





Spark扩展内容
宽依赖和窄依赖
- 窄依赖(Narrow Dependency):指父RDD的每个分区只被子RDD的一个分区所使用,例如map、filter等这些算子
一个RDD,对它的父RDD只有简单的一对一的关系,也就是说,RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间的对应关系,是一对一的。 - 宽依赖(Shuffle Dependency):父RDD的每个分区都可能被子RDD的多个分区使用,例如groupByKey、reduceByKey,sortBykey等算子,这些算子其实都会产生shuffle操作
也就是说,每一个父RDD的partition中的数据都可能会传输一部分到下一个RDD的每个partition中。此时就会出现,父RDD和子RDD的partition之间,具有错综复杂的关系,那么,这种情况就叫做两个RDD之间是宽依赖,同时,它们之间会发生shuffle操作。
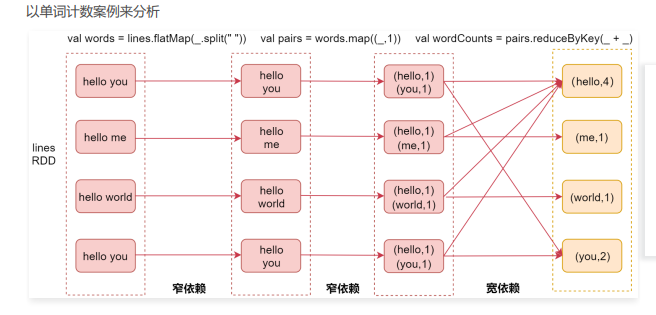
最左侧是linesRDD,这个表示我们通过textFile读取文件中的数据之后获取的RDD
接着是我们使用flatMap算子,对每一行数据按照空格切开,然后可以获取到第二个RDD,这个RDD中包含的是切开的每一个单词
在这里这两个RDD就属于一个窄依赖,因为父RDD的每个分区只被子RDD的一个分区所使用,也就是说他们的分区是一对一的,这样就不需要经过shuffle了。
接着是使用map算子,将每一个单词转换成(单词,1)这种形式,此时这两个RDD也是一个窄依赖的关系,父RDD的分区和子RDD的分区也是一对一的
最后我们会调用reduceByKey算子,此时会对相同key的数据进行分组,分到一个分区里面,并且进行聚合操作,此时父RDD的每个分区都可能被子RDD的多个分区使用,那这两个RDD就属于宽依赖了。
Stage
spark job是根据action算子触发的,遇到action算子就会起一个job
Spark Job会被划分为多个Stage,每一个Stage是由一组并行的Task组成的
注意:stage的划分依据就是看是否产生了shuflle(即宽依赖),遇到一个shuffle操作就划分为前后两个stage
stage是由一组并行的task组成,stage会将一批task用TaskSet来封装,提交给TaskScheduler进行分配,最后发送到Executor执行
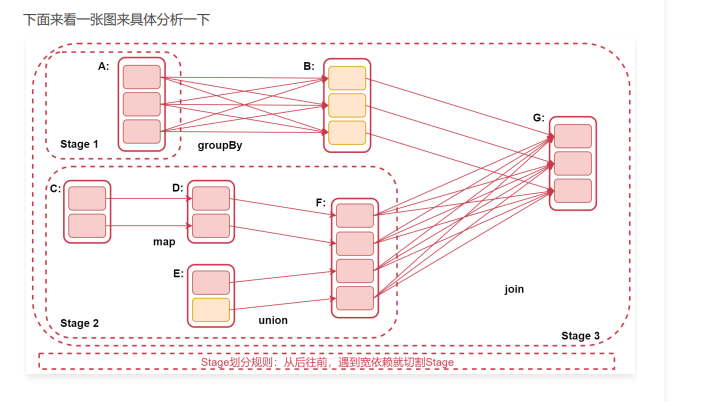
注意:Stage的划分规则:从后往前,遇到宽依赖就划分Stage
为什么是从后往前呢?因为RDD之间是有血缘关系的,后面的RDD依赖前面的RDD,也就是说后面的RDD要等前面的RDD执行完,才会执行。所以从后往前遇到宽依赖就划分为两个stage,shuffle前一个,shuffle后一个。如果整个过程没有产生shuffle那就只会有一个stage
看这个图
RDD G 往前推,到RDD B的时候,是窄依赖,所以不切分Stage,再往前到RDD A,此时产生了宽依赖,所以RDD A属于一个Stage、RDD B 和 G属于一个Stage
再看下面,RDD G到RDD F,产生了宽依赖,所以RDD F属于一个Stage,因为RDD F和 RDD C、D、E这几个RDD没有产生宽依赖,都是窄依赖,所以他们属于一个Stage。
所以这个图中,RDD A 单独一个stage1,RDD C、D、E、F被划分在stage2中,最后RDD B和RDD G划分在了stage3 里面.
