
0-1
4.7 限制使用CPU
root@docker-server1:~# docker run -it --rm --cpus 1.5 lorel/docker-stress-ng --cpu 2
stress-ng: info: [1] defaulting to a 86400 second run per stressor
stress-ng: info: [1] dispatching hogs: 2 cpu
root@docker-server1:~# docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
84b885fd3928 pensive_kepler 148.46% 7.418MiB / 3.816GiB 0.19% 736B / 0B 0B / 0B 3

3.整理k8s master和node节点各组件的功能
kube-apiserver
运行在master节点上的核心组件,默认端口是6443,https协议,验证并配置API对象的数据,为REST操作提供服务,并为集群的共享状态提供前端,其它组件通过该前端进行交互,需要做高可用;
kube-controller-manager
运行在master节点上,包括一些子控制器(副本控制器、节点控制器、命名空间控制器和服务账号控制器等),控制器作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccont)、资源定额的管理(ResourceQuota),及时发现并执行自动化修复流程;
pod 高可用机制:
- node monitor period: 节点监视周期,5s
- node monitor grace period: 节点监视器宽限期,40s
- pod eviction timeout: pod驱逐超时时间,5m
kube-scheduler
- 一个控制面进程,负责将Pods指派到节点上,运行在master节点上;
- 通过调度算法为待调度Pod列表的每个Pod从可用Node列表中选择一个最适合的Node,并将信息写入etcd中。
- node节点上的kubelet通过API Server监听到kubernetes Scheduler产生的Pod绑定信息,然后获取对应的Pod清单,下载Image,并启动容器。
kubelet
运行在每个worker节点的代理组件,监视已分配给节点的Pod;
具体功能:
- 向master汇报node节点的状态信息
- 接受指令并在Pod中创建docker容器
- 准备Pod所需的数据卷
- 返回Pod的运行状态
- 在node节点执行容器健康检查
kube-proxy
维护当前主机的网络规则;运行在每个节点上,监听API Server中服务对象的变化,再通过管理 IPtables或者IPVS规则 来实现网络的转发。
Kube-Proxy 不同的版本可支持三种工作模式:
- UserSpace: k8s v1.1之前使用,k8s 1.2及以后就已经淘汰
- IPtables : k8s 1.1版本开始支持,1.2开始为默认
- IPVS: k8s 1.9引入到1.11为正式版本,需要安装ipvsadm、ipset工具包和加载 ip_vs 内核模块
etcd
是CoreOS公司开发目前是Kubernetes默认使用的key-value数据存储系统,用于保存kubernetes的所有集群数据,etcd支持分布式集群功能,生产环境使用时需要为etcd数据提供定期备份机制。
网络组件
DNS负责为整个集群提供DNS服务, 从而实现服务之间的访问。
4.部署高可用的k8s集群
1.环境准备
k8s-master1 192.168.24.188 ubuntu20.04
k8s-master2 192.168.24.189 ubuntu20.04
k8s-etcd1 192.168.24.190 ubuntu20.04
k8s-etcd2 192.168.24.191 ubuntu20.04
k8s-ha1 192.168.24.110 ubuntu20.04
k8s-ha2 192.168.24.111 ubuntu20.04
k8s-harbor1 192.168.24.150 ubuntu20.04
k8s-node1 192.168.24.201 ubuntu20.04
k8s-node2 192.168.24.202 ubuntu20.04
2.配置k8s-ha1和k8s-ha2
root@k8s-ha1:~# apt install keepalived haproxy
root@k8s-ha1:~# find / -name keepalived.conf*
/usr/share/man/man5/keepalived.conf.5.gz
/usr/share/doc/keepalived/keepalived.conf.SYNOPSIS
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.static_ipaddress
/usr/share/doc/keepalived/samples/keepalived.conf.misc_check
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.routes
/usr/share/doc/keepalived/samples/keepalived.conf.HTTP_GET.port
/usr/share/doc/keepalived/samples/keepalived.conf.status_code
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.sync
/usr/share/doc/keepalived/samples/keepalived.conf.SSL_GET
/usr/share/doc/keepalived/samples/keepalived.conf.fwmark
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.lvs_syncd
/usr/share/doc/keepalived/samples/keepalived.conf.IPv6
/usr/share/doc/keepalived/samples/keepalived.conf.conditional_conf
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.rules
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.scripts
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp.localcheck
/usr/share/doc/keepalived/samples/keepalived.conf.SMTP_CHECK
/usr/share/doc/keepalived/samples/keepalived.conf.virtual_server_group
/usr/share/doc/keepalived/samples/keepalived.conf.inhibit
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp
/usr/share/doc/keepalived/samples/keepalived.conf.quorum
/usr/share/doc/keepalived/samples/keepalived.conf.misc_check_arg
