小爬爬5:scrapy介绍3持久化存储
一.两种持久化存储的方式
1.基于终端指令的吃持久化存储:
特点:终端指令的持久化存储,只可以将parse方法的返回值存储到磁盘文件
因此我们需要将上一篇文章中的author和content作为返回值的内容,我们可以将所有内容数据放在列表中,
每个字典存储作者名字和内容,最好将定义的列表返回即可
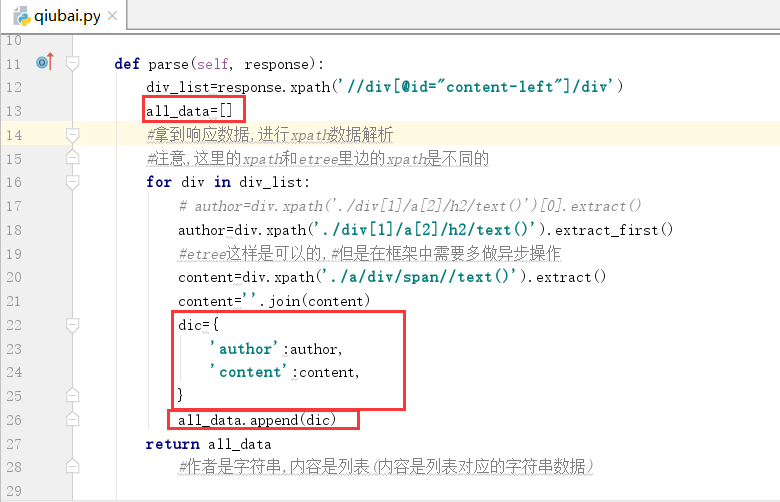
我们在下图的终端中运行下面的命令