注意:Stage划分是从后往前划分,但是stage执行时从前往后的,这就是为什么后面先切割的stage为什么编号是3.
Spark Job的三种提交模式
- 第一种,standalone模式,基于Spark自己的standalone集群。指定–master spark://bigdata01:7077
- 第二种,是基于YARN的client模式。
指定–master yarn --deploy-mode client
这种方式主要用于测试,查看日志方便一些,部分日志会直接打印到控制台上面,因为driver进程运行在本地客户端,就是提交Spark任务的那个客户端机器,driver负责调度job,会与yarn集群产生大量的通信,一般情况下Spark客户端机器和Hadoop集群的机器是无法内网通信,只能通过外网,这样在大量通信的情况下会影响通信效率,并且当我们执行一些action操作的时候数据也会返回给driver端,driver端机器的配置一般都不高,可能会导致内存溢出等问题。 - 第三种,是基于YARN的cluster模式。【推荐】
指定–master yarn --deploy-mode cluster
这种方式driver进程运行在集群中的某一台机器上,这样集群内部节点之间通信是可以通过内网通信的,并且集群内的机器的配置也会比普通的客户端机器配置高,所以就不存在yarn-client模式的一些问题了,只不过这个时候查看日志只能到集群上面看了,这倒没什么影响。
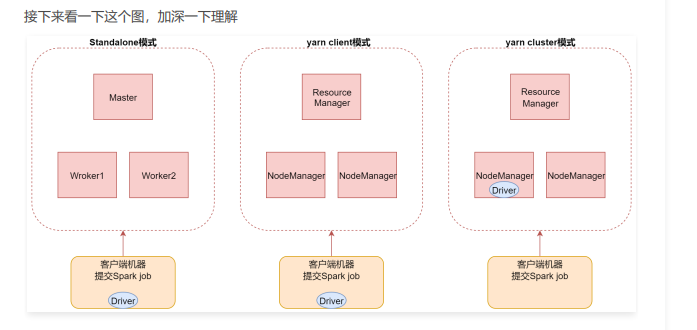
左边是standalone模式,现在我们使用的提交方式,driver进程是在客户端机器中的,其实针对standalone模式而言,这个Driver进程也是可以运行在集群中的,通过指定deploy-mode 为cluster即可
Shuffle机制分析
在MapReduce框架中,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,往往伴随着大量的磁盘和网络I/O。所以shuffle性能的高低也直接决定了整个程序的性能高低。Spark也会有自己的shuffle实现过程。
在Spark中,什么情况下,会发生shuffle?reduceByKey、groupByKey、sortByKey、countByKey、join等操作都会产生shuffle。
那下面我们来详细分析一下Spark中的shuffle过程。
Spark的shuffle历经了几个过程
- Spark 0.8及以前 使用Hash Based Shuffle
- Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制