/usr/share/doc/keepalived/samples/keepalived.conf.virtualhost
/usr/share/doc/keepalived/samples/keepalived.conf.sample
/usr/share/doc/keepalived/samples/keepalived.conf.track_interface
/var/lib/dpkg/info/keepalived.conffiles
root@k8s-ha1:~# cp /usr/share/doc/keepalived/samples/keepalived.conf.vrrp /etc/keepalived/keepalived.conf
root@k8s-ha1:~# vim /etc/keepalived/keepalived.conf
root@k8s-ha1:~# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state MASTER
interface ens33
garp_master_delay 10
smtp_alert
virtual_router_id 60
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.24.118 dev ens33 label ens33:0
192.168.24.119 dev ens33 label ens33:1
192.168.24.120 dev ens33 label ens33:2
192.168.24.121 dev ens33 label ens33:3
}
}
root@k8s-ha1:~# systemctl restart keepalived.service
root@k8s-ha1:~# scp /etc/keepalived/keepalived.conf 192.168.24.111:/etc/keepalived/keepalived.conf
The authenticity of host '192.168.24.111 (192.168.24.111)' can't be established.
ECDSA key fingerprint is SHA256:MBg2Eob/YaRDMuslxaYuvzjpOBkNc5Ln2wd7mHHdv+0.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '192.168.24.111' (ECDSA) to the list of known hosts.
root@192.168.24.111's password:
keepalived.conf 100% 680 1.1MB/s 00:00
root@k8s-ha2:~# apt install keepalived haproxy
root@k8s-ha2:~# vim /etc/keepalived/keepalived.conf
root@k8s-ha2:~# vim /etc/keepalived/keepalived.conf
root@k8s-ha2:~# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
acassen
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
garp_master_delay 10
smtp_alert
virtual_router_id 60
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.24.118 dev ens33 label ens33:0
192.168.24.119 dev ens33 label ens33:1
192.168.24.120 dev ens33 label ens33:2
192.168.24.121 dev ens33 label ens33:3
}
}
root@k8s-ha2:~# systemctl restart keepalived.service
##验证keepalived服务
root@k8s-ha1:~# systemctl stop keepalived
root@k8s-ha2:~# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.24.111 netmask 255.255.255.0 broadcast 192.168.24.255
inet6 fe80::20c:29ff:fef3:b92d prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:f3:b9:2d txqueuelen 1000 (Ethernet)
RX packets 4417 bytes 5477115 (5.4 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1189 bytes 138927 (138.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.24.118 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:0c:29:f3:b9:2d txqueuelen 1000 (Ethernet)
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.24.119 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:0c:29:f3:b9:2d txqueuelen 1000 (Ethernet)
ens33:2: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.24.120 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:0c:29:f3:b9:2d txqueuelen 1000 (Ethernet)
ens33:3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.24.121 netmask 255.255.255.255 broadcast 0.0.0.0
ether 00:0c:29:f3:b9:2d txqueuelen 1000 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 106 bytes 8496 (8.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 106 bytes 8496 (8.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@k8s-ha1:~# systemctl start keepalived
root@k8s-ha1:~# systemctl enable keepalived
Synchronizing state of keepalived.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable keepalived
root@k8s-ha2:~# systemctl enable keepalived