我们右击整个爬虫工程,点击下面的选项,同步产生的数据
我们得到下面的qiubai.csv内容
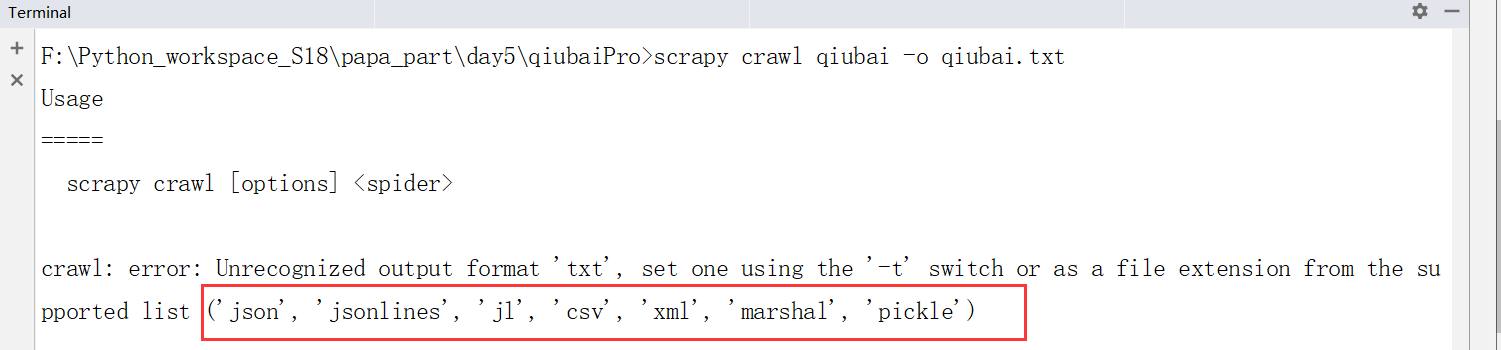
思考可不可以保存到txt后缀的文件中?只支持下面的文件格式,因此不支持
基于终端的命令:scrapy crawl qiubai -o qiubai.csv
优点:便捷
缺点:局限性强(只可以将数据写入本地文件,文件后缀是由具体要求)
2.基于管道的持久化存储
基于管道:
基于持久化存储的所有操作都必须写入到管道文件的管道类中
open io 以及数据库(mysql,redis等),pymysql等等都是基于持久化的存储操作
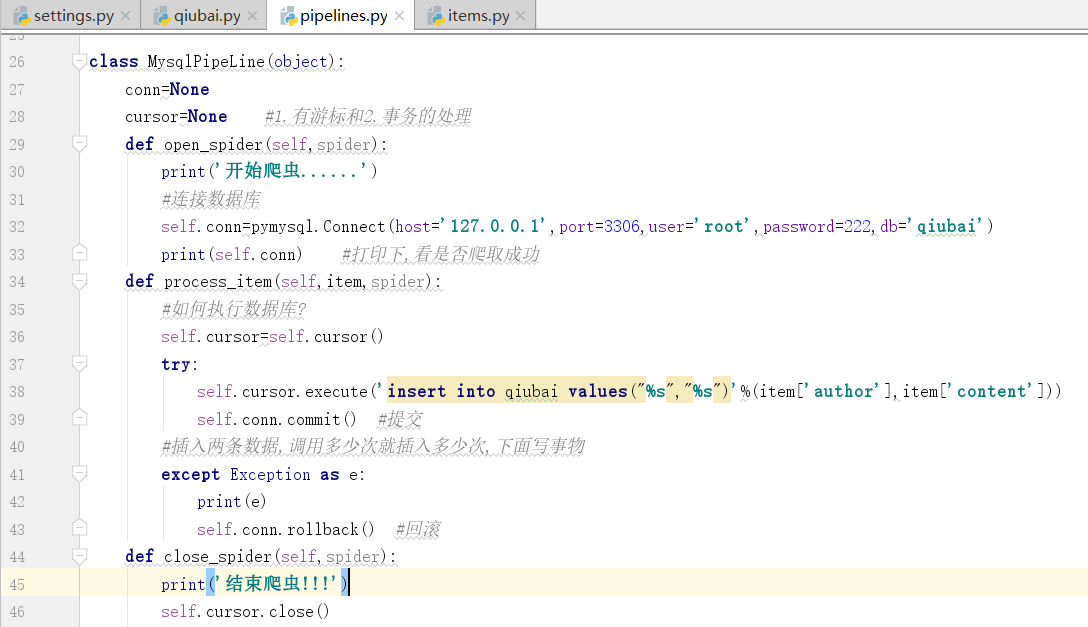