- Spark1.6之后使用Sort-Base Shuffle,因为Hash Based Shuffle存在一些不足所以就把它替换掉了。
所以Spark Shuffle 一共经历了这几个过程:
- 未优化的 Hash Based Shuffle
- 优化后的Hash Based Shuffle
- Sort-Based Shuffle
未优化的Hash Based Shuffle
假设我们是在执行一个reduceByKey之类的操作,此时就会产生shuffle
shuffle里面会有两种task,一种是shuffleMapTask,负责拉取前一个RDD中的数据,还有一个ResultTask,负责把拉取到的数据按照规则汇总起来
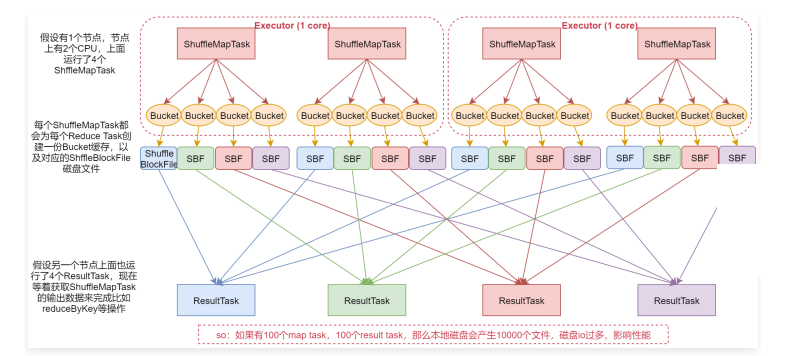
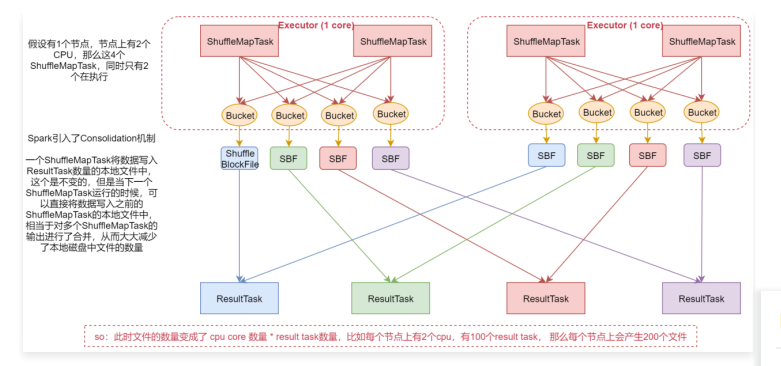
- 假设有1个节点,这个节点上有2个CPU,上面运行了4个ShuffleMapTask,这样的话其实同时只有2个ShuffleMapTask是并行执行的,因为一个cpu core同时只能执行一个ShuffleMapTask。
- 每个ShuffleMapTask都会为每个ResultTask创建一份Bucket缓存,以及对应的ShuffleBlockFile磁盘文件
这样的话,每一个ShuffleMapTask都会产生4份Bucket缓存和对应的4个ShuffleBlockFile文件。 - 假设另一个节点上面运行了4个ResultTask现在等着获取ShuffleMapTask的输出数据,来完成比如ReduceByKey的操作。
这是这个流程,注意了,如果有100个MapTask,100个ResultTask,那么会产生10000个本地磁盘文件,这样需要频繁的磁盘IO,是比较影响性能的。
注意,那个bucket缓存是非常重要的,ShuffleMapTask会把所有的数据都写入Bucket缓存之后,才会刷写到对应的磁盘文件中,但是这就有一个问题,如果map 端数据过多,那么很容易造成内存溢出,所以spark在优化后的Hash Based Shuffle中对这个问题进行了优化,默认这个内存缓存是100kb,当Bucket中的数据达到了阈值之后,就会将数据一点一点地刷写到对应的ShuffleBlockFile磁盘中了。
这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘io操作。所以,这里的内存缓存大小,是可以根据实际的业务情况进行优化的。
优化后的Hash Based Shuffle
看这个优化后的shuffle流程
- 假设机器上有2个cpu,4个shuffleMaptask,这样同时只有2个在并行执行