Synchronizing state of keepalived.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable keepalived
##配置haproxy
root@k8s-ha1:~# vim /etc/haproxy/haproxy.cfg
listen k8s-6443
bind 192.168.24.118:6443
mode tcp
server 192.168.24.188 192.168.24.188:6443 check inter 2s fall 3 rise 3
server 192.168.24.189 192.168.24.189:6443 check inter 2s fall 3 rise 3
root@k8s-ha1:~# systemctl restart haproxy.service
root@k8s-ha1:~# ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 127.0.0.1:6010 0.0.0.0:*
LISTEN 0 492 192.168.24.118:6443 0.0.0.0:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 128 [::1]:6010 [::]:*
root@k8s-ha1:~# systemctl enable haproxy.service
Synchronizing state of haproxy.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable haproxy
root@k8s-ha1:~# scp /etc/haproxy/haproxy.cfg 192.168.24.111:/etc/haproxy/haproxy.cfg
root@192.168.24.111's password:
haproxy.cfg 100% 1508 2.1MB/s 00:00
root@k8s-ha2:~# sysctl -a |grep local
net.ipv4.conf.all.accept_local = 0
net.ipv4.conf.all.route_localnet = 0
net.ipv4.conf.default.accept_local = 0
net.ipv4.conf.default.route_localnet = 0
net.ipv4.conf.ens33.accept_local = 0
net.ipv4.conf.ens33.route_localnet = 0
net.ipv4.conf.lo.accept_local = 0
net.ipv4.conf.lo.route_localnet = 0
net.ipv4.igmp_link_local_mcast_reports = 1
net.ipv4.ip_local_port_range = 32768 60999
net.ipv4.ip_local_reserved_ports =
net.ipv4.ip_nonlocal_bind = 0
net.ipv6.conf.all.accept_ra_from_local = 0
net.ipv6.conf.default.accept_ra_from_local = 0
net.ipv6.conf.ens33.accept_ra_from_local = 0
net.ipv6.conf.lo.accept_ra_from_local = 0
net.ipv6.ip_nonlocal_bind = 0
root@k8s-ha2:~# vim /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind = 1
root@k8s-ha2:~# sysctl -p
net.ipv4.ip_nonlocal_bind = 1
root@k8s-ha2:~# systemctl restart haproxy.service
root@k8s-ha2:~# ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 492 192.168.24.118:6443 0.0.0.0:*
LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 127.0.0.1:6010 0.0.0.0:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 128 [::1]:6010 [::]:*
3.配置k8s-harbor1
root@k8s-harbor1:~# cd /usr/local/src/
root@k8s-harbor1:/usr/local/src# ll
total 76336
drwxr-xr-x 2 root root 4096 Jan 8 06:29 ./
drwxr-xr-x 10 root root 4096 Aug 24 08:42 ../
-rw-r--r-- 1 root root 78156440 Jan 8 06:28 docker-19.03.15-binary-install.tar.gz
root@k8s-harbor1:/usr/local/src# tar xvf docker-19.03.15-binary-install.tar.gz
root@k8s-harbor1:/usr/local/src# ll
total 153128
drwxr-xr-x 2 root root 4096 Apr 11 2021 ./
drwxr-xr-x 10 root root 4096 Aug 24 08:42 ../
-rw-r--r-- 1 root root 647 Apr 11 2021 containerd.service
-rw-r--r-- 1 root root 78156440 Jan 8 06:28 docker-19.03.15-binary-install.tar.gz
-rw-r--r-- 1 root root 62436240 Feb 5 2021 docker-19.03.15.tgz
-rwxr-xr-x 1 root root 16168192 Jun 24 2019 docker-compose-Linux-x86_64_1.24.1*
-rwxr-xr-x 1 root root 2708 Apr 11 2021 docker-install.sh*
-rw-r--r-- 1 root root 1683 Apr 11 2021 docker.service
-rw-r--r-- 1 root root 197 Apr 11 2021 docker.socket
-rw-r--r-- 1 root root 454 Apr 11 2021 limits.conf
-rw-r--r-- 1 root root 257 Apr 11 2021 sysctl.conf
root@k8s-harbor1:/usr/local/src# bash docker-install.sh
当前系统是Ubuntu 20.04.3 LTS \n \l,即将开始系统初始化、配置docker-compose与安装docker
docker/
docker/dockerd
docker/docker-proxy
docker/containerd-shim
docker/docker-init
docker/docker
docker/runc
docker/ctr
docker/containerd
docker 安装完成!