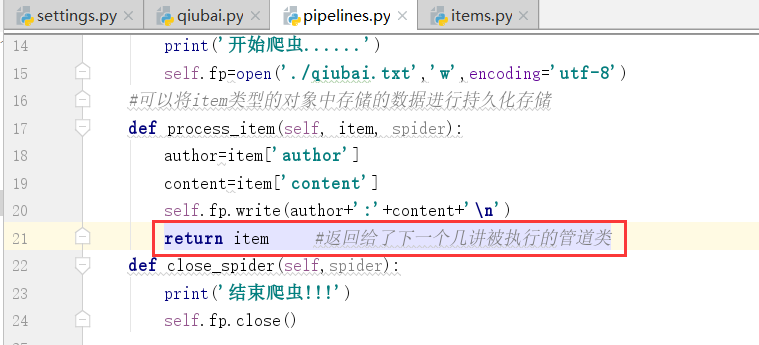
我们看到这个pipelines.py文件,以及这个文件中一个类
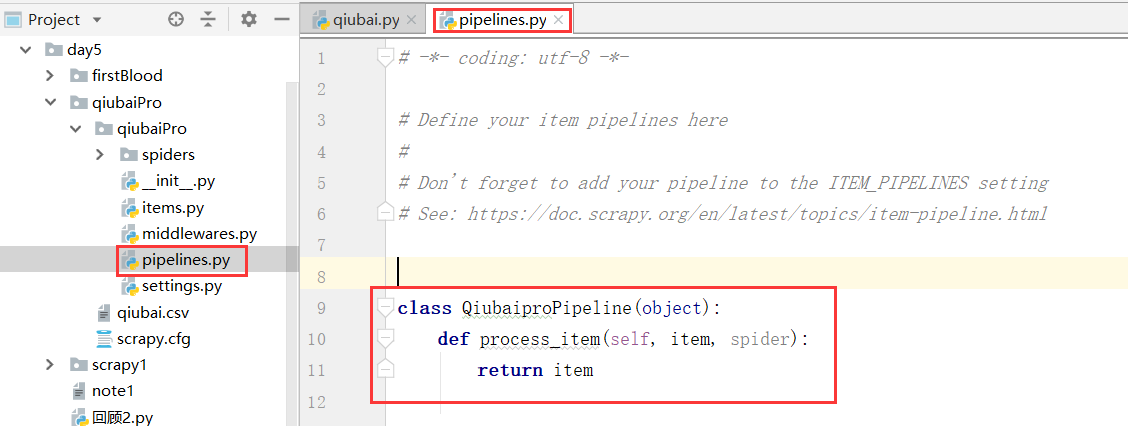
我们看到这个管道类中有一个item方法,以及item参数,只可以处理item类型的对象
#可以将item类型的对象中存储的数据进行持久化存储
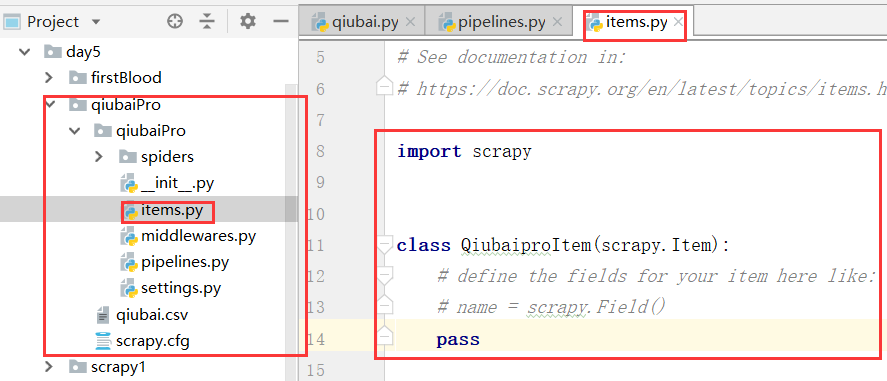
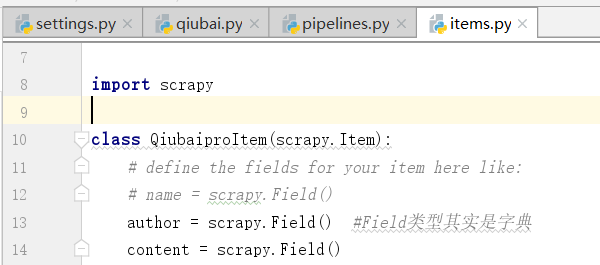
通过item类型的对象进行处理,我们通过对上边的数据写入items.py文件进行处理
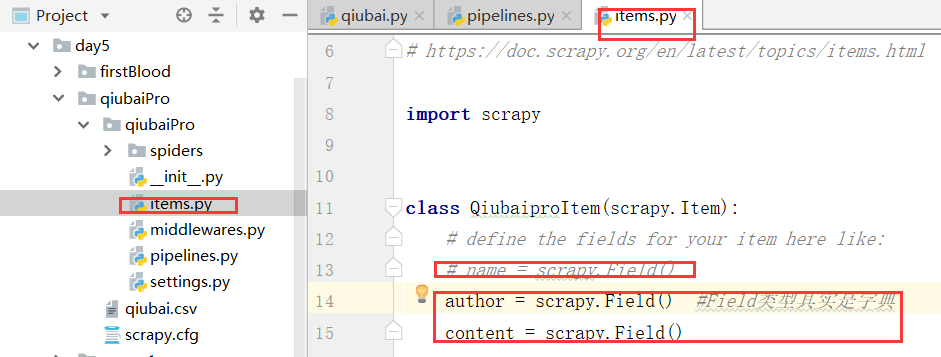