- 在这个版本中,Spark引入了consolidation机制,一个ShuffleMapTask将数据写入ResultTask数量的
本地文件中,这个是不变的,但是当下一个ShuffleMapTask运行的时候,可以直接将数据写入之前产生的本地文件中,相当于对多个ShuffleMapTask的输出进行了合并,从而大大减少了本地磁盘中文件的数量。
此时文件的数量变成了CPU core数量 * ResultTask数量,比如每个节点上有2个CPU,有100个ResultTask,那么每个节点上会产生200个文件,这个时候文件数量就变得少多了。
但是如果 ResultTask端的并行任务过多的话则 CPU core * Result Task 依旧过大,也会产生很多小文件
Sort-Based Shuffle
引入 Consolidation 机制虽然在一定程度上减少了磁盘文件数量,但是不足以有效提高 Shuffle 的性能,这种情况只适合中小型数据规模的数据处理。为了让 Spark 能在更大规模的集群上高性能处理大规模的数据,因此 Spark 引入了 Sort-Based Shuffle。
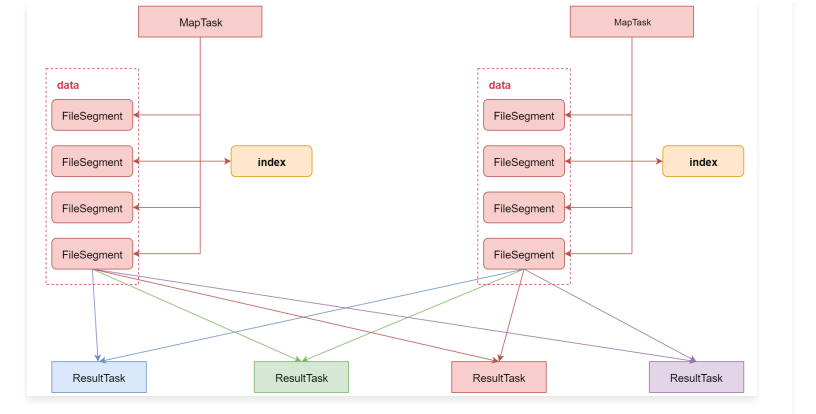
该机制针对每一个 ShuffleMapTask 都只创建一个文件,将所有的 ShuffleMapTask 的数据都写入同一个文件,并且对应生成一个索引文件。以前的数据是放在内存中,等到数据写完了再刷写到磁盘,现在为了减少内存的使用,在内存不够用的时候,可以将内存中的数据溢写到磁盘,结束的时候,再将这些溢写的文件联合内存中的数据一起进行归并,从而减少内存的使用量。一方面文件数量显著减少,另一方面减少缓存所占用的内存大小,而且同时避免 GC 的风险和频率。
checkpoint概述
checkpoint,是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而且,整个任务运行的时间也特别长,比如通常要运行1~2个小时。在这种情况下,就比较适合使用checkpoint功能了。
因为对于特别复杂的Spark任务,有很高的风险会出现某个要反复使用的RDD因为节点的故障导致丢失,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation算子,又要使用到该RDD时,就会发现数据丢失了,此时如果没有进行容错处理的话,那么就需要再重新计算一次数据了。
所以针对这种Spark Job,如果我们担心某些关键的,在后面会反复使用的RDD,因为节点故障导致数据丢失,那么可以针对该RDD启动checkpoint机制,实现容错和高可用
那如何使用checkPoint呢?