groupadd: group 'magedu' already exists
useradd: user 'magedu' already exists
Created symlink /etc/systemd/system/multi-user.target.wants/containerd.service → /lib/systemd/system/containerd.service.
Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /lib/systemd/system/docker.service.
Created symlink /etc/systemd/system/sockets.target.wants/docker.socket → /lib/systemd/system/docker.socket.
root@k8s-harbor1:~# mkdir /apps
root@k8s-harbor1:~# cd /apps/
root@k8s-harbor1:/apps#
root@k8s-harbor1:/apps# ll
total 598348
drwxr-xr-x 2 root root 4096 Jan 8 06:36 ./
drwxr-xr-x 22 root root 4096 Jan 8 06:34 ../
-rw-r--r-- 1 root root 612698835 Jan 8 06:28 harbor-offline-installer-v2.4.1.tgz
root@k8s-harbor1:/apps# tar xvf harbor-offline-installer-v2.4.1.tgz
root@k8s-harbor1:/apps# cd harbor/
root@k8s-harbor1:/apps/harbor# ll
total 601620
drwxr-xr-x 2 root root 4096 Jan 8 06:38 ./
drwxr-xr-x 3 root root 4096 Jan 8 06:37 ../
-rw-r--r-- 1 root root 3361 Dec 16 04:22 common.sh
-rw-r--r-- 1 root root 616006217 Dec 16 04:23 harbor.v2.4.1.tar.gz
-rw-r--r-- 1 root root 8999 Dec 16 04:22 harbor.yml.tmpl
-rwxr-xr-x 1 root root 2500 Dec 16 04:22 install.sh*
-rw-r--r-- 1 root root 11347 Dec 16 04:22 LICENSE
-rwxr-xr-x 1 root root 1881 Dec 16 04:22 prepare*
root@k8s-harbor1:/apps/harbor# cp harbor.yml.tmpl harbor.yml
root@k8s-harbor1:/apps/harbor# vim harbor.yml
##修改以下两行
hostname: harbor.kevin.net
harbor_admin_password: 123456
##签发加密证书
root@k8s-harbor1:/apps/harbor# mkdir certs
root@k8s-harbor1:/apps/harbor# cd certs/
root@k8s-harbor1:/apps/harbor/certs# ll
total 8
drwxr-xr-x 2 root root 4096 Jan 8 06:42 ./
drwxr-xr-x 3 root root 4096 Jan 8 06:42 ../
root@k8s-harbor1:/apps/harbor/certs# openssl genrsa -out ./harbor-ca.key
root@k8s-harbor1:/apps/harbor/certs# openssl req -x509 -new -nodes -key ./harbor-ca.key -subj "/CN=harbor.kevin.net" -days 3650 -out ./harbor-ca.crt
root@k8s-harbor1:/apps/harbor/certs# ll
total 16