下面我们进行定制,我们参考的是给定的公式
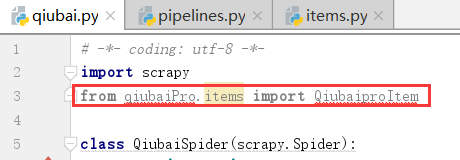
下面我们再爬虫文件中导入类,爆红是不一定代表出错,在这里可以体现
下面我们可以实例化这个item对象,
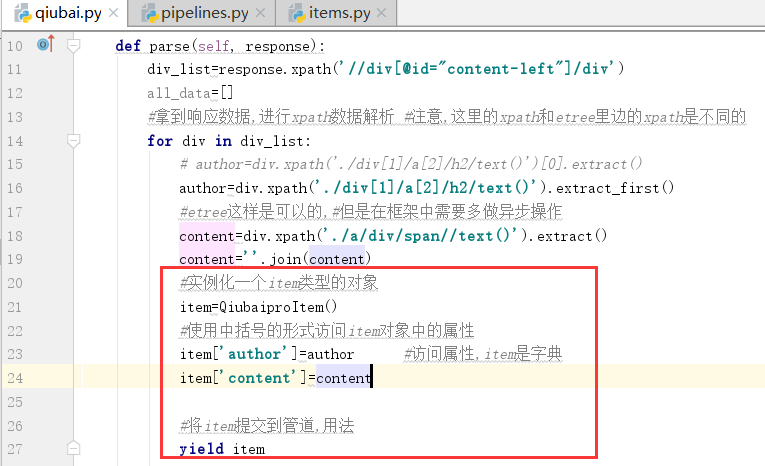
上边的for循环执行几次,在下面的process_item执行几次
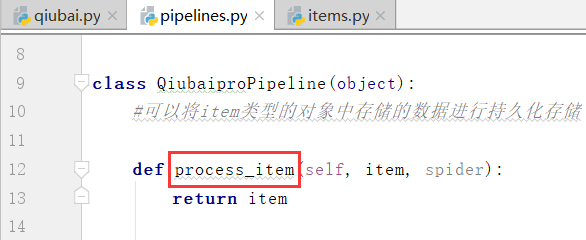
写完函数:
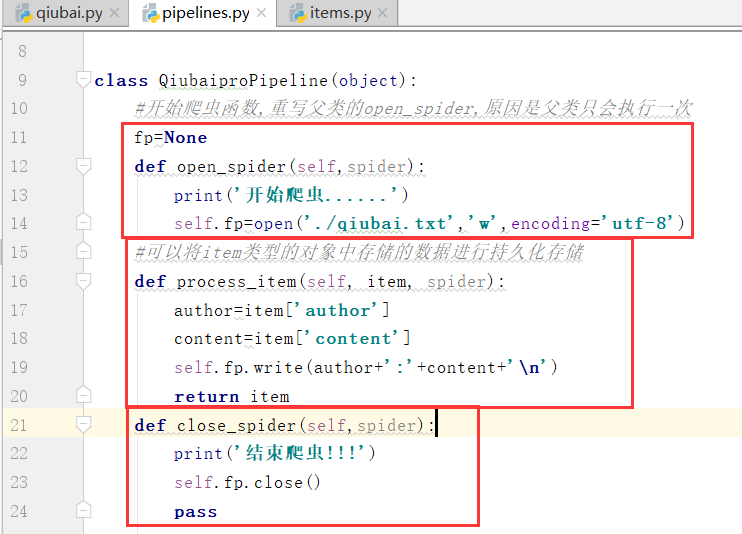
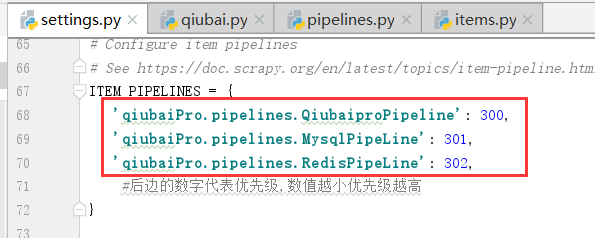
写完函数,我们需要在settings.py配置文件中开启管道.