首先要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如HDFS;然后,对RDD调用checkpoint()方法。最后,在RDD所在的job运行结束之后,会启动一个单独的job,将checkpoint设置过的RDD的数据写入之前设置的文件系统中。
RDD之checkpoint流程
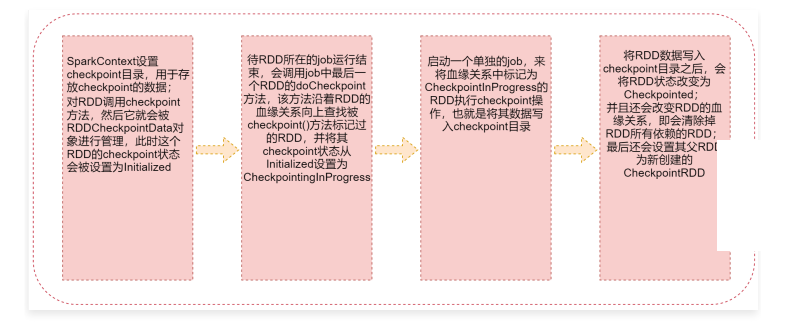
- SparkContext设置checkpoint目录,用于存放checkpoint的数据;对RDD调用checkpoint方法,然后它就会被RDDCheckpointData对象进行管理,此时这个RDD的checkpoint状态会被设置为Initialized
- 待RDD所在的job运行结束,会调用job中最后一个RDD的doCheckpoint方法,该方法沿着RDD的血缘 关 系 向 上 查 找 被 checkpoint() 方 法 标 记 过 的 RDD , 并 将 其 checkpoint 状 态 从 Initialized 设 置 为 CheckpointInProgress
- 启动一个单独的job,来将血缘关系中标记为CheckpointInProgress的RDD执行checkpoint操作,也就是将其数据写入checkpoint目录
- 将RDD数据写入checkpoint目录之后,会将RDD状态改变为Checkpointed;并且还会改变RDD的血缘关系,即会清除掉RDD所有依赖的RDD;最后还会设置其父RDD为新创建的CheckpointRDD
checkpoint与持久化的区别
- lineage是否发生改变,linage(血缘关系)说的就是RDD之间的依赖关系
持久化,只是将数据保存在内存中或者本地磁盘文件中,RDD的lineage(血缘关系)是不变的;
Checkpoint执行之后,RDD就没有依赖的RDD了,也就是它的lineage改变了 - 丢失数据的可能性
持久化的数据丢失的可能性较大,如果采用 persist 把数据存在内存中的话,虽然速度最快但是也是最不可靠的,就算放在磁盘上也不是完全可靠的,因为磁盘也会损坏。
Checkpoint的数据通常是保存在高可用文件系统中(HDFS),丢失的可能性很低
建议:对需要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)
为什么呢?
因为默认情况下,如果某个RDD没有持久化,但是设置了checkpoint,那么这个时候,本来Spark任务已经执行结束了,但是由于中间的RDD没有持久化,在进行checkpoint的时候想要将这个RDD的数据写入外部存储系统的话,就需要重新计算这个RDD的数据,再将其checkpoint到外部存储系统中。
如果对需要checkpoint的rdd进行了基于磁盘的持久化,那么后面进行checkpoint操作时,就会直接从磁盘上读取rdd的数据了,就不需要重新再计算一次了,这样效率就高了。
那在这能不能使用基于内存的持久化呢?当然是可以的,不过没那个必要。
checkPoint的使用
import org.apache.spark.{SparkConf, SparkContext}
/**
* 测试对checkpoint的使用
*/
object CheckPointOpScala {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CheckPointOpScala")
val sc = new SparkContext(conf)
sc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
if (args.length == 0) {
System.exit(100)
}
val outputPath = args(0)
//1:设置checkpint目录
sc.setCheckpointDir("hdfs://bigdata01:9000/chk001")
val dataRDD = sc.textFile("hdfs://bigdata01:9000/hello_1000000.dat")
//2:对rdd执行checkpoint操作
dataRDD.checkpoint()
dataRDD.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.saveAsTextFile(outputPath)
sc.stop()
}
}
把这个任务打包提交到集群上运行一下,看一下效果,测试数据需要提前上传到了hdfs上面,输出目录不能存在。
spark-submit \
--class com.imooc.bigdata.spark.CheckPointOpScala \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 1 \