drwxr-xr-x 2 root root 4096 Jan 8 06:48 ./
drwxr-xr-x 3 root root 4096 Jan 8 06:42 ../
-rw-r--r-- 1 root root 1131 Jan 8 06:48 harbor-ca.crt
-rw------- 1 root root 1679 Jan 8 06:44 harbor-ca.key
root@k8s-harbor1:/apps/harbor# vim harbor.yml
##修改以下两行
certificate: /apps/harbor/certs/harbor-ca.crt
private_key: /apps/harbor/certs/harbor-ca.key
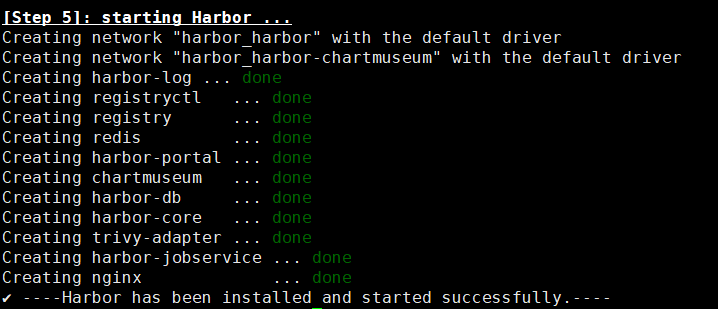
root@k8s-harbor1:/apps/harbor# ./install.sh --with-trivy --with-chartmuseum
4.配置master1
root@k8s-master1:~# apt install ansible
##配置免密验证
root@k8s-master1:~# ssh-keygen
root@k8s-master1:~# ssh-copy-id 192.168.24.188
root@k8s-master1:~# ssh-copy-id 192.168.24.189
root@k8s-master1:~# ssh-copy-id 192.168.24.190
root@k8s-master1:~# ssh-copy-id 192.168.24.191
root@k8s-master1:~# ssh-copy-id 192.168.24.201
root@k8s-master1:~# ssh-copy-id 192.168.24.202
##下载安装k8s
root@k8s-master1:~# export release=3.2.0
root@k8s-master1:~# wget https://github.com/easzlab/kubeasz/releases/download/${release}/ezdown
root@k8s-master1:~# chmod a+x ezdown
root@k8s-master1:~# ll
total 72
drwx------ 5 root root 4096 Jan 8 07:15 ./
drwxr-xr-x 21 root root 4096 Dec 27 13:15 ../
-rw------- 1 root root 275 Jan 6 13:28 .bash_history
-rw-r--r-- 1 root root 3106 Dec 5 2019 .bashrc
drwx------ 2 root root 4096 Dec 27 14:34 .cache/
-rwxr-xr-x 1 root root 15351 Jan 8 07:15 ezdown*
-rw-r--r-- 1 root root 161 Dec 5 2019 .profile
drwxr-xr-x 3 root root 4096 Dec 27 13:33 snap/
drwx------ 2 root root 4096 Jan 8 07:04 .ssh/
-rw------- 1 root root 15769 Jan 8 07:15 .viminfo
-rw-r--r-- 1 root root 165 Jan 8 07:10 .wget-hsts
-rw------- 1 root root 117 Jan 8 05:25 .Xauthority
root@k8s-master1:~# ./ezdown -D
root@k8s-master1:~# cd /etc/kubeasz/
root@k8s-master1:/etc/kubeasz# ./ezctl new k8s-cluster1
2022-01-08 07:49:33 DEBUG generate custom cluster files in /etc/kubeasz/clusters/k8s-cluster1
2022-01-08 07:49:33 DEBUG set versions
2022-01-08 07:49:33 DEBUG cluster k8s-cluster1: files successfully created.