什么时间定义多个管道类?items.py文件中的什么时间定义成字符串类型?
运行下面的命令:
![]()
我们看到下面的开始和结束爬虫


这个时候,我们生成了一个txt持久化的文件
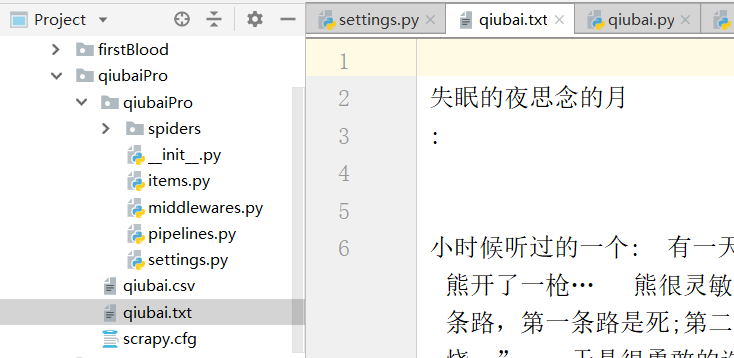
注意,下图为什么不用字符串类型,用json类型?Field是万能的数据类型,什么都能存储
思考,什么时间定义多个管道?
一份redis,一份本地存储,一份mysql,这个时候就需要多个管道类
导入一个pymysql
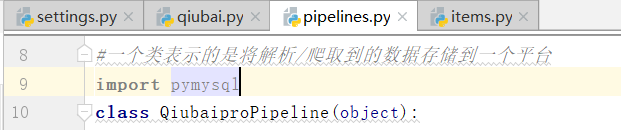
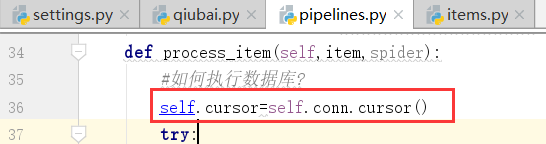
登录数据库



下面,我们新建一个数据库

下面创建一个表

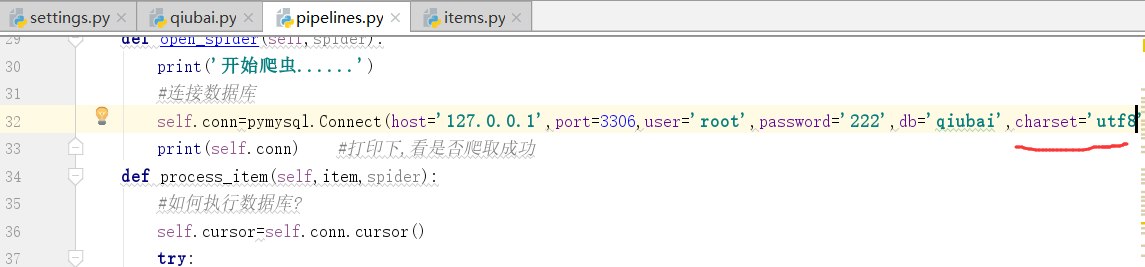
下面,我们连接数据库
在open中连接数据库
mysql端口:3306
redis端口:6379
修改下面的管道配置文件settings.py
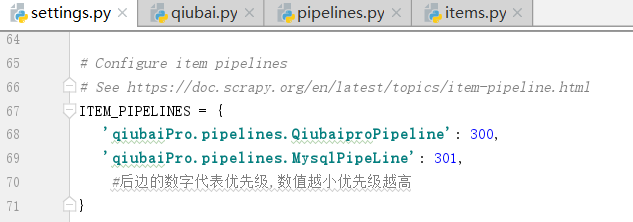
现在有两个管道类,谁先执行