bigdata-spark2.jar \
hdfs://bigdata01:9000/sparkout-chk001
执行成功之后可以到 setCheckpointDir 指定的目录中查看一下,可以看到目录中会生成对应的文件保存rdd中的数据,只不过生成的文件不是普通文本文件,直接查看文件中的内容显示为乱码。
checkpoint源码分析
下面我们就来分析一下RDD的checkpoint功能:
checkpoint功能可以分为两块
checkpoint的写操作
将指定RDD的数据通过checkpoint存储到指定外部存储中
- 当我们在自己开发的 spark 任务中先调用 sc.setCheckpointDir 时,底层其实就会调用SparkContext中的 setCheckpointDir 方法
- 接着我们会调用 RDD.checkpoint 方法,此时会执行RDD这个class中的 checkpoint 方法
这个checkpoint方法执行完成之后,这个流程就结束了。 - 剩下的就是在这个设置了checkpint的RDD所在的job执行结束之后,Spark会调用job中最后一个RDD的 doCheckpoint 方法。这个逻辑是在SparkContext这个class的runJob方法中,当执行到Spark中的action算子时,这个runJob方法会被触发,开始执行任务。这个runJob的最后一行会调用rdd中的 doCheckpoint 方法
- 接着会进入到RDD中的 doCheckpoint 方法
这里面最终会调用 RDDCheckpointData 的 checkpoint 方法
checkpointData.get.checkpoint() - 接下来进入到 RDDCheckpointData 的 checkpoint 方法中
这里面会调用子类 ReliableCheckpointRDD 中的 doCheckpoint() 方法 - 接着来进入 ReliableCheckpointRDD 中的 doCheckpoint() 方法
这里面会调用 ReliableCheckpointRDD 中的 writeRDDToCheckpointDirectory 方法将rdd的数据写入HDFS中的 checkpoint 目录,并且返回创建的 CheckpointRDD - 接下来进入 ReliableCheckpointRDD 的 writeRDDToCheckpointDirectory 方法
这里面最终会启动一个job,将checkpoint的数据写入到指定的HDFS目录中
执行到这,其实调用过checkpoint方法的RDD就被保存到HDFS上了。
checkpoint的读操作
任务中RDD数据在使用过程中丢失了,正好这个RDD之前做过checkpoint,所以这时就需要通过checkpoint来恢复数据
-
这个时候还是会执行RDD中的iterator方法
由于我们没有做持久化,只做了checkpoint,所以还是会走 else -
进入 computeOrReadCheckpoint 方法
此时rdd已经 checkpoint 并且物化,所以 if 分支满足
执行 firstParent[T].iterator(split, context) 这行代码
这行代码的意思是会找到当前这个RDD的父RDD,其实这个RDD执行过checkpoint之后,血缘关系已经被切断了,它的父RDD就是我们前面创建的那个 ReliableCheckpointRDD这个 ReliableCheckpointRDD 中没有覆盖 iterator 方法,所以在调用 iterator 的时候还是执行RDD这个父类中的 iterator ,重新进来之后再判断,这个 ReliableCheckpointRDD 再执行if判断的时候就不满足了,因为它的 checkpoint 属性不满足,所以会走 else ,执行 compute -
此时会执行 ReliableCheckpointRDD 这个子类中的 compute 方法,这里面就会找到之前checkpoint的文件,从HDFS上恢复RDD中的数据
这是从checkpoint中读取数据的流程
我们前面说过,建议对需要做checkpoint的数据先进行持久化,如果我们设置了持久化,针对checkpoint的写操作,在执行iterator方法的时候会是什么现象呢?
此时在最后将RDD中的数据通过checkpoint存储到HDFS上的时候,会调用RDD的iterator方法,不过此时 storageLevel 就不为 null 了,因为我们对这个RDD做了基于磁盘的持久化,所以会走 if 分支,执行getOrCompute

 浙公网安备 33010602011771号
浙公网安备 33010602011771号