2022-01-08 07:49:33 INFO next steps 1: to config '/etc/kubeasz/clusters/k8s-cluster1/hosts'
2022-01-08 07:49:33 INFO next steps 2: to config '/etc/kubeasz/clusters/k8s-cluster1/config.yml'
root@k8s-master1:/etc/kubeasz# cd clusters/k8s-cluster1/
root@k8s-master1:/etc/kubeasz/clusters/k8s-cluster1# vim hosts
root@k8s-master1:/etc/kubeasz/clusters/k8s-cluster1# cat hosts
# 'etcd' cluster should have odd member(s) (1,3,5,...)
[etcd]
192.168.24.190
192.168.24.191
# master node(s)
[kube_master]
192.168.24.188
192.168.24.189
# work node(s)
[kube_node]
192.168.24.201
192.168.24.202
# [optional] harbor server, a private docker registry
# 'NEW_INSTALL': 'true' to install a harbor server; 'false' to integrate with existed one
[harbor]
#192.168.1.8 NEW_INSTALL=false
# [optional] loadbalance for accessing k8s from outside
[ex_lb]
192.168.24.110 LB_ROLE=master EX_APISERVER_VIP=192.168.24.118 EX_APISERVER_PORT=6443
192.168.24.111 LB_ROLE=backup EX_APISERVER_VIP=192.168.24.118 EX_APISERVER_PORT=6443
# [optional] ntp server for the cluster
[chrony]
#192.168.1.1
[all:vars]
# --------- Main Variables ---------------
# Secure port for apiservers
SECURE_PORT="6443"
# Cluster container-runtime supported: docker, containerd
CONTAINER_RUNTIME="docker"
# Network plugins supported: calico, flannel, kube-router, cilium, kube-ovn
CLUSTER_NETWORK="calico"
# Service proxy mode of kube-proxy: 'iptables' or 'ipvs'
PROXY_MODE="ipvs"
# K8S Service CIDR, not overlap with node(host) networking
SERVICE_CIDR="10.100.0.0/16"
# Cluster CIDR (Pod CIDR), not overlap with node(host) networking
CLUSTER_CIDR="10.200.0.0/16"
# NodePort Range
NODE_PORT_RANGE="30000-40000"
# Cluster DNS Domain
CLUSTER_DNS_DOMAIN="cluster.local"
# -------- Additional Variables (don't change the default value right now) ---
# Binaries Directory
bin_dir="/usr/bin"
# Deploy Directory (kubeasz workspace)
base_dir="/etc/kubeasz"
# Directory for a specific cluster
cluster_dir="{{ base_dir }}/clusters/k8s-cluster1"
# CA and other components cert/key Directory
ca_dir="/etc/kubernetes/ssl"
root@k8s-master1:/etc/kubeasz/clusters/k8s-cluster1# vim config.yml
##修改以下内容
# node节点最大pod 数
MAX_PODS: 400
# coredns 自动安装
dns_install: "no"
corednsVer: "1.8.6"
ENABLE_LOCAL_DNS_CACHE: no
dnsNodeCacheVer: "1.21.1"
# 设置 local dns cache 地址
LOCAL_DNS_CACHE: "169.254.20.10"
# metric server 自动安装
metricsserver_install: "no"
metricsVer: "v0.5.2"
# dashboard 自动安装
dashboard_install: "no"
dashboardVer: "v2.4.0"
dashboardMetricsScraperVer: "v1.0.7"
root@k8s-master1:/etc/kubeasz# vim playbooks/01.prepare.yml
##删除以下两行
- ex_lb
- chrony
root@k8s-master1:/etc/kubeasz# pwd
/etc/kubeasz
root@k8s-master1:/etc/kubeasz# ./ezctl setup k8s-cluster1 01
root@k8s-master1:/etc/kubeasz# ./ezctl setup k8s-cluster1 02
root@k8s-etcd1:~# export NODE_IPS="192.168.24.190 192.168.24.191"
root@k8s-etcd1:~# ls /etc/kubernetes/ssl/
ca.pem etcd-key.pem etcd.pem
root@k8s-etcd1:~# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done
https://192.168.24.190:2379 is healthy: successfully committed proposal: took = 14.856446ms
https://192.168.24.191:2379 is healthy: successfully committed proposal: took = 16.384883ms
root@k8s-master1:/etc/kubeasz# ./ezctl setup k8s-cluster1 03
root@k8s-master1:/etc/kubeasz# ./ezctl setup k8s-cluster1 04