我们的爬虫文件只提交了一个item,我们该如何处理?按照顺序,一定是献给了Qiubai,因为上边的这个数字Qiubai比Mysql小
当第一个类处理完item,第二个没有item了,我们该如何操作?
我们没有说哦process_item的返回值是什么?也就是这个函数有返回值,返回给的是下一个执行的管道类也就是item,症结就在这个地方
以此类推,我们加上这么一个管道类的返回值
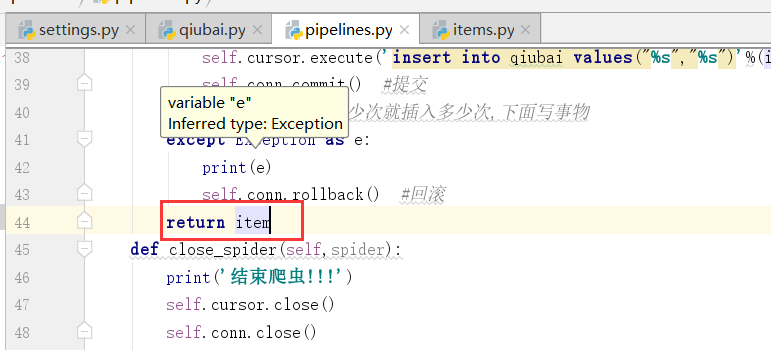
下面执行一下,看是否会有错,可能会出现数据库编码的问题
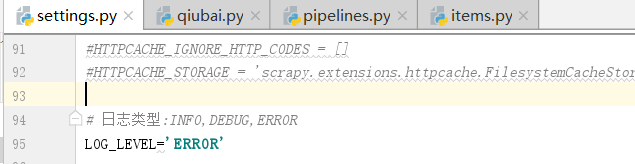
总结数据库日志类型:INFO,DEBUG,ERROR
我们可以指定日志输出的类型
运行得到下面的结果:

原因:
运行,得到下面的结果:

在执行这个过程中可能会出现编码问题,如何修改?

我们在连接的时候加上

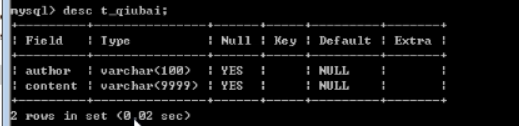
查看上边表qiubai的信息
我们在分布式的时候会用到redis
启动redis

导入redis包
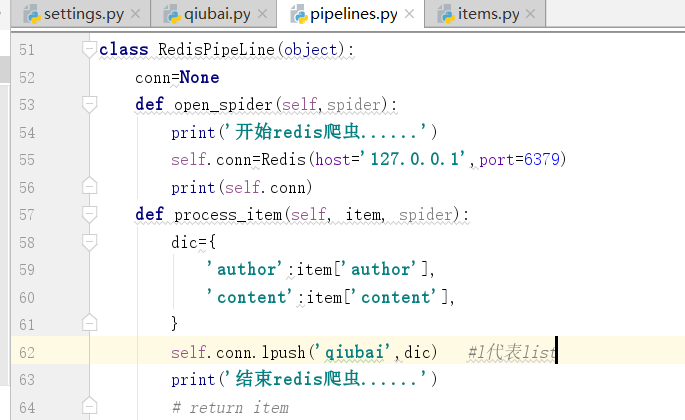
下面开始写类
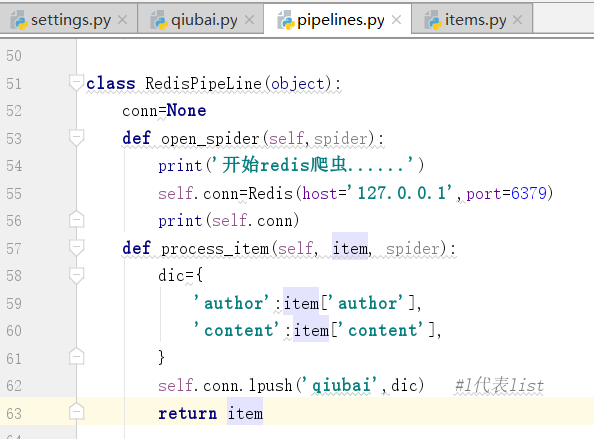
=
重新安装redis,换成2的版本
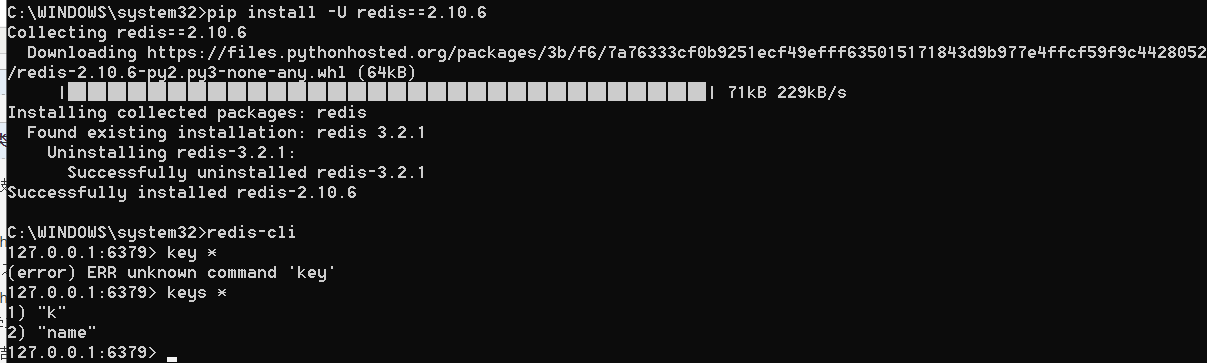
再次运行,我们可以成功执行
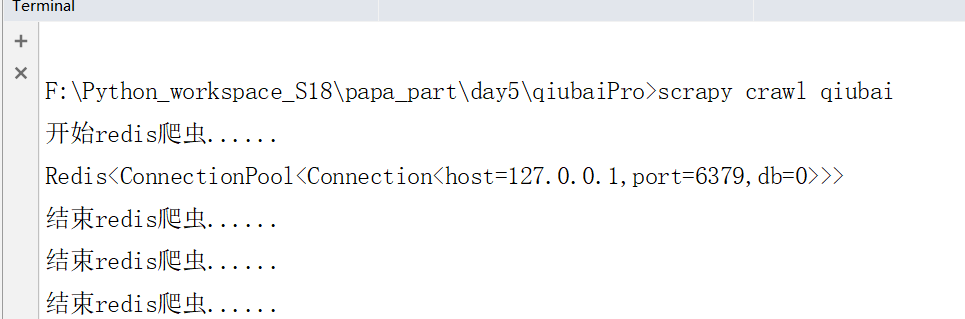
我们可以看到下面的内容qiubai
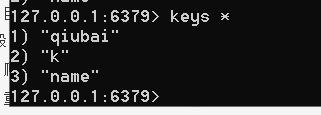
之一txt和mysql以及redis不能混合使用,容易报错
运行下面的命令,我们可以看到一串二进制数字.

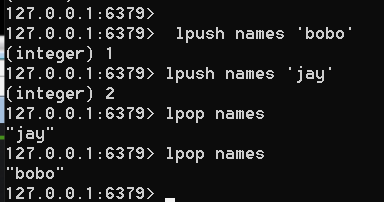
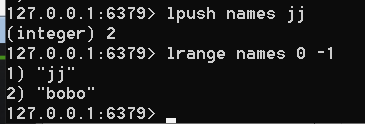
lpush names 'bobo'
添加和删除,见下图
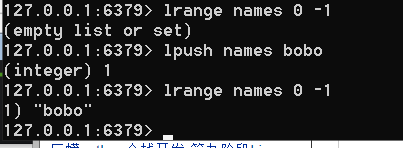
0到-1是全部取出,得到下面的内容
现在,我们只是发起了一个页面,我们将所有页码的url都放在start_urls列表中
如何爬取多个页码中的数据,请看下一节

 浙公网安备 33010602011771号
浙公网安备 33010602011771号