root@k8s-master1:/etc/kubeasz# kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.24.188 Ready,SchedulingDisabled master 36s v1.22.2
192.168.24.189 Ready,SchedulingDisabled master 35s v1.22.2
root@k8s-master1:/etc/kubeasz# ./ezctl setup k8s-cluster1 05
root@k8s-master1:/etc/kubeasz# kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.24.188 Ready,SchedulingDisabled master 6m50s v1.22.2
192.168.24.189 Ready,SchedulingDisabled master 6m49s v1.22.2
192.168.24.201 Ready node 2m33s v1.22.2
192.168.24.202 Ready node 2m33s v1.22.2
root@k8s-master1:/etc/kubeasz# ./ezctl setup k8s-cluster1 06
root@k8s-master1:/etc/kubeasz# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-864c65f46c-7gcvt 1/1 Running 0 2m10s
kube-system calico-node-2vt85 1/1 Running 0 2m9s
kube-system calico-node-6dcbp 1/1 Running 0 2m10s
kube-system calico-node-trnbj 1/1 Running 0 2m10s
kube-system calico-node-vmm5c 1/1 Running 0 2m10s
root@k8s-master1:/etc/kubeasz# calicoctl node status
Calico process is running.
IPv4 BGP status
+----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+----------------+-------------------+-------+----------+-------------+
| 192.168.24.189 | node-to-node mesh | up | 13:38:20 | Established |
| 192.168.24.201 | node-to-node mesh | up | 13:38:19 | Established |
| 192.168.24.202 | node-to-node mesh | up | 13:38:19 | Established |
+----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
5.验证k8s pod能否上网
root@k8s-master1:/etc/kubeasz# kubectl run net-test1 --image=alpine sleep 500000
root@k8s-master1:/etc/kubeasz# kubectl run net-test2 --image=alpine sleep 500000
root@k8s-master1:/etc/kubeasz# kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default net-test1 1/1 Running 0 77s 10.200.169.129 192.168.24.202 <none> <none>
default net-test2 1/1 Running 0 69s 10.200.36.65 192.168.24.201 <none> <none>
kube-system calico-kube-controllers-864c65f46c-7gcvt 1/1 Running 0 7m26s 192.168.24.201 192.168.24.201 <none> <none>
kube-system calico-node-2vt85 1/1 Running 0 7m25s 192.168.24.189 192.168.24.189 <none> <none>
kube-system calico-node-6dcbp 1/1 Running 0 7m26s 192.168.24.188 192.168.24.188 <none> <none>
kube-system calico-node-trnbj 1/1 Running 0 7m26s 192.168.24.201 192.168.24.201 <none> <none>
kube-system calico-node-vmm5c 1/1 Running 0 7m26s 192.168.24.202 192.168.24.202 <none> <none>
root@k8s-master1:/etc/kubeasz# kubectl exec -it net-test1 sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ # ifconfig
eth0 Link encap:Ethernet HWaddr AE:B5:5B:BB:AB:4A
inet addr:10.200.169.129 Bcast:10.200.169.129 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:5 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:446 (446.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 10.200.36.65
PING 10.200.36.65 (10.200.36.65): 56 data bytes
64 bytes from 10.200.36.65: seq=0 ttl=62 time=0.767 ms
64 bytes from 10.200.36.65: seq=1 ttl=62 time=0.541 ms
^C
--- 10.200.36.65 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.541/0.654/0.767 ms
/ # ping 223.6.6.6
PING 223.6.6.6 (223.6.6.6): 56 data bytes
64 bytes from 223.6.6.6: seq=0 ttl=127 time=10.898 ms
64 bytes from 223.6.6.6: seq=1 ttl=127 time=24.021 ms
^C
--- 223.6.6.6 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 10.898/17.459/24.021 ms